
การใช้หน่วยประมวลผลกราฟิก (GPU) เพื่อเรียกใช้โมเดลแมชชีนเลิร์นนิง (ML) สามารถปรับปรุงประสิทธิภาพของโมเดลและประสบการณ์ของผู้ใช้ได้อย่างมาก ของแอปพลิเคชันที่พร้อมใช้งาน ML ในอุปกรณ์ iOS คุณสามารถเปิดใช้งาน การดำเนินการโมเดลของคุณที่มีการเร่งโดยใช้ GPU โดยใช้ ตัวแทน ผู้รับมอบสิทธิ์ทำหน้าที่เป็นไดรเวอร์ฮาร์ดแวร์ LiteRT ช่วยให้คุณเรียกใช้โค้ดของโมเดลบนตัวประมวลผล GPU ได้
หน้านี้อธิบายวิธีเปิดใช้การเร่ง GPU สำหรับโมเดล LiteRT ใน แอป iOS ดูข้อมูลเพิ่มเติมเกี่ยวกับการใช้การมอบสิทธิ์ GPU สำหรับ LiteRT รวมถึงแนวทางปฏิบัติที่ดีที่สุดและเทคนิคขั้นสูง โปรดดู GPU ผู้รับมอบสิทธิ์
ใช้ GPU กับ Interpreter API
โหมดล่ามLiteRT API จะมีชุดฟิลด์ทั่วไป API สำหรับวัตถุประสงค์ในการสร้างแอปพลิเคชันแมชชีนเลิร์นนิง ดังต่อไปนี้ จะแนะนำวิธีการเพิ่มการรองรับ GPU ลงในแอป iOS คู่มือนี้ จะถือว่าคุณมีแอป iOS ที่สามารถเรียกใช้โมเดล ML ได้สำเร็จอยู่แล้ว ด้วย LiteRT
แก้ไข Podfile เพื่อรวมการรองรับ GPU
เริ่มตั้งแต่รุ่น LiteRT 2.3.0 ระบบจะไม่รวมการมอบสิทธิ์ GPU
จากพ็อดเพื่อลดขนาดไบนารี คุณสามารถรวมได้โดยระบุ
ข้อกำหนดย่อยสำหรับพ็อด TensorFlowLiteSwift:
pod 'TensorFlowLiteSwift/Metal', '~> 0.0.1-nightly',
หรือ
pod 'TensorFlowLiteSwift', '~> 0.0.1-nightly', :subspecs => ['Metal']
คุณยังใช้ TensorFlowLiteObjC หรือ TensorFlowLiteC ได้หากต้องการ
Objective-C ซึ่งพร้อมใช้งานในเวอร์ชัน 2.4.0 ขึ้นไป หรือ C API
เริ่มต้นและใช้การมอบสิทธิ์ GPU
คุณสามารถใช้การมอบสิทธิ์ GPU กับ LiteRT ล่าม API ที่มีการเขียนโปรแกรมมากมาย ภาษา ขอแนะนำให้ใช้ Swift และ Objective-C แต่คุณจะใช้ C++ และ ค. คุณต้องใช้ C หากคุณใช้ LiteRT เวอร์ชันก่อนหน้านี้ 2.4 ตัวอย่างโค้ดต่อไปนี้ระบุวิธีใช้ผู้รับมอบสิทธิ์กับ ของภาษาเหล่านี้
Swift
import TensorFlowLite // Load model ... // Initialize LiteRT interpreter with the GPU delegate. let delegate = MetalDelegate() if let interpreter = try Interpreter(modelPath: modelPath, delegates: [delegate]) { // Run inference ... }
Objective-C
// Import module when using CocoaPods with module support @import TFLTensorFlowLite; // Or import following headers manually #import "tensorflow/lite/objc/apis/TFLMetalDelegate.h" #import "tensorflow/lite/objc/apis/TFLTensorFlowLite.h" // Initialize GPU delegate TFLMetalDelegate* metalDelegate = [[TFLMetalDelegate alloc] init]; // Initialize interpreter with model path and GPU delegate TFLInterpreterOptions* options = [[TFLInterpreterOptions alloc] init]; NSError* error = nil; TFLInterpreter* interpreter = [[TFLInterpreter alloc] initWithModelPath:modelPath options:options delegates:@[ metalDelegate ] error:&error]; if (error != nil) { /* Error handling... */ } if (![interpreter allocateTensorsWithError:&error]) { /* Error handling... */ } if (error != nil) { /* Error handling... */ } // Run inference ...
C++
// Set up interpreter. auto model = FlatBufferModel::BuildFromFile(model_path); if (!model) return false; tflite::ops::builtin::BuiltinOpResolver op_resolver; std::unique_ptr<Interpreter> interpreter; InterpreterBuilder(*model, op_resolver)(&interpreter); // Prepare GPU delegate. auto* delegate = TFLGpuDelegateCreate(/*default options=*/nullptr); if (interpreter->ModifyGraphWithDelegate(delegate) != kTfLiteOk) return false; // Run inference. WriteToInputTensor(interpreter->typed_input_tensor<float>(0)); if (interpreter->Invoke() != kTfLiteOk) return false; ReadFromOutputTensor(interpreter->typed_output_tensor<float>(0)); // Clean up. TFLGpuDelegateDelete(delegate);
C (ก่อน 2.4.0)
#include "tensorflow/lite/c/c_api.h" #include "tensorflow/lite/delegates/gpu/metal_delegate.h" // Initialize model TfLiteModel* model = TfLiteModelCreateFromFile(model_path); // Initialize interpreter with GPU delegate TfLiteInterpreterOptions* options = TfLiteInterpreterOptionsCreate(); TfLiteDelegate* delegate = TFLGPUDelegateCreate(nil); // default config TfLiteInterpreterOptionsAddDelegate(options, metal_delegate); TfLiteInterpreter* interpreter = TfLiteInterpreterCreate(model, options); TfLiteInterpreterOptionsDelete(options); TfLiteInterpreterAllocateTensors(interpreter); NSMutableData *input_data = [NSMutableData dataWithLength:input_size * sizeof(float)]; NSMutableData *output_data = [NSMutableData dataWithLength:output_size * sizeof(float)]; TfLiteTensor* input = TfLiteInterpreterGetInputTensor(interpreter, 0); const TfLiteTensor* output = TfLiteInterpreterGetOutputTensor(interpreter, 0); // Run inference TfLiteTensorCopyFromBuffer(input, inputData.bytes, inputData.length); TfLiteInterpreterInvoke(interpreter); TfLiteTensorCopyToBuffer(output, outputData.mutableBytes, outputData.length); // Clean up TfLiteInterpreterDelete(interpreter); TFLGpuDelegateDelete(metal_delegate); TfLiteModelDelete(model);
หมายเหตุการใช้ภาษา GPU API
- LiteRT เวอร์ชันก่อน 2.4.0 สามารถใช้ C API สำหรับ Objective-C
- C++ API จะพร้อมใช้งานเฉพาะเมื่อคุณใช้ Bazel หรือสร้าง TensorFlow เท่านั้น อ่านคนเดียว ใช้ C++ API กับ CocoaPods ไม่ได้
- เมื่อใช้ LiteRT กับผู้รับมอบสิทธิ์ GPU ด้วย C++ ให้รับ GPU
มอบสิทธิ์ผ่านฟังก์ชัน
TFLGpuDelegateCreate()แล้วส่งต่อไปยังInterpreter::ModifyGraphWithDelegate()แทนการโทรศัพท์Interpreter::AllocateTensors()
สร้างและทดสอบด้วยโหมดเผยแพร่
เปลี่ยนเป็นบิลด์ที่เผยแพร่ด้วยการตั้งค่าตัวเร่ง Metal API ที่เหมาะสมเพื่อ จะได้รับประสิทธิภาพที่ดีขึ้นและสำหรับการทดสอบในขั้นตอนสุดท้าย ส่วนนี้อธิบายวิธีการ เปิดใช้บิลด์รุ่นและกำหนดค่าสำหรับการเร่งความเร็วด้วยโลหะ
วิธีเปลี่ยนเป็นบิลด์ที่เผยแพร่
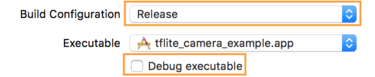
- แก้ไขการตั้งค่าบิลด์โดยเลือกผลิตภัณฑ์ > รูปแบบ > แก้ไขรูปแบบ... จากนั้นเลือกเรียกใช้
- ในแท็บข้อมูล ให้เปลี่ยนการกำหนดค่ารุ่นเป็นรุ่น และ
ยกเลิกการเลือกแก้ไขข้อบกพร่องไฟล์ปฏิบัติการ
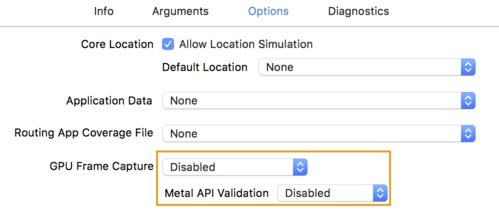
- คลิกแท็บตัวเลือก และเปลี่ยน GPU Frame Capture เป็น Disabled
และการตรวจสอบ API ของเมตาเป็นปิดใช้
- ตรวจสอบว่าได้เลือกบิลด์เฉพาะรุ่นเท่านั้นบนสถาปัตยกรรม 64 บิต ต่ำกว่า
ตัวนำทางโปรเจ็กต์ > ตัวอย่างกล้อง tflite > โปรเจ็กต์ > your_project_name >
การตั้งค่าบิลด์ได้ตั้งค่าสร้างสถาปัตยกรรมที่ใช้งานอยู่เท่านั้น > ปล่อยไปยัง
ใช่

การรองรับ GPU ขั้นสูง
ส่วนนี้ครอบคลุมการใช้งานขั้นสูงเกี่ยวกับการมอบสิทธิ์ GPU สำหรับ iOS รวมถึง ตัวเลือกการมอบสิทธิ์ บัฟเฟอร์อินพุตและเอาต์พุต และการใช้โมเดลที่เล็กลง
ตัวเลือกการมอบสิทธิ์สำหรับ iOS
ตัวสร้างสำหรับผู้รับมอบสิทธิ์ GPU ยอมรับ struct ของตัวเลือกใน Swift
API
Objective-C
API
และ C
API
ส่ง nullptr (C API) หรือไม่ต้องส่งเลย (Objective-C และ Swift API) ไปยัง
โปรแกรมเริ่มต้นจะตั้งค่าตัวเลือกเริ่มต้น (ซึ่งอธิบายไว้อย่างชัดแจ้งในการใช้งานพื้นฐาน)
ตัวอย่างด้านบน)
Swift
// THIS: var options = MetalDelegate.Options() options.isPrecisionLossAllowed = false options.waitType = .passive options.isQuantizationEnabled = true let delegate = MetalDelegate(options: options) // IS THE SAME AS THIS: let delegate = MetalDelegate()
Objective-C
// THIS: TFLMetalDelegateOptions* options = [[TFLMetalDelegateOptions alloc] init]; options.precisionLossAllowed = false; options.waitType = TFLMetalDelegateThreadWaitTypePassive; options.quantizationEnabled = true; TFLMetalDelegate* delegate = [[TFLMetalDelegate alloc] initWithOptions:options]; // IS THE SAME AS THIS: TFLMetalDelegate* delegate = [[TFLMetalDelegate alloc] init];
C
// THIS: const TFLGpuDelegateOptions options = { .allow_precision_loss = false, .wait_type = TFLGpuDelegateWaitType::TFLGpuDelegateWaitTypePassive, .enable_quantization = true, }; TfLiteDelegate* delegate = TFLGpuDelegateCreate(options); // IS THE SAME AS THIS: TfLiteDelegate* delegate = TFLGpuDelegateCreate(nullptr);
บัฟเฟอร์อินพุต/เอาต์พุตโดยใช้ C++ API
การประมวลผลบน GPU กำหนดให้ข้อมูลพร้อมใช้งานสำหรับ GPU ช่วงเวลานี้ มักหมายความว่าคุณต้องทำสำเนาหน่วยความจำ คุณควรหลีกเลี่ยงไม่ให้ ข้อมูลของคุณข้ามขอบเขตหน่วยความจำของ CPU/GPU หากเป็นไปได้ เนื่องจากอาจต้องใช้ ระยะเวลาค่อนข้างนาน ปกติแล้ว การข้ามถนนแบบนั้นหลีกเลี่ยงไม่ได้ แต่ในบางสถานการณ์ กรณีพิเศษ ยกเว้นกรณีใดกรณีหนึ่งได้
หากอินพุตของเครือข่ายเป็นรูปภาพที่โหลดลงในหน่วยความจำ GPU แล้ว (สำหรับ เช่น พื้นผิว GPU ที่มีฟีดกล้อง) องค์ประกอบดังกล่าวจะอยู่ในหน่วยความจำ GPU ต่อไป โดยไม่ต้องป้อนหน่วยความจำของ CPU ในทำนองเดียวกัน หากเอาต์พุตของเครือข่ายอยู่ใน รูปแบบของรูปภาพที่แสดงผลได้ เช่น สไตล์ของรูปภาพ การเปลี่ยนเครื่อง คุณสามารถแสดงผลลัพธ์บนหน้าจอได้โดยตรง
เพื่อให้ได้ประสิทธิภาพที่ดีที่สุด LiteRT ช่วยให้ผู้ใช้ อ่านและเขียนไปยังบัฟเฟอร์ฮาร์ดแวร์ TensorFlow โดยตรงและข้าม สำเนาหน่วยความจำที่หลีกเลี่ยงได้
สมมติว่าอินพุตรูปภาพอยู่ในหน่วยความจำ GPU คุณต้องแปลงเป็น
ออบเจ็กต์ MTLBuffer รายการสำหรับโลหะ คุณสามารถเชื่อมโยง TfLiteTensor กับ
MTLBuffer ที่เตรียมโดยผู้ใช้ด้วย TFLGpuDelegateBindMetalBufferToTensor()
โปรดทราบว่าฟังก์ชันนี้ต้องเรียกใช้หลังจาก
Interpreter::ModifyGraphWithDelegate() นอกจากนี้ เอาต์พุตการอนุมานยัง
โดยค่าเริ่มต้น คัดลอกจากหน่วยความจำ GPU ไปยังหน่วยความจำของ CPU คุณสามารถปิดลักษณะการทำงานนี้ได้
โดยโทรหา Interpreter::SetAllowBufferHandleOutput(true) ระหว่าง
การเริ่มต้น
C++
#include "tensorflow/lite/delegates/gpu/metal_delegate.h" #include "tensorflow/lite/delegates/gpu/metal_delegate_internal.h" // ... // Prepare GPU delegate. auto* delegate = TFLGpuDelegateCreate(nullptr); if (interpreter->ModifyGraphWithDelegate(delegate) != kTfLiteOk) return false; interpreter->SetAllowBufferHandleOutput(true); // disable default gpu->cpu copy if (!TFLGpuDelegateBindMetalBufferToTensor( delegate, interpreter->inputs()[0], user_provided_input_buffer)) { return false; } if (!TFLGpuDelegateBindMetalBufferToTensor( delegate, interpreter->outputs()[0], user_provided_output_buffer)) { return false; } // Run inference. if (interpreter->Invoke() != kTfLiteOk) return false;
เมื่อปิดลักษณะการทำงานเริ่มต้นแล้ว การคัดลอกเอาต์พุตการอนุมานจาก GPU
ไปยังหน่วยความจําของ CPU ต้องมีการเรียก
Interpreter::EnsureTensorDataIsReadable() สำหรับ Tensor เอาต์พุตแต่ละรายการ ช่วงเวลานี้
แนวทางนี้ยังใช้กับโมเดลที่เล็กลงได้ด้วย แต่คุณยังต้องใช้
บัฟเฟอร์ขนาด Float32 ที่มีข้อมูล Float32 เนื่องจากบัฟเฟอร์เชื่อมโยงกับข้อมูล
บัฟเฟอร์ที่ลดปริมาณภายใน
โมเดลเชิงปริมาณ
ไลบรารีการมอบสิทธิ์ GPU ของ iOS รองรับโมเดลที่ควอนซ์โดยค่าเริ่มต้น คุณไม่ได้ ต้องเปลี่ยนแปลงโค้ดเพื่อใช้โมเดลที่ควอนซ์กับการมอบสิทธิ์ GPU ส่วนต่อไปนี้จะอธิบายวิธีปิดใช้การสนับสนุนที่เล็กลงสำหรับการทดสอบหรือ เพื่อการทดลอง
ปิดใช้การรองรับโมเดลที่เล็กลง
โค้ดต่อไปนี้แสดงวิธีปิดใช้การรองรับโมเดลที่เล็กลง
Swift
var options = MetalDelegate.Options() options.isQuantizationEnabled = false let delegate = MetalDelegate(options: options)
Objective-C
TFLMetalDelegateOptions* options = [[TFLMetalDelegateOptions alloc] init]; options.quantizationEnabled = false;
C
TFLGpuDelegateOptions options = TFLGpuDelegateOptionsDefault(); options.enable_quantization = false; TfLiteDelegate* delegate = TFLGpuDelegateCreate(options);
ดูข้อมูลเพิ่มเติมเกี่ยวกับการเรียกใช้โมเดลที่เล็กลงด้วยการเร่ง GPU ได้ที่ ภาพรวมผู้รับมอบสิทธิ์ GPU