
總覽
本頁說明將 TensorFlow 中的複合運算轉換為 LiteRT 中的融合運算時,所需的設計和步驟。這項基礎架構用途廣泛,支援將 TensorFlow 中的任何複合運算轉換為 LiteRT 中對應的融合運算。
TensorFlow RNN 作業融合至 LiteRT 就是這項基礎架構的用途範例,詳情請參閱這篇文章。
什麼是融合運算

TensorFlow 作業可以是原始作業 (例如 tf.add),也可以由其他原始作業組成 (例如 tf.einsum)。原始作業會在 TensorFlow 圖形中顯示為單一節點,而複合作業則是 TensorFlow 圖形中的節點集合。執行複合作業等同於執行每個構成的原始作業。
融合作業對應於單一作業,其中包含對應複合作業中每個原始作業執行的所有運算。
融合作業的優點
融合作業的目的是盡可能提升基礎核心實作的效能,方法是最佳化整體運算並減少記憶體用量。這項功能非常實用,特別是對於低延遲推論工作負載和資源受限的行動平台。
融合作業也提供更高層級的介面,可定義複雜的轉換 (例如量化),否則在更精細的層級會難以或無法完成。
如上所述,LiteRT 有許多融合作業的執行個體。這些融合作業通常對應於來源 TensorFlow 程式中的複合作業。在 TensorFlow 中,以 LiteRT 單一融合運算實作的複合運算範例包括各種 RNN 運算,例如單向和雙向序列 LSTM、捲積 (conv2d、偏誤加法、relu)、全連接 (matmul、偏誤加法、relu) 等。在 LiteRT 中,LSTM 量化目前僅在融合 LSTM 作業中實作。
融合作業的相關挑戰
將複合運算從 TensorFlow 轉換為 LiteRT 中的融合運算,是個難題。可能的原因如下:
複合作業在 TensorFlow 圖中會以一組原始作業表示,沒有明確定義的界線。識別對應這類複合作業的子圖 (例如透過模式比對) 可能非常困難。
針對融合的 LiteRT 作業,可能有多個 TensorFlow 實作項目。舉例來說,TensorFlow 中有許多 LSTM 實作 (Keras、Babelfish/lingvo 等),這些實作是由不同的原始運算組成,但全都可以轉換為 LiteRT 中的相同融合 LSTM 運算。
因此,融合作業的轉換相當困難。
將複合運算子轉換為 TFLite 自訂運算 (建議)
將複合運算包裝在 tf.function 中
在許多情況下,模型的部分內容可以對應至 TFLite 中的單一作業。針對特定作業編寫最佳化實作項目時,這項功能有助於提升效能。如要在 TFLite 中建立融合作業,請找出代表融合作業的圖表部分,並使用「experimental_implements」屬性將其包裝在 tf.function 中,並將該屬性設為 tf.function,其中包含屬性值為 tfl_fusable_op 的屬性,且值為 true。如果自訂作業需要屬性,請將屬性當做同一個「experimental_implements」的一部分傳遞。
例如:
def get_implements_signature():
implements_signature = [
# 'name' will be used as a name for the operation.
'name: "my_custom_fused_op"',
# attr "tfl_fusable_op" is required to be set with true value.
'attr {key: "tfl_fusable_op" value { b: true } }',
# Example attribute "example_option" that the op accepts.
'attr {key: "example_option" value { i: %d } }' % 10
]
return ' '.join(implements_signature)
@tf.function(experimental_implements=get_implements_signature())
def my_custom_fused_op(input_1, input_2):
# An empty function that represents pre/post processing example that
# is not represented as part of the Tensorflow graph.
output_1 = tf.constant(0.0, dtype=tf.float32, name='first_output')
output_2 = tf.constant(0.0, dtype=tf.float32, name='second_output')
return output_1, output_2
class TestModel(tf.Module):
def __init__(self):
super(TestModel, self).__init__()
self.conv_1 = tf.keras.layers.Conv2D(filters=1, kernel_size=(3, 3))
self.conv_2 = tf.keras.layers.Conv2D(filters=1, kernel_size=(3, 3))
@tf.function(input_signature=[
tf.TensorSpec(shape=[1, 28, 28, 3], dtype=tf.float32),
tf.TensorSpec(shape=[1, 28, 28, 3], dtype=tf.float32),
])
def simple_eval(self, input_a, input_b):
return my_custom_fused_op(self.conv_1(input_a), self.conv_2(input_b))
請注意,您不必在轉換器上設定 allow_custom_ops,因為 tfl_fusable_op 屬性已隱含這項設定。
實作自訂運算並向 TFLite 解譯器註冊
將融合運算實作為 TFLite 自訂運算 - 請參閱操作說明。
請注意,用來註冊運算的名稱應與實作簽章中 name 屬性指定的名稱類似。
範例中的 op 範例為
TfLiteRegistration reg = {};
// This name must match the name specified in the implements signature.
static constexpr char kOpName[] = "my_custom_fused_op";
reg.custom_name = kOpName;
reg.prepare = [](TfLiteContext* context, TfLiteNode* node) -> TfLiteStatus {
// Add your code.
return kTfLiteOk;
};
reg.invoke = [](TfLiteContext* context, TfLiteNode* node) -> TfLiteStatus {
// Add your code.
return kTfLiteOk;
};
reg.builtin_code = kTfLiteCustom;
resolver->AddCustom(kOpName, ®);
從複合運算轉換為融合運算 (進階)
將 TensorFlow 複合運算轉換為 LiteRT 融合運算的整體架構如下:
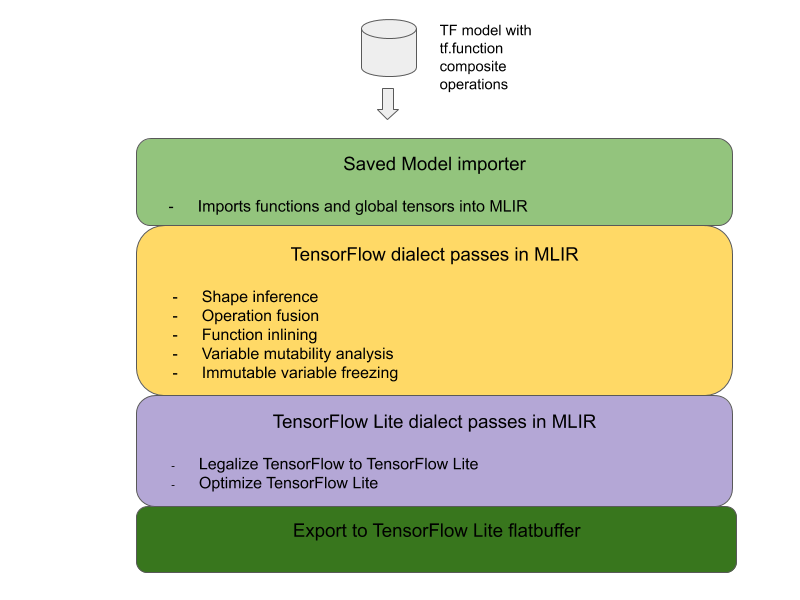
將複合運算包裝在 tf.function 中
在 TensorFlow 模型原始碼中,找出複合運算並抽象化為 tf.function,並使用 experimental_implements 函式註解。請參閱嵌入式查詢範例。函式會定義介面,而其引數應可用於實作轉換邏輯。
編寫轉換程式碼
轉換程式碼是根據函式的介面和 implements 註解編寫。請參閱嵌入式查閱的融合範例。從概念上來說,轉換程式碼會以融合式實作項目,取代這個介面的複合式實作項目。
在 prepare-composite-functions 傳遞中,外掛程式會插入轉換程式碼。
在更進階的用法中,您可以實作複合運算的運算元複雜轉換,藉此衍生融合運算的運算元。請參閱 Keras LSTM 轉換程式碼範例。
轉換為 LiteRT
使用 TFLiteConverter.from_saved_model API 轉換為 LiteRT。
深入解析
我們現在說明轉換為 LiteRT 中融合作業的整體設計高階詳細資料。
在 TensorFlow 中撰寫運算
使用 tf.function 和 experimental_implements 函式屬性,使用者就能使用 TensorFlow 原始作業明確編寫新作業,並指定產生的複合作業實作的介面。這項功能非常實用,因為它提供:
- 基礎 TensorFlow 圖形中複合運算的明確定義界線。
- 明確指定這項作業實作的介面。tf.function 的引數對應於這個介面的引數。
舉例來說,假設我們定義了複合作業,用於實作嵌入式搜尋。這會對應至 LiteRT 中的融合作業。
@tf.function(
experimental_implements="embedding_lookup")
def EmbFprop(embs, ids_vec):
"""Embedding forward prop.
Effectively, it computes:
num = size of ids_vec
rets = zeros([num, embedding dim])
for i in range(num):
rets[i, :] = embs[ids_vec[i], :]
return rets
Args:
embs: The embedding matrix.
ids_vec: A vector of int32 embedding ids.
Returns:
The result of embedding lookups. A matrix of shape
[num ids in ids_vec, embedding dims].
"""
num = tf.shape(ids_vec)[0]
rets = inplace_ops.empty([num] + emb_shape_suf, py_utils.FPropDtype(p))
def EmbFpropLoop(i, embs, ids_vec, rets):
# row_id = ids_vec[i]
row_id = tf.gather(ids_vec, i)
# row = embs[row_id]
row = tf.reshape(tf.gather(embs, row_id), [1] + emb_shape_suf)
# rets[i] = row
rets = inplace_ops.alias_inplace_update(rets, [i], row)
return embs, ids_vec, rets
_, _, rets = functional_ops.For(
start=0,
limit=num,
delta=1,
inputs=[embs, ids_vec, rets],
body=EmbFpropLoop,
rewrite_with_while=compiled)
if len(weight_shape) > 2:
rets = tf.reshape(rets, [num, symbolic.ToStatic(p.embedding_dim)])
return rets
如上圖所示,讓模型透過 tf.function 使用複合運算,即可建構一般基礎架構,識別這類運算並轉換為融合的 LiteRT 運算。
擴充 LiteRT 轉換器
今年稍早發布的 LiteRT 轉換工具僅支援將 TensorFlow 模型匯入為圖表,並將所有變數替換為對應的常數值。由於這類圖表的所有函式都已內嵌,因此變數可以轉換為常數,這不適用於運算元融合。
如要在轉換過程中搭配 experimental_implements 功能使用 tf.function,必須保留函式,直到轉換過程的後續階段。
因此,我們在轉換器中導入了匯入及轉換 TensorFlow 模型的新工作流程,以支援複合運算子融合的使用情境。具體來說,新增功能如下:
- 將 TensorFlow 儲存的模型匯入 MLIR
- 融合複合作業
- 變數可變動性分析
- 凍結所有唯讀變數
這樣我們就能在函式內嵌和變數凍結之前,使用代表複合作業的函式執行作業融合。
實作運算融合
讓我們進一步瞭解作業融合階段。這張票證具有以下功能:
- 在 MLIR 模組中,逐一檢查所有函式。
- 如果函式具有 tf._implements 屬性,系統會根據屬性值呼叫適當的運算元融合公用程式。
- 作業融合公用程式會對函式的運算元和屬性 (做為轉換的介面) 執行作業,並以包含融合作業的對等函式主體,取代函式的主體。
- 在許多情況下,取代的主體會包含融合運算以外的運算。這些對應於函式運算元上的一些靜態轉換,目的是取得融合作業的運算元。由於這些計算作業都可以摺疊成常數,因此匯出的 FlatBuffer 中不會出現這些作業,只會存在融合作業。
以下是傳遞中的程式碼片段,顯示主要工作流程:
void PrepareCompositeFunctionsPass::ConvertTFImplements(FuncOp func,
StringAttr attr) {
if (attr.getValue() == "embedding_lookup") {
func.eraseBody();
func.addEntryBlock();
// Convert the composite embedding_lookup function body to a
// TFLite fused embedding_lookup op.
ConvertEmbeddedLookupFunc convert_embedded_lookup(func);
if (failed(convert_embedded_lookup.VerifySignature())) {
return signalPassFailure();
}
convert_embedded_lookup.RewriteFunc();
} else if (attr.getValue() == mlir::TFL::kKerasLstm) {
func.eraseBody();
func.addEntryBlock();
OpBuilder builder(func.getBody());
if (failed(ConvertKerasLSTMLayer(func, &builder))) {
return signalPassFailure();
}
} else if (.....) /* Other fusions can plug in here */
}
以下程式碼片段顯示如何利用函式做為轉換介面,將這項複合作業對應至 LiteRT 中的融合作業。
void RewriteFunc() {
Value lookup = func_.getArgument(1);
Value value = func_.getArgument(0);
auto output_type = func_.getType().getResult(0);
OpBuilder builder(func_.getBody());
auto op = builder.create<mlir::TFL::EmbeddingLookupOp>(
func_.getLoc(), output_type, lookup, value);
builder.create<mlir::ReturnOp>(func_.getLoc(), op.getResult());
}