
Post-training quantization is a conversion technique that can reduce model size while also improving CPU and hardware accelerator latency, with little degradation in model accuracy. You can quantize an already-trained float TensorFlow model when you convert it to LiteRT format using the LiteRT Converter.
Optimization Methods
There are several post-training quantization options to choose from. Here is a summary table of the choices and the benefits they provide:
| Technique | Benefits | Hardware |
|---|---|---|
| Dynamic range quantization | 4x smaller, 2x-3x speedup | CPU |
| Full integer quantization | 4x smaller, 3x+ speedup | CPU, Edge TPU, Microcontrollers |
| Float16 quantization | 2x smaller, GPU acceleration | CPU, GPU |
The following decision tree can help determine which post-training quantization method is best for your use case:
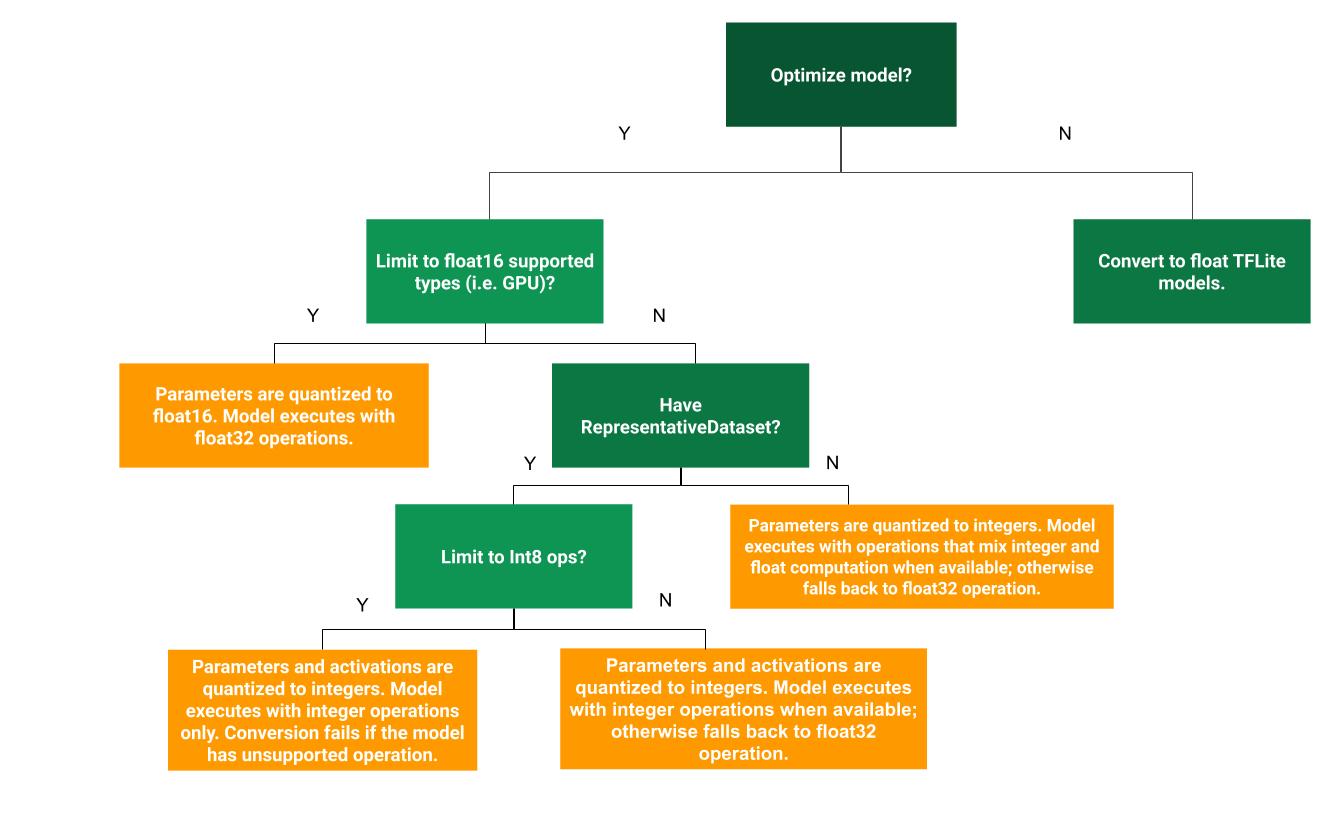
No Quantization
Converting to a TFLite model without quantization is a recommended starting point. This will generate a float TFLite model.
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) tflite_quant_model = converter.convert()
We recommend that you do this as an initial step to verify that the original TF model's operators are compatible with TFLite and can also be used as a baseline to debug quantization errors introduced by subsequent post-training quantization methods. For example, if a quantized TFLite model produces unexpected results, while the float TFLite model is accurate, we can narrow down the issue to errors introduced by the quantized version of the TFLite operators.
Dynamic range quantization
Dynamic range quantization provides reduced memory usage and faster computation without you having to provide a representative dataset for calibration. This type of quantization, statically quantizes only the weights from floating point to integer at conversion time, which provides 8-bits of precision:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] tflite_quant_model = converter.convert()
To further reduce latency during inference, "dynamic-range" operators dynamically quantize activations based on their range to 8-bits and perform computations with 8-bit weights and activations. This optimization provides latencies close to fully fixed-point inferences. However, the outputs are still stored using floating point so the increased speed of dynamic-range ops is less than a full fixed-point computation.
Full integer quantization
You can get further latency improvements, reductions in peak memory usage, and compatibility with integer only hardware devices or accelerators by making sure all model math is integer quantized.
For full integer quantization, you need to calibrate or estimate the range,
i.e., (min, max) of all floating-point tensors in the model. Unlike constant
tensors such as weights and biases, variable tensors such as model input,
activations (outputs of intermediate layers) and model output cannot be
calibrated unless we run a few inference cycles. As a result, the converter
requires a representative dataset to calibrate them. This dataset can be a small
subset (around ~100-500 samples) of the training or validation data. Refer to
the representative_dataset() function below.
From TensorFlow 2.7 version, you can specify the representative dataset through a signature as the following example:
def representative_dataset():
for data in dataset:
yield {
"image": data.image,
"bias": data.bias,
}
If there are more than one signature in the given TensorFlow model, you can specify the multiple dataset by specifying the signature keys:
def representative_dataset():
# Feed data set for the "encode" signature.
for data in encode_signature_dataset:
yield (
"encode", {
"image": data.image,
"bias": data.bias,
}
)
# Feed data set for the "decode" signature.
for data in decode_signature_dataset:
yield (
"decode", {
"image": data.image,
"hint": data.hint,
},
)
You can generate the representative dataset by providing an input tensor list:
def representative_dataset():
for data in tf.data.Dataset.from_tensor_slices((images)).batch(1).take(100):
yield [tf.dtypes.cast(data, tf.float32)]
Since TensorFlow 2.7 version, we recommend using the signature-based approach over the input tensor list-based approach because the input tensor ordering can be easily flipped.
For testing purposes, you can use a dummy dataset as follows:
def representative_dataset():
for _ in range(100):
data = np.random.rand(1, 244, 244, 3)
yield [data.astype(np.float32)]
Integer with float fallback (using default float input/output)
In order to fully integer quantize a model, but use float operators when they don't have an integer implementation (to ensure conversion occurs smoothly), use the following steps:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.representative_dataset = representative_dataset tflite_quant_model = converter.convert()
Integer only
Creating integer only models is a common use case for LiteRT for Microcontrollers and Coral Edge TPUs.
Additionally, to ensure compatibility with integer only devices (such as 8-bit microcontrollers) and accelerators (such as the Coral Edge TPU), you can enforce full integer quantization for all ops including the input and output, by using the following steps:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.representative_dataset = representative_dataset converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8] converter.inference_input_type = tf.int8 # or tf.uint8 converter.inference_output_type = tf.int8 # or tf.uint8 tflite_quant_model = converter.convert()
Float16 quantization
You can reduce the size of a floating point model by quantizing the weights to float16, the IEEE standard for 16-bit floating point numbers. To enable float16 quantization of weights, use the following steps:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.target_spec.supported_types = [tf.float16] tflite_quant_model = converter.convert()
The advantages of float16 quantization are as follows:
- It reduces model size by up to half (since all weights become half of their original size).
- It causes minimal loss in accuracy.
- It supports some delegates (e.g. the GPU delegate) which can operate directly on float16 data, resulting in faster execution than float32 computations.
The disadvantages of float16 quantization are as follows:
- It does not reduce latency as much as a quantization to fixed point math.
- By default, a float16 quantized model will "dequantize" the weights values to float32 when run on the CPU. (Note that the GPU delegate will not perform this dequantization, since it can operate on float16 data.)
Integer only: 16-bit activations with 8-bit weights (experimental)
This is an experimental quantization scheme. It is similar to the "integer only" scheme, but activations are quantized based on their range to 16-bits, weights are quantized in 8-bit integer and bias is quantized into 64-bit integer. This is referred to as 16x8 quantization further.
The main advantage of this quantization is that it can improve accuracy significantly, but only slightly increase model size.
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.representative_dataset = representative_dataset converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.target_spec.supported_ops = [tf.lite.OpsSet.EXPERIMENTAL_TFLITE_BUILTINS_ACTIVATIONS_INT16_WEIGHTS_INT8] tflite_quant_model = converter.convert()
If 16x8 quantization is not supported for some operators in the model, then the model still can be quantized, but unsupported operators kept in float. The following option should be added to the target_spec to allow this.
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.representative_dataset = representative_dataset converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.target_spec.supported_ops = [tf.lite.OpsSet.EXPERIMENTAL_TFLITE_BUILTINS_ACTIVATIONS_INT16_WEIGHTS_INT8, tf.lite.OpsSet.TFLITE_BUILTINS] tflite_quant_model = converter.convert()
Examples of the use cases where accuracy improvements provided by this quantization scheme include:
- super-resolution,
- audio signal processing such as noise cancelling and beamforming,
- image de-noising,
- HDR reconstruction from a single image.
The disadvantage of this quantization is:
- Currently inference is noticeably slower than 8-bit full integer due to the lack of optimized kernel implementation.
- Currently it is incompatible with the existing hardware accelerated TFLite delegates.
A tutorial for this quantization mode can be found here.
Model accuracy
Since weights are quantized post training, there could be an accuracy loss, particularly for smaller networks. Pre-trained fully quantized models are provided for specific networks on Kaggle Models . It is important to check the accuracy of the quantized model to verify that any degradation in accuracy is within acceptable limits. There are tools to evaluate LiteRT model accuracy.
Alternatively, if the accuracy drop is too high, consider using quantization aware training . However, doing so requires modifications during model training to add fake quantization nodes, whereas the post-training quantization techniques on this page use an existing pre-trained model.
Representation for quantized tensors
8-bit quantization approximates floating point values using the following formula.
\[real\_value = (int8\_value - zero\_point) \times scale\]
The representation has two main parts:
Per-axis (aka per-channel) or per-tensor weights represented by int8 two’s complement values in the range [-127, 127] with zero-point equal to 0.
Per-tensor activations/inputs represented by int8 two’s complement values in the range [-128, 127], with a zero-point in range [-128, 127].
For a detailed view of our quantization scheme, please see our quantization spec. Hardware vendors who want to plug into TensorFlow Lite's delegate interface are encouraged to implement the quantization scheme described there.