
Menggunakan unit pemrosesan grafis (GPU) untuk menjalankan model machine learning (ML) bisa meningkatkan performa model dan pengalaman pengguna secara signifikan aplikasi berkemampuan ML. Pada perangkat iOS, Anda dapat mengaktifkan penggunaan Eksekusi model yang dipercepat oleh GPU menggunakan delegasikan. Delegasi bertindak sebagai driver perangkat keras untuk LiteRT, yang memungkinkan Anda menjalankan kode model pada prosesor GPU.
Halaman ini menjelaskan cara mengaktifkan akselerasi GPU untuk model LiteRT di aplikasi iOS. Untuk informasi selengkapnya tentang penggunaan delegasi GPU untuk LiteRT, termasuk praktik terbaik dan teknik lanjutan, baca panduan GPU delegasi.
Menggunakan GPU dengan Interpreter API
Penerjemah LiteRT API menyediakan serangkaian API tujuan untuk membangun aplikasi machine learning. Hal berikut memandu Anda dalam menambahkan dukungan GPU ke aplikasi iOS. Panduan ini mengasumsikan Anda sudah memiliki aplikasi iOS yang dapat berhasil menjalankan model ML dengan LiteRT.
Mengubah Podfile untuk menyertakan dukungan GPU
Mulai rilis LiteRT 2.3.0, delegasi GPU dikecualikan
dari pod untuk mengurangi ukuran biner. Anda dapat menyertakannya dengan menentukan
subspesifikasi untuk pod TensorFlowLiteSwift:
pod 'TensorFlowLiteSwift/Metal', '~> 0.0.1-nightly',
ATAU
pod 'TensorFlowLiteSwift', '~> 0.0.1-nightly', :subspecs => ['Metal']
Anda juga dapat menggunakan TensorFlowLiteObjC atau TensorFlowLiteC jika ingin menggunakan
Objective-C, yang tersedia untuk versi 2.4.0 dan yang lebih tinggi, atau C API.
Melakukan inisialisasi dan menggunakan delegasi GPU
Anda dapat menggunakan delegasi GPU dengan Penerjemah LiteRT API dengan sejumlah program bahasa. Swift dan Objective-C direkomendasikan, tetapi Anda juga dapat menggunakan C++ dan C. Penggunaan C diperlukan jika Anda menggunakan versi LiteRT sebelumnya dari 2,4. Contoh kode berikut menguraikan cara menggunakan delegasi dengan masing-masing bahasa tersebut.
Swift
import TensorFlowLite // Load model ... // Initialize LiteRT interpreter with the GPU delegate. let delegate = MetalDelegate() if let interpreter = try Interpreter(modelPath: modelPath, delegates: [delegate]) { // Run inference ... }
Objective-C
// Import module when using CocoaPods with module support @import TFLTensorFlowLite; // Or import following headers manually #import "tensorflow/lite/objc/apis/TFLMetalDelegate.h" #import "tensorflow/lite/objc/apis/TFLTensorFlowLite.h" // Initialize GPU delegate TFLMetalDelegate* metalDelegate = [[TFLMetalDelegate alloc] init]; // Initialize interpreter with model path and GPU delegate TFLInterpreterOptions* options = [[TFLInterpreterOptions alloc] init]; NSError* error = nil; TFLInterpreter* interpreter = [[TFLInterpreter alloc] initWithModelPath:modelPath options:options delegates:@[ metalDelegate ] error:&error]; if (error != nil) { /* Error handling... */ } if (![interpreter allocateTensorsWithError:&error]) { /* Error handling... */ } if (error != nil) { /* Error handling... */ } // Run inference ...
C++
// Set up interpreter. auto model = FlatBufferModel::BuildFromFile(model_path); if (!model) return false; tflite::ops::builtin::BuiltinOpResolver op_resolver; std::unique_ptr<Interpreter> interpreter; InterpreterBuilder(*model, op_resolver)(&interpreter); // Prepare GPU delegate. auto* delegate = TFLGpuDelegateCreate(/*default options=*/nullptr); if (interpreter->ModifyGraphWithDelegate(delegate) != kTfLiteOk) return false; // Run inference. WriteToInputTensor(interpreter->typed_input_tensor<float>(0)); if (interpreter->Invoke() != kTfLiteOk) return false; ReadFromOutputTensor(interpreter->typed_output_tensor<float>(0)); // Clean up. TFLGpuDelegateDelete(delegate);
C (sebelum 2.4.0)
#include "tensorflow/lite/c/c_api.h" #include "tensorflow/lite/delegates/gpu/metal_delegate.h" // Initialize model TfLiteModel* model = TfLiteModelCreateFromFile(model_path); // Initialize interpreter with GPU delegate TfLiteInterpreterOptions* options = TfLiteInterpreterOptionsCreate(); TfLiteDelegate* delegate = TFLGPUDelegateCreate(nil); // default config TfLiteInterpreterOptionsAddDelegate(options, metal_delegate); TfLiteInterpreter* interpreter = TfLiteInterpreterCreate(model, options); TfLiteInterpreterOptionsDelete(options); TfLiteInterpreterAllocateTensors(interpreter); NSMutableData *input_data = [NSMutableData dataWithLength:input_size * sizeof(float)]; NSMutableData *output_data = [NSMutableData dataWithLength:output_size * sizeof(float)]; TfLiteTensor* input = TfLiteInterpreterGetInputTensor(interpreter, 0); const TfLiteTensor* output = TfLiteInterpreterGetOutputTensor(interpreter, 0); // Run inference TfLiteTensorCopyFromBuffer(input, inputData.bytes, inputData.length); TfLiteInterpreterInvoke(interpreter); TfLiteTensorCopyToBuffer(output, outputData.mutableBytes, outputData.length); // Clean up TfLiteInterpreterDelete(interpreter); TFLGpuDelegateDelete(metal_delegate); TfLiteModelDelete(model);
Catatan penggunaan bahasa API GPU
- Versi LiteRT sebelum 2.4.0 hanya dapat menggunakan API C untuk {i>Objective<i}-C.
- C++ API hanya tersedia jika Anda menggunakan bazel atau mem-build TensorFlow Ringan saja. C++ API tidak dapat digunakan dengan CocoaPods.
- Saat menggunakan LiteRT dengan delegasi GPU di C++, dapatkan GPU
delegasikan melalui fungsi
TFLGpuDelegateCreate(), lalu teruskan keInterpreter::ModifyGraphWithDelegate(), bukan memanggilInterpreter::AllocateTensors().
Membangun dan menguji dengan mode rilis
Ubah ke build rilis dengan setelan akselerator Metal API yang sesuai untuk mendapatkan kinerja yang lebih baik dan untuk pengujian akhir. Bagian ini menjelaskan cara mengaktifkan build rilis dan mengonfigurasi setelan untuk Akselerasi logam.
Untuk beralih ke build rilis:
- Edit setelan build dengan memilih Product > Skema > Edit Skema... lalu memilih Run.
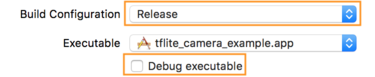
- Pada tab Info, ubah Build Configuration ke Release dan
hapus centang Debug executable.
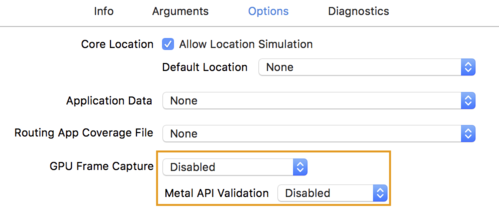
- Klik tab Options, lalu ubah GPU Frame Capture ke Disabled
dan Validasi API Logam ke Dinonaktifkan.
- Pastikan Anda memilih build khusus Rilis di arsitektur 64-bit. Di Bawah
navigator project > contoh tflite_camera_example > PROJECT > nama_project_anda >
Setelan Build menetapkan Build Active Architecture Only > Lepaskan ke
Ya.

Dukungan GPU lanjutan
Bagian ini membahas penggunaan lanjutan delegasi GPU untuk iOS, termasuk opsi delegasikan, buffer input dan output, serta penggunaan model terkuantisasi.
Delegasikan Opsi untuk iOS
Konstruktor untuk delegasi GPU menerima struct opsi di Swift
API,
Objective-C
API,
dan C
API Google.
Meneruskan nullptr (C API) atau tidak sama sekali (Objective-C dan Swift API) ke
penginisialisasi menetapkan opsi default (yang dijelaskan dalam Basic Usage
contoh di atas).
Swift
// THIS: var options = MetalDelegate.Options() options.isPrecisionLossAllowed = false options.waitType = .passive options.isQuantizationEnabled = true let delegate = MetalDelegate(options: options) // IS THE SAME AS THIS: let delegate = MetalDelegate()
Objective-C
// THIS: TFLMetalDelegateOptions* options = [[TFLMetalDelegateOptions alloc] init]; options.precisionLossAllowed = false; options.waitType = TFLMetalDelegateThreadWaitTypePassive; options.quantizationEnabled = true; TFLMetalDelegate* delegate = [[TFLMetalDelegate alloc] initWithOptions:options]; // IS THE SAME AS THIS: TFLMetalDelegate* delegate = [[TFLMetalDelegate alloc] init];
C
// THIS: const TFLGpuDelegateOptions options = { .allow_precision_loss = false, .wait_type = TFLGpuDelegateWaitType::TFLGpuDelegateWaitTypePassive, .enable_quantization = true, }; TfLiteDelegate* delegate = TFLGpuDelegateCreate(options); // IS THE SAME AS THIS: TfLiteDelegate* delegate = TFLGpuDelegateCreate(nullptr);
Buffer Input/Output menggunakan C++ API
Komputasi pada GPU mengharuskan data tersedia untuk GPU. Ini seringkali berarti Anda harus melakukan penyalinan memori. Anda harus menghindari data Anda dapat melintasi batas memori CPU/GPU jika memungkinkan, karena hal ini membutuhkan memakan banyak waktu. Biasanya, perlintasan semacam itu tidak dapat dihindari, tetapi dalam beberapa kasus khusus, salah satunya dapat diabaikan.
Jika input jaringan adalah gambar yang sudah dimuat dalam memori GPU (untuk (misalnya, tekstur GPU yang berisi feed kamera) yang dapat tetap berada di memori GPU tanpa pernah masuk ke memori CPU. Demikian pula, jika output jaringan bentuk gambar yang dapat dirender, seperti gaya gambar antar-jemput operasi, Anda dapat langsung menampilkan hasilnya di layar.
Untuk mencapai performa terbaik, LiteRT memungkinkan pengguna untuk membaca dari dan menulis ke buffer hardware TensorFlow secara langsung dan salinan memori yang bisa dihindari.
Dengan asumsi input gambar ada dalam memori GPU, Anda harus terlebih dahulu mengonversinya menjadi
Objek MTLBuffer untuk Metal. Anda dapat mengaitkan TfLiteTensor ke
MTLBuffer yang disiapkan pengguna dengan TFLGpuDelegateBindMetalBufferToTensor()
fungsi tersebut. Perhatikan bahwa fungsi ini harus dipanggil setelah
Interpreter::ModifyGraphWithDelegate(). Selain itu, output inferensinya adalah,
secara {i>default<i}, disalin dari
memori GPU ke memori CPU. Anda dapat menonaktifkan perilaku ini
dengan memanggil Interpreter::SetAllowBufferHandleOutput(true) selama
inisialisasi.
C++
#include "tensorflow/lite/delegates/gpu/metal_delegate.h" #include "tensorflow/lite/delegates/gpu/metal_delegate_internal.h" // ... // Prepare GPU delegate. auto* delegate = TFLGpuDelegateCreate(nullptr); if (interpreter->ModifyGraphWithDelegate(delegate) != kTfLiteOk) return false; interpreter->SetAllowBufferHandleOutput(true); // disable default gpu->cpu copy if (!TFLGpuDelegateBindMetalBufferToTensor( delegate, interpreter->inputs()[0], user_provided_input_buffer)) { return false; } if (!TFLGpuDelegateBindMetalBufferToTensor( delegate, interpreter->outputs()[0], user_provided_output_buffer)) { return false; } // Run inference. if (interpreter->Invoke() != kTfLiteOk) return false;
Setelah perilaku default dinonaktifkan, menyalin output inferensi dari GPU
memori ke memori CPU
membutuhkan panggilan eksplisit ke
Interpreter::EnsureTensorDataIsReadable() untuk setiap tensor output. Ini
pendekatan ini juga berfungsi untuk model terkuantisasi, tetapi Anda masih perlu menggunakan
buffer berukuran float32 dengan data float32, karena buffer terikat dengan
{i>buffer<i} de-kuantisasi internal.
Model terkuantisasi
Library delegasi GPU iOS mendukung model terkuantisasi secara default. Anda tidak perlu perlu membuat perubahan kode untuk menggunakan model terkuantisasi dengan delegasi GPU. Tujuan bagian berikut menjelaskan cara menonaktifkan dukungan terkuantisasi untuk pengujian atau tujuan eksperimental.
Menonaktifkan dukungan model terkuantisasi
Kode berikut menunjukkan cara menonaktifkan dukungan untuk model terkuantisasi.
Swift
var options = MetalDelegate.Options() options.isQuantizationEnabled = false let delegate = MetalDelegate(options: options)
Objective-C
TFLMetalDelegateOptions* options = [[TFLMetalDelegateOptions alloc] init]; options.quantizationEnabled = false;
C
TFLGpuDelegateOptions options = TFLGpuDelegateOptionsDefault(); options.enable_quantization = false; TfLiteDelegate* delegate = TFLGpuDelegateCreate(options);
Untuk mengetahui informasi selengkapnya tentang menjalankan model terkuantisasi dengan akselerasi GPU, lihat Ringkasan delegasi GPU.