
खास जानकारी
इस पेज पर, TensorFlow में कंपोज़िट ऑपरेशंस को LiteRT में फ़्यूज़ किए गए ऑपरेशंस में बदलने के लिए ज़रूरी डिज़ाइन और चरणों के बारे में बताया गया है. यह इन्फ़्रास्ट्रक्चर, सामान्य मकसद के लिए है. साथ ही, यह TensorFlow में मौजूद किसी भी कंपोज़िट ऑपरेशन को LiteRT में मौजूद फ़्यूज़ किए गए ऑपरेशन में बदलने की सुविधा देता है.
इस इन्फ़्रास्ट्रक्चर का इस्तेमाल, TensorFlow RNN ऑपरेशन फ़्यूज़न को LiteRT में बदलने के लिए किया जाता है. इसके बारे में यहां ज़्यादा जानकारी दी गई है.
फ़्यूज़ किए गए ऑपरेशन क्या होते हैं

TensorFlow ऑपरेशंस, प्रिमिटिव ऑप्स हो सकते हैं. जैसे, tf.add. इसके अलावा, इन्हें अन्य प्रिमिटिव ऑपरेशंस से भी बनाया जा सकता है. जैसे, tf.einsum. प्रिमिटिव ऑपरेशन, TensorFlow ग्राफ़ में एक नोड के तौर पर दिखता है. वहीं, कंपोज़िट ऑपरेशन, TensorFlow ग्राफ़ में नोड का कलेक्शन होता है. कंपोज़िट ऑपरेशन को लागू करना, उसके हर प्रिमिटिव ऑपरेशन को लागू करने के बराबर होता है.
फ़्यूज़ किए गए ऑपरेशन का मतलब ऐसे ऑपरेशन से है जिसमें सभी कंपोज़िट ऑपरेशन के अंदर मौजूद हर प्रिमिटिव ऑपरेशन की कंप्यूटिंग शामिल होती है.
फ़्यूज़ किए गए ऑपरेशनों के फ़ायदे
फ़्यूज़ किए गए ऑपरेशन, अपने कर्नेल के बुनियादी सिद्धांतों को लागू करने की परफ़ॉर्मेंस को बेहतर बनाने के लिए मौजूद होते हैं. इसके लिए, वे कुल कंप्यूटेशन को ऑप्टिमाइज़ करते हैं और मेमोरी फ़ुटप्रिंट को कम करते हैं. यह बहुत काम का है. खास तौर पर, कम समय में नतीजे देने वाले इन्फ़्रेंस वर्कलोड और सीमित संसाधनों वाले मोबाइल प्लैटफ़ॉर्म के लिए.
फ़्यूज़ किए गए ऑपरेशन, क्वांटाइज़ेशन जैसे मुश्किल ट्रांसफ़ॉर्मेशन को तय करने के लिए, ज़्यादा बेहतर इंटरफ़ेस भी उपलब्ध कराते हैं. ऐसा न होने पर, ज़्यादा बारीकी से काम करना मुश्किल हो जाता है.
ऊपर बताई गई वजहों से, LiteRT में फ़्यूज़ किए गए कई ऑपरेशन होते हैं. आम तौर पर, फ़्यूज़ किए गए ये ऑपरेशन, सोर्स TensorFlow प्रोग्राम में कंपोज़िट ऑपरेशन से मेल खाते हैं. TensorFlow में कंपोज़िट ऑपरेशंस के उदाहरणों में, कई आरएनएन ऑपरेशंस शामिल हैं. जैसे, यूनिडायरेक्शनल और बिडायरेक्शनल सीक्वेंस एलएसटीएम, कनवोल्यूशन (conv2d, bias add, relu), फ़ुली कनेक्टेड (matmul, bias add, relu) वगैरह. इन्हें LiteRT में एक ही फ़्यूज़ किए गए ऑपरेशन के तौर पर लागू किया जाता है. LiteRT में, फ़िलहाल LSTM क्वांटाइज़ेशन को सिर्फ़ फ़्यूज़ किए गए LSTM ऑपरेशनों में लागू किया गया है.
फ़्यूज़ किए गए ऑपरेशंस से जुड़ी समस्याएं
TensorFlow की कंपोज़िट कार्रवाइयों को LiteRT में फ़्यूज़ की गई कार्रवाइयों में बदलना एक मुश्किल काम है. ऐसा इसलिए होता है, क्योंकि:
कंपोज़िट ऑपरेशनों को TensorFlow ग्राफ़ में, प्रिमिटिव ऑपरेशनों के सेट के तौर पर दिखाया जाता है. इनकी सीमा तय नहीं होती. इस तरह के कंपोज़िट ऑपरेशन से जुड़े सब-ग्राफ़ की पहचान करना बहुत मुश्किल हो सकता है. उदाहरण के लिए, पैटर्न मैचिंग के ज़रिए.
ऐसा हो सकता है कि फ़्यूज़ की गई LiteRT कार्रवाई को टारगेट करने के लिए, एक से ज़्यादा TensorFlow लागू किए गए हों. उदाहरण के लिए, TensorFlow (Keras, Babelfish/lingvo वगैरह) में कई एलएसटीएम लागू किए गए हैं. इनमें से हर एक में अलग-अलग प्रिमिटिव ऑपरेशन शामिल हैं. हालांकि, इन सभी को LiteRT में एक ही फ़्यूज़ किए गए एलएसटीएम ऑपरेशन में बदला जा सकता है.
इसलिए, फ़्यूज़ की गई कार्रवाइयों को बदलना काफ़ी मुश्किल साबित हुआ है.
कंपोज़िट ऑप से टीएफ़लाइट कस्टम ऑपरेशन में बदलना (सुझाया गया)
कॉम्पोज़िट ऑपरेशन को tf.function में रैप करें
कई मामलों में, मॉडल के कुछ हिस्से को TFLite में मौजूद किसी एक ऑपरेशन पर मैप किया जा सकता है. इससे कुछ खास कार्रवाइयों के लिए, ऑप्टिमाइज़ किया गया कोड लिखने पर परफ़ॉर्मेंस को बेहतर बनाने में मदद मिल सकती है. TFLite में फ़्यूज़ किया गया ऑपरेशन बनाने के लिए,
ग्राफ़ के उस हिस्से की पहचान करें जो फ़्यूज़ किए गए ऑपरेशन को दिखाता है. इसके बाद, उसे tf.function में रैप करें. साथ ही, tf.function के "experimental_implements" एट्रिब्यूट को tfl_fusable_op एट्रिब्यूट वैल्यू true के साथ जोड़ें. अगर कस्टम ऑपरेशन में एट्रिब्यूट इस्तेमाल किए जाते हैं, तो उन्हें "experimental_implements" के हिस्से के तौर पर पास करें.
उदाहरण के लिए,
def get_implements_signature():
implements_signature = [
# 'name' will be used as a name for the operation.
'name: "my_custom_fused_op"',
# attr "tfl_fusable_op" is required to be set with true value.
'attr {key: "tfl_fusable_op" value { b: true } }',
# Example attribute "example_option" that the op accepts.
'attr {key: "example_option" value { i: %d } }' % 10
]
return ' '.join(implements_signature)
@tf.function(experimental_implements=get_implements_signature())
def my_custom_fused_op(input_1, input_2):
# An empty function that represents pre/post processing example that
# is not represented as part of the Tensorflow graph.
output_1 = tf.constant(0.0, dtype=tf.float32, name='first_output')
output_2 = tf.constant(0.0, dtype=tf.float32, name='second_output')
return output_1, output_2
class TestModel(tf.Module):
def __init__(self):
super(TestModel, self).__init__()
self.conv_1 = tf.keras.layers.Conv2D(filters=1, kernel_size=(3, 3))
self.conv_2 = tf.keras.layers.Conv2D(filters=1, kernel_size=(3, 3))
@tf.function(input_signature=[
tf.TensorSpec(shape=[1, 28, 28, 3], dtype=tf.float32),
tf.TensorSpec(shape=[1, 28, 28, 3], dtype=tf.float32),
])
def simple_eval(self, input_a, input_b):
return my_custom_fused_op(self.conv_1(input_a), self.conv_2(input_b))
ध्यान दें कि आपको कनवर्टर पर allow_custom_ops सेट करने की ज़रूरत नहीं है, क्योंकि tfl_fusable_op एट्रिब्यूट से यह जानकारी पहले ही मिल जाती है.
कस्टम ऑप लागू करना और उसे TFLite इंटरप्रेटर के साथ रजिस्टर करना
फ़्यूज़ किए गए ऑपरेशन को TFLite कस्टम ऑपरेशन के तौर पर लागू करें. इसके लिए, निर्देश देखें.
ध्यान दें कि ओप को रजिस्टर करने के लिए इस्तेमाल किया गया नाम, implements signature में name एट्रिब्यूट में दिए गए नाम से मिलता-जुलता होना चाहिए.
उदाहरण में दिए गए ऑप का उदाहरण यह है
TfLiteRegistration reg = {};
// This name must match the name specified in the implements signature.
static constexpr char kOpName[] = "my_custom_fused_op";
reg.custom_name = kOpName;
reg.prepare = [](TfLiteContext* context, TfLiteNode* node) -> TfLiteStatus {
// Add your code.
return kTfLiteOk;
};
reg.invoke = [](TfLiteContext* context, TfLiteNode* node) -> TfLiteStatus {
// Add your code.
return kTfLiteOk;
};
reg.builtin_code = kTfLiteCustom;
resolver->AddCustom(kOpName, ®);
कंपोज़िट ऑपरेशन को फ़्यूज़्ड ऑपरेशन में बदलना (ऐडवांस)
TensorFlow कंपोज़िट ऑपरेशंस को LiteRT फ़्यूज़्ड ऑपरेशंस में बदलने का पूरा आर्किटेक्चर यहां दिया गया है:
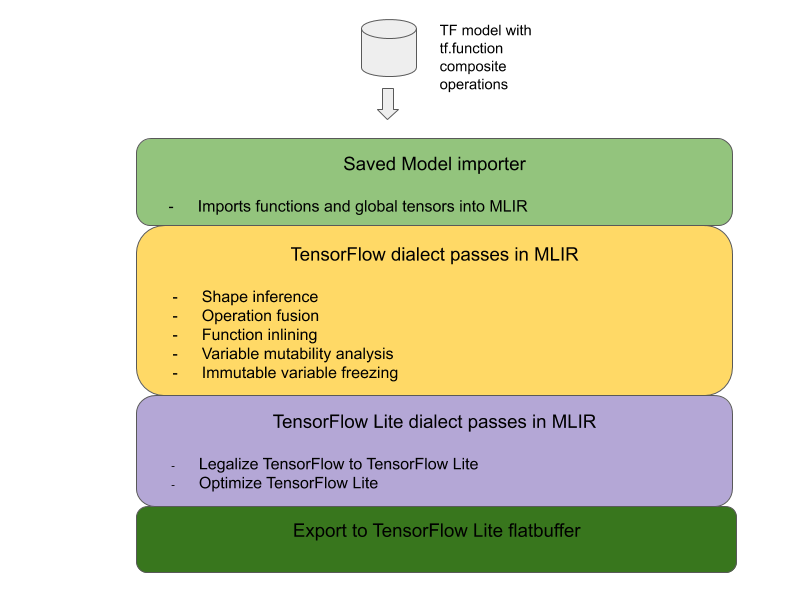
कॉम्पोज़िट ऑपरेशन को tf.function में रैप करें
TensorFlow मॉडल के सोर्स कोड में, कंपोज़िट ऑपरेशन की पहचान करें और उसे tf.function में अलग करें. साथ ही, experimental_implements फ़ंक्शन एनोटेशन का इस्तेमाल करें. एम्बेड किए गए लुकअप का उदाहरण देखें. यह फ़ंक्शन, इंटरफ़ेस को तय करता है. साथ ही, इसके आर्ग्युमेंट का इस्तेमाल कन्वर्ज़न लॉजिक को लागू करने के लिए किया जाना चाहिए.
कन्वर्ज़न कोड लिखना
कन्वर्ज़न कोड को फ़ंक्शन के इंटरफ़ेस के हिसाब से लिखा जाता है. साथ ही, इसमें implements एनोटेशन का इस्तेमाल किया जाता है. एम्बेड किए गए लुकअप के लिए, फ़्यूज़न का उदाहरण देखें. सैद्धांतिक तौर पर, कन्वर्ज़न कोड इस इंटरफ़ेस के कंपोज़िट को फ़्यूज़ किए गए इंटरफ़ेस से बदल देता है.
prepare-composite-functions पास में, अपना कन्वर्ज़न कोड प्लगिन करें.
ज़्यादा बेहतर इस्तेमाल के लिए, कंपोज़िट ऑपरेशन के ऑपरेंड में जटिल बदलाव किए जा सकते हैं, ताकि फ़्यूज़ किए गए ऑपरेशन के ऑपरेंड बनाए जा सकें. उदाहरण के तौर पर, Keras LSTM का कन्वर्ज़न कोड देखें.
LiteRT में बदलना
LiteRT में बदलने के लिए, TFLiteConverter.from_saved_model एपीआई का इस्तेमाल करें.
बारीकियों के बारे में जानें
अब हम LiteRT में फ़्यूज़ किए गए ऑपरेशंस में बदलने के लिए, पूरे डिज़ाइन की अहम जानकारी के बारे में बताते हैं.
TensorFlow में कंपोज़िंग ऑपरेशन
tf.function का इस्तेमाल करने पर, experimental_implements फ़ंक्शन एट्रिब्यूट के साथ, उपयोगकर्ता TensorFlow की बुनियादी कार्रवाइयों का इस्तेमाल करके नई कार्रवाइयां साफ़ तौर पर कंपोज़ कर सकते हैं. साथ ही, वे उस इंटरफ़ेस के बारे में बता सकते हैं जिसे कंपोज़िट ऑपरेशन लागू करता है. यह बहुत काम का है, क्योंकि इससे ये फ़ायदे मिलते हैं:
- नीचे दिए गए TensorFlow ग्राफ़ में, कंपोज़िट ऑपरेशन के लिए तय की गई सीमा.
- उस इंटरफ़ेस के बारे में साफ़ तौर पर बताएं जिसे यह ऑपरेशन लागू करता है. tf.function के तर्क, इस इंटरफ़ेस के तर्कों से मेल खाते हैं.
उदाहरण के लिए, एम्बेडिंग लुकअप लागू करने के लिए तय किए गए कंपोज़िट ऑपरेशन पर विचार करें. यह LiteRT में फ़्यूज़ किए गए ऑपरेशन पर मैप करता है.
@tf.function(
experimental_implements="embedding_lookup")
def EmbFprop(embs, ids_vec):
"""Embedding forward prop.
Effectively, it computes:
num = size of ids_vec
rets = zeros([num, embedding dim])
for i in range(num):
rets[i, :] = embs[ids_vec[i], :]
return rets
Args:
embs: The embedding matrix.
ids_vec: A vector of int32 embedding ids.
Returns:
The result of embedding lookups. A matrix of shape
[num ids in ids_vec, embedding dims].
"""
num = tf.shape(ids_vec)[0]
rets = inplace_ops.empty([num] + emb_shape_suf, py_utils.FPropDtype(p))
def EmbFpropLoop(i, embs, ids_vec, rets):
# row_id = ids_vec[i]
row_id = tf.gather(ids_vec, i)
# row = embs[row_id]
row = tf.reshape(tf.gather(embs, row_id), [1] + emb_shape_suf)
# rets[i] = row
rets = inplace_ops.alias_inplace_update(rets, [i], row)
return embs, ids_vec, rets
_, _, rets = functional_ops.For(
start=0,
limit=num,
delta=1,
inputs=[embs, ids_vec, rets],
body=EmbFpropLoop,
rewrite_with_while=compiled)
if len(weight_shape) > 2:
rets = tf.reshape(rets, [num, symbolic.ToStatic(p.embedding_dim)])
return rets
ऊपर दिए गए उदाहरण की तरह, tf.function के ज़रिए मॉडल को कंपोज़िट ऑपरेशन इस्तेमाल करने की अनुमति देकर, एक सामान्य इन्फ़्रास्ट्रक्चर बनाया जा सकता है. इससे, इस तरह के ऑपरेशन की पहचान करके उन्हें फ़्यूज़ किए गए LiteRT ऑपरेशन में बदला जा सकता है.
LiteRT कन्वर्टर को एक्सटेंड करना
इस साल की शुरुआत में रिलीज़ किया गया LiteRT कन्वर्टर, सिर्फ़ TensorFlow मॉडल को ग्राफ़ के तौर पर इंपोर्ट करने की सुविधा देता था. इसमें सभी वैरिएबल को उनके कॉन्सटेंट वैल्यू से बदल दिया जाता था. यह ऑपरेशन फ़्यूज़न के लिए काम नहीं करता, क्योंकि ऐसे ग्राफ़ में सभी फ़ंक्शन इनलाइन होते हैं, ताकि वैरिएबल को कॉन्स्टेंट में बदला जा सके.
कन्वर्ज़न प्रोसेस के दौरान experimental_implements सुविधा के साथ tf.function का इस्तेमाल करने के लिए, फ़ंक्शन को कन्वर्ज़न प्रोसेस के आखिर तक सेव करके रखना होगा.
इसलिए, हमने कंपोज़िट ऑपरेशन फ़्यूज़न के इस्तेमाल के उदाहरण के लिए, कनवर्टर में TensorFlow मॉडल इंपोर्ट करने और उन्हें बदलने का नया वर्कफ़्लो लागू किया है. खास तौर पर, जोड़ी गई नई सुविधाएं ये हैं:
- TensorFlow के सेव किए गए मॉडल को MLIR में इंपोर्ट करना
- फ़्यूज़ कंपोज़िट ऑपरेशंस
- वैरिएबल म्यूटबिलिटी का विश्लेषण
- सिर्फ़ पढ़ने के ऐक्सेस वाले सभी वैरिएबल फ़्रीज़ करें
इससे हम फ़ंक्शन इनलाइनिंग और वैरिएबल फ़्रीज़िंग से पहले, कंपोज़िट ऑपरेशनों को दिखाने वाले फ़ंक्शन का इस्तेमाल करके, ऑपरेशन फ़्यूज़न कर सकते हैं.
ऑपरेशन फ़्यूज़न लागू करना
आइए, ऑपरेशन फ़्यूज़न पास के बारे में ज़्यादा जानकारी देखें. इस पास से ये काम किए जा सकते हैं:
- MLIR मॉड्यूल में मौजूद सभी फ़ंक्शन को लूप करता है.
- अगर किसी फ़ंक्शन में tf._implements एट्रिब्यूट है, तो एट्रिब्यूट की वैल्यू के आधार पर, सही ऑपरेशन फ़्यूज़न यूटिलिटी को कॉल करता है.
- ऑपरेशन फ़्यूज़न यूटिलिटी, फ़ंक्शन के ऑपरेंड और एट्रिब्यूट पर काम करती है. ये एट्रिब्यूट, कन्वर्ज़न के लिए इंटरफ़ेस के तौर पर काम करते हैं. यह यूटिलिटी, फ़ंक्शन के मुख्य हिस्से को फ़्यूज़ किए गए ऑपरेशन वाले फ़ंक्शन के मुख्य हिस्से से बदल देती है.
- कई मामलों में, बदली गई बॉडी में फ़्यूज़ किए गए ऑपरेशन के अलावा अन्य ऑपरेशन भी शामिल होंगे. ये फ़ंक्शन के ऑपरेंड पर कुछ स्टैटिक ट्रांसफ़ॉर्म से मेल खाते हैं, ताकि फ़्यूज़ किए गए ऑपरेशन के ऑपरेंड मिल सकें. इन सभी कैलकुलेशन को कॉन्स्टेंट फ़ोल्ड किया जा सकता है. इसलिए, ये एक्सपोर्ट किए गए फ़्लैटबफ़र में मौजूद नहीं होंगी. इसमें सिर्फ़ फ़्यूज़ किया गया ऑपरेशन मौजूद होगा.
यहां पास का कोड स्निपेट दिया गया है, जिसमें मुख्य वर्कफ़्लो दिखाया गया है:
void PrepareCompositeFunctionsPass::ConvertTFImplements(FuncOp func,
StringAttr attr) {
if (attr.getValue() == "embedding_lookup") {
func.eraseBody();
func.addEntryBlock();
// Convert the composite embedding_lookup function body to a
// TFLite fused embedding_lookup op.
ConvertEmbeddedLookupFunc convert_embedded_lookup(func);
if (failed(convert_embedded_lookup.VerifySignature())) {
return signalPassFailure();
}
convert_embedded_lookup.RewriteFunc();
} else if (attr.getValue() == mlir::TFL::kKerasLstm) {
func.eraseBody();
func.addEntryBlock();
OpBuilder builder(func.getBody());
if (failed(ConvertKerasLSTMLayer(func, &builder))) {
return signalPassFailure();
}
} else if (.....) /* Other fusions can plug in here */
}
यहां कोड स्निपेट दिया गया है, जिसमें इस कंपोज़िट ऑपरेशन को LiteRT में फ़्यूज़ किए गए ऑपरेशन पर मैप करने का तरीका दिखाया गया है. इसमें फ़ंक्शन को कन्वर्ज़न इंटरफ़ेस के तौर पर इस्तेमाल किया गया है.
void RewriteFunc() {
Value lookup = func_.getArgument(1);
Value value = func_.getArgument(0);
auto output_type = func_.getType().getResult(0);
OpBuilder builder(func_.getBody());
auto op = builder.create<mlir::TFL::EmbeddingLookupOp>(
func_.getLoc(), output_type, lookup, value);
builder.create<mlir::ReturnOp>(func_.getLoc(), op.getResult());
}