
LiteRT 벤치마크 도구는 다음 중요한 성능 측정항목의 통계를 측정하고 계산합니다.
- 초기화 시간
- 준비 상태의 추론 시간
- 안정 상태의 추론 시간
- 초기화 시간 동안의 메모리 사용량
- 전체 메모리 사용량
벤치마크 도구는 Android 및 iOS용 벤치마크 앱과 미리 빌드된 명령줄 바이너리로 제공되며 모두 동일한 핵심 성능 측정 로직을 공유합니다. 런타임 환경의 차이로 인해 사용 가능한 옵션과 출력 형식이 약간 다릅니다.
Android 벤치마크 앱
v1 인터프리터 API를 기반으로 하는 Android 벤치마크 앱도 제공됩니다. 이는 Android 앱에서 모델이 어떻게 작동하는지 더 잘 보여줍니다. 벤치마크 도구의 숫자는 실제 앱에서 모델로 추론을 실행할 때와 약간 다릅니다.
이 Android 벤치마크 앱에는 UI가 없습니다. adb 명령어를 사용하여 설치하고 실행하고 adb logcat 명령어를 사용하여 결과를 가져옵니다.
앱 다운로드 또는 빌드
다음 링크를 사용하여 야간에 미리 빌드된 Android 벤치마크 앱을 다운로드합니다.
Flex 위임자를 통해 TF 작업을 지원하는 Android 벤치마크 앱의 경우 아래 링크를 사용하세요.
이 안내에 따라 소스에서 앱을 빌드할 수도 있습니다.
벤치마크 준비
벤치마크 앱을 실행하기 전에 다음과 같이 앱을 설치하고 모델 파일을 기기에 푸시합니다.
adb install -r -d -g android_aarch64_benchmark_model.apk
adb push your_model.tflite /data/local/tmp
벤치마크 실행
adb shell am start -S \
-n org.tensorflow.lite.benchmark/.BenchmarkModelActivity \
--es args '"--graph=/data/local/tmp/your_model.tflite \
--num_threads=4"'
graph은 필수 매개변수입니다.
graph:string
TFLite 모델 파일의 경로입니다.
벤치마크 실행을 위한 선택적 매개변수를 더 많이 지정할 수 있습니다.
num_threads:int(기본값=1)
TFLite 인터프리터를 실행하는 데 사용할 스레드 수입니다.use_gpu:bool(기본값=false)
GPU 위임자를 사용합니다.use_xnnpack:bool(기본값=false)
XNNPACK 위임자를 사용합니다.
사용 중인 기기에 따라 이러한 옵션 중 일부를 사용하지 못하거나 효과가 없을 수 있습니다. 벤치마크 앱으로 실행할 수 있는 추가 성능 매개변수는 매개변수를 참고하세요.
logcat 명령어를 사용하여 결과를 확인합니다.
adb logcat | grep "Inference timings"
벤치마크 결과는 다음과 같이 보고됩니다.
... tflite : Inference timings in us: Init: 5685, First inference: 18535, Warmup (avg): 14462.3, Inference (avg): 14575.2
iOS 벤치마크 앱
iOS 기기에서 벤치마크를 실행하려면 소스에서 앱을 빌드해야 합니다.
LiteRT 모델 파일을 소스 트리의 benchmark_data 디렉터리에 넣고 benchmark_params.json 파일을 수정합니다. 이러한 파일은 앱에 패키징되고 앱은 디렉터리에서 데이터를 읽습니다. 자세한 안내는 iOS 벤치마크 앱을 참고하세요.
유명 모델의 성능 업계 기준치
이 섹션에는 일부 Android 및 iOS 기기에서 잘 알려진 모델을 실행할 때의 LiteRT 성능 벤치마크가 나열되어 있습니다.
Android 성능 벤치마크
이러한 성능 벤치마크 번호는 네이티브 벤치마크 바이너리로 생성되었습니다.
Android 벤치마크의 경우 변동을 줄이기 위해 기기에서 빅 코어를 사용하도록 CPU 선호도가 설정됩니다 (세부정보 참고).
모델이 /data/local/tmp/tflite_models 디렉터리에 다운로드되고 압축이 해제되었다고 가정합니다. 벤치마크 바이너리는 이 안내를 사용하여 빌드되며 /data/local/tmp 디렉터리에 있다고 가정합니다.
벤치마크를 실행하려면 다음 단계를 따르세요.
adb shell /data/local/tmp/benchmark_model \
--num_threads=4 \
--graph=/data/local/tmp/tflite_models/${GRAPH} \
--warmup_runs=1 \
--num_runs=50
GPU 위임으로 실행하려면 --use_gpu=true을 설정합니다.
아래 성능 값은 Android 10에서 측정되었습니다.
| 모델 이름 | 기기 | CPU, 스레드 4개 | GPU |
|---|---|---|---|
| Mobilenet_1.0_224(float) | Pixel 3 | 23.9 ms | 6.45 ms |
| Pixel 4 | 14.0 ms | 9.0 ms | |
| Mobilenet_1.0_224 (양자화) | Pixel 3 | 13.4 ms | --- |
| Pixel 4 | 5.0 ms | --- | |
| NASNet mobile | Pixel 3 | 56 ms | --- |
| Pixel 4 | 34.5 ms | --- | |
| SqueezeNet | Pixel 3 | 35.8 ms | 9.5 ms |
| Pixel 4 | 23.9 ms | 11.1 ms | |
| Inception_ResNet_V2 | Pixel 3 | 422 ms | 99.8 ms |
| Pixel 4 | 272.6 ms | 87.2 ms | |
| Inception_V4 | Pixel 3 | 486 ms | 93 ms |
| Pixel 4 | 324.1 ms | 97.6 ms |
iOS 성능 업계 기준치
이 성능 벤치마크 번호는 iOS 벤치마크 앱으로 생성되었습니다.
iOS 벤치마크를 실행하기 위해 적절한 모델을 포함하도록 벤치마크 앱이 수정되었고 num_threads을 2로 설정하도록 benchmark_params.json가 수정되었습니다. GPU 위임을 사용하기 위해 "use_gpu" : "1" 및 "gpu_wait_type" : "aggressive" 옵션도 benchmark_params.json에 추가되었습니다.
| 모델 이름 | 기기 | CPU, 스레드 2개 | GPU |
|---|---|---|---|
| Mobilenet_1.0_224(float) | iPhone XS | 14.8 ms | 3.4 ms |
| Mobilenet_1.0_224 (양자화) | iPhone XS | 11ms | --- |
| NASNet mobile | iPhone XS | 30.4 ms | --- |
| SqueezeNet | iPhone XS | 21.1 ms | 15.5 ms |
| Inception_ResNet_V2 | iPhone XS | 261.1 ms | 45.7 ms |
| Inception_V4 | iPhone XS | 309 ms | 54.4 ms |
LiteRT 내부 추적
Android에서 LiteRT 내부 추적
Android 앱의 LiteRT 인터프리터에서 발생하는 내부 이벤트는 Android 추적 도구로 캡처할 수 있습니다. Android Trace API와 동일한 이벤트이므로 Java/Kotlin 코드에서 캡처된 이벤트가 LiteRT 내부 이벤트와 함께 표시됩니다.
이벤트의 예는 다음과 같습니다.
- 연산자 호출
- 위임에 의한 그래프 수정
- 텐서 할당
트레이스를 캡처하는 다양한 옵션 중에서 이 가이드에서는 Android 스튜디오 CPU 프로파일러와 시스템 추적 앱을 다룹니다. 다른 옵션은 Perfetto 명령줄 도구 또는 Systrace 명령줄 도구를 참고하세요.
Java 코드에서 트레이스 이벤트 추가
이미지 분류 예시 앱의 코드 스니펫입니다. LiteRT 인터프리터는 recognizeImage/runInference 섹션에서 실행됩니다. 이 단계는 선택사항이지만 추론 호출이 이루어지는 위치를 파악하는 데 유용합니다.
Trace.beginSection("recognizeImage");
...
// Runs the inference call.
Trace.beginSection("runInference");
tflite.run(inputImageBuffer.getBuffer(), outputProbabilityBuffer.getBuffer().rewind());
Trace.endSection();
...
Trace.endSection();
LiteRT 추적 사용 설정
LiteRT 추적을 사용 설정하려면 Android 앱을 시작하기 전에 Android 시스템 속성 debug.tflite.trace를 1로 설정하세요.
adb shell setprop debug.tflite.trace 1
LiteRT 인터프리터가 초기화될 때 이 속성이 설정된 경우 인터프리터의 키 이벤트 (예: 연산자 호출)가 추적됩니다.
모든 트레이스를 캡처한 후 속성 값을 0으로 설정하여 트레이싱을 사용 중지합니다.
adb shell setprop debug.tflite.trace 0
Android 스튜디오 CPU 프로파일러
아래 단계에 따라 Android 스튜디오 CPU 프로파일러로 트레이스를 캡처합니다.
상단 메뉴에서 실행 > 'app' 프로파일링을 선택합니다.
프로파일러 창이 표시되면 CPU 타임라인의 아무 곳이나 클릭합니다.
CPU 프로파일링 모드 중에서 '시스템 호출 추적'을 선택합니다.
'녹화' 버튼을 누릅니다.
'중지' 버튼을 누릅니다.
트레이스 결과를 조사합니다.
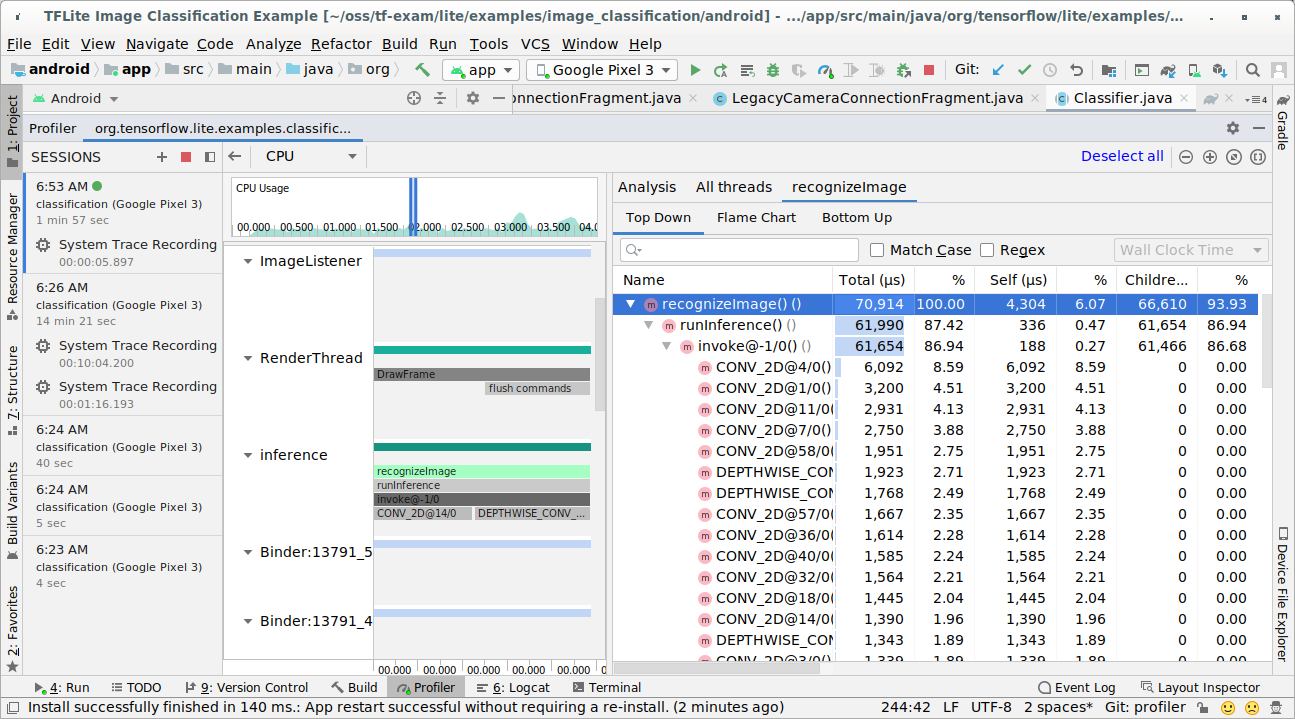
이 예에서는 스레드의 이벤트 계층 구조와 각 연산자 시간에 대한 통계를 확인할 수 있으며 스레드 간 전체 앱의 데이터 흐름도 확인할 수 있습니다.
시스템 추적 앱
시스템 트레이싱 앱에 자세히 설명된 단계에 따라 Android 스튜디오 없이 트레이스를 캡처합니다.
이 예에서는 Android 기기 버전에 따라 동일한 TFLite 이벤트가 Perfetto 또는 Systrace 형식으로 캡처되고 저장되었습니다. 캡처된 트레이스 파일은 Perfetto UI에서 열 수 있습니다.
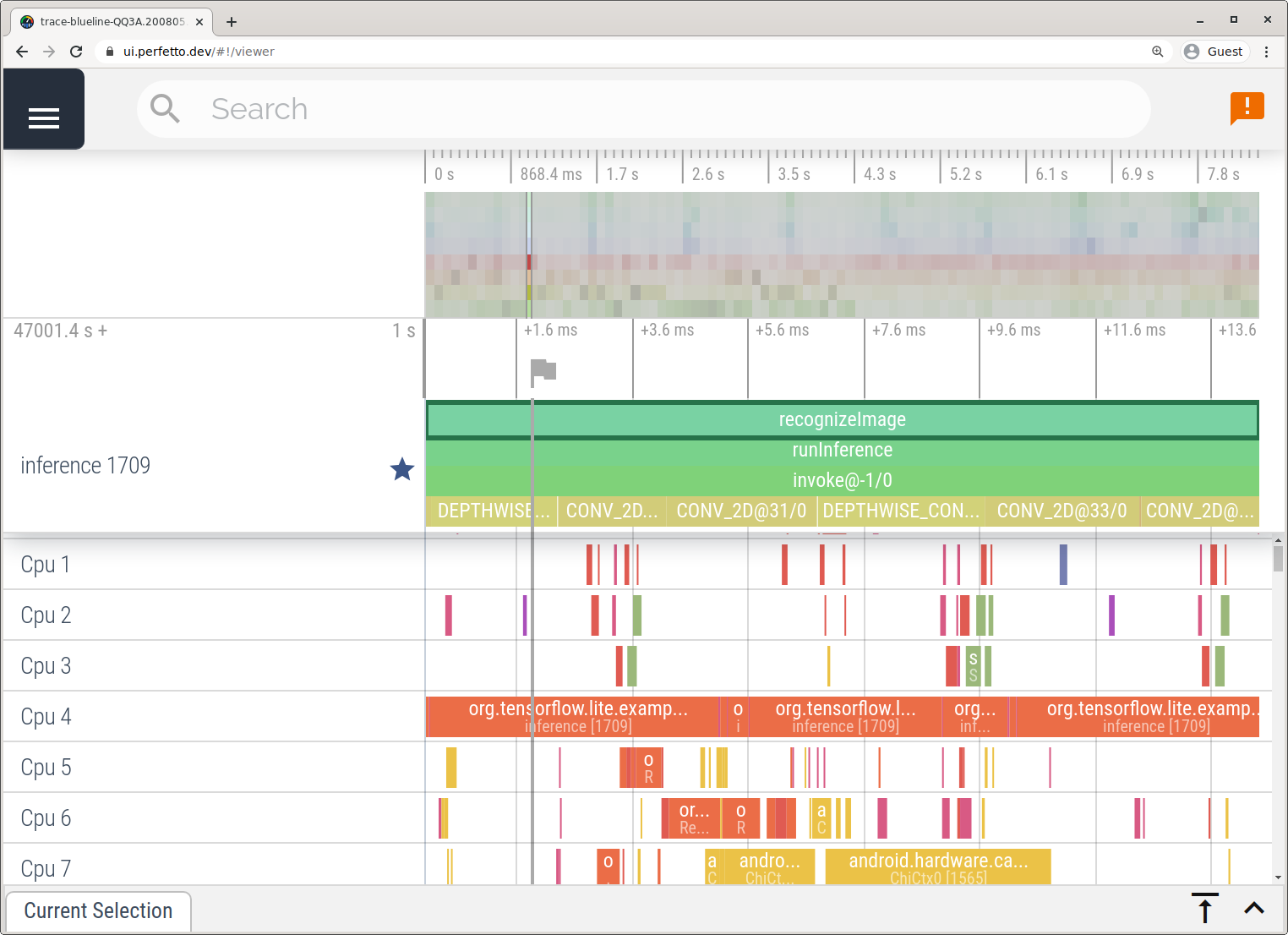
iOS에서 LiteRT 내부 추적
iOS 앱의 LiteRT 인터프리터에서 발생하는 내부 이벤트는 Xcode에 포함된 Instruments 도구로 캡처할 수 있습니다. 이러한 이벤트는 iOS signpost 이벤트이므로 Swift/Objective-C 코드에서 캡처된 이벤트가 LiteRT 내부 이벤트와 함께 표시됩니다.
이벤트의 예는 다음과 같습니다.
- 연산자 호출
- 위임에 의한 그래프 수정
- 텐서 할당
LiteRT 추적 사용 설정
아래 단계에 따라 환경 변수 debug.tflite.trace를 설정합니다.
Xcode의 상단 메뉴에서 Product(제품) > Scheme(스키마) > Edit Scheme(스키마 수정)을 선택합니다.
왼쪽 창에서 '프로필'을 클릭합니다.
'실행 작업의 인수 및 환경 변수 사용' 체크박스를 선택 해제합니다.
'환경 변수' 섹션에
debug.tflite.trace를 추가합니다.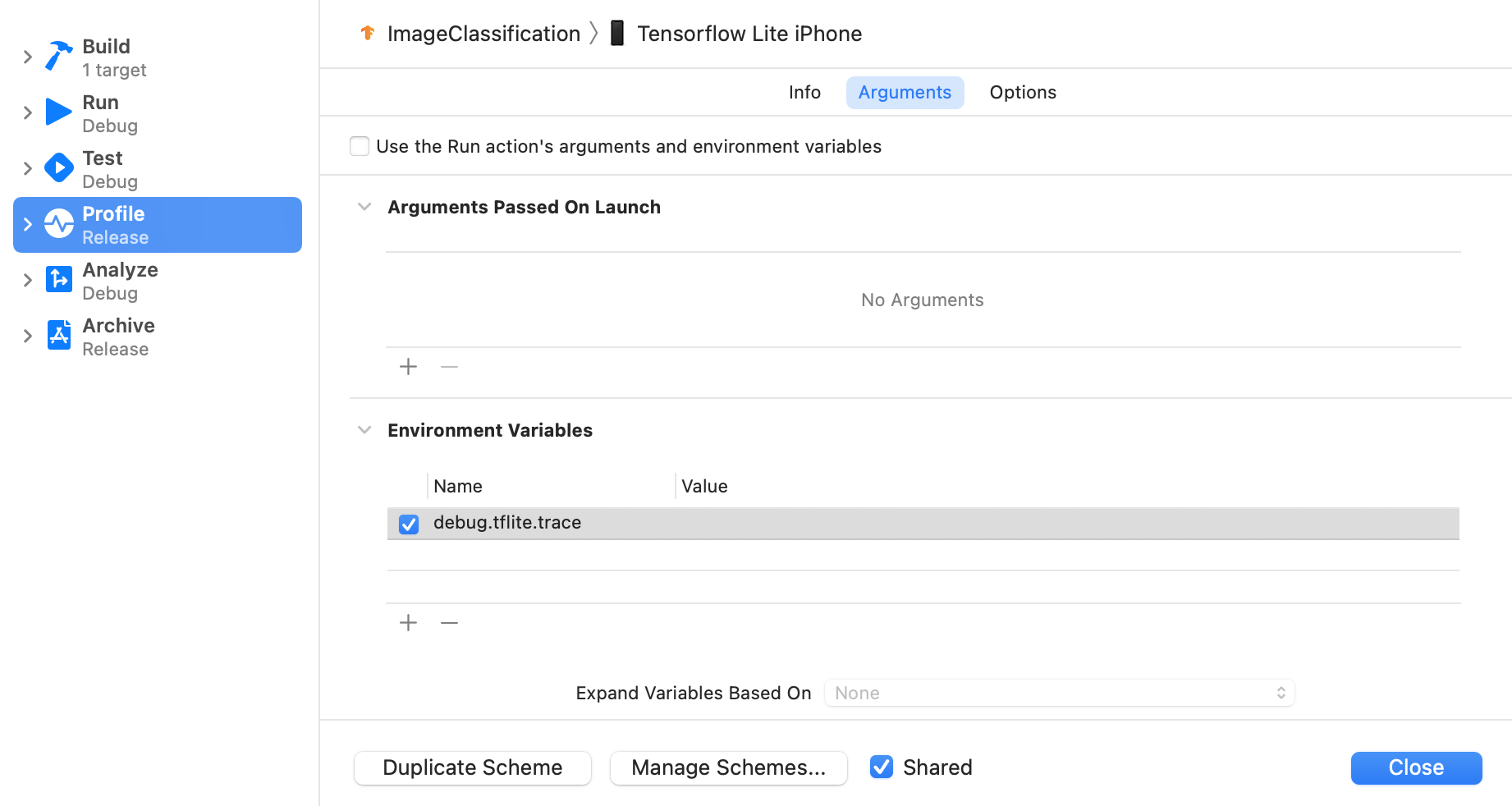
iOS 앱을 프로파일링할 때 LiteRT 이벤트를 제외하려면 환경 변수를 삭제하여 추적을 사용 중지하세요.
XCode Instruments
아래 단계에 따라 트레이스를 캡처합니다.
Xcode의 상단 메뉴에서 제품 > 프로필을 선택합니다.
Instruments 도구가 실행되면 프로파일링 템플릿 중에서 Logging을 클릭합니다.
'시작' 버튼을 누릅니다.
'중지' 버튼을 누릅니다.
'os_signpost'를 클릭하여 OS 로깅 하위 시스템 항목을 펼칩니다.
'org.tensorflow.lite' OS 로깅 하위 시스템을 클릭합니다.
트레이스 결과를 조사합니다.
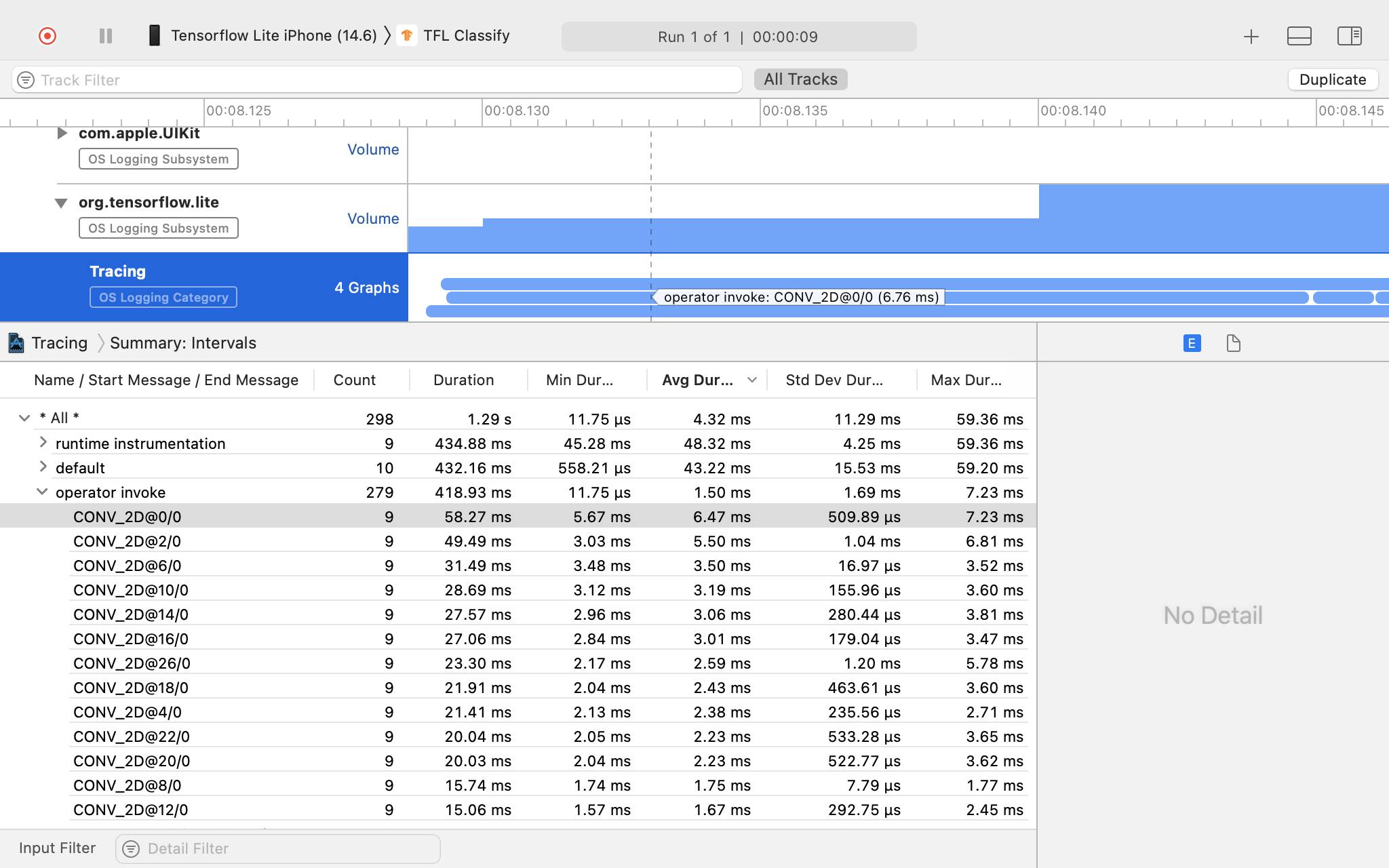
이 예에서는 각 작업자 시간의 이벤트 및 통계 계층 구조를 확인할 수 있습니다.
추적 데이터 사용
추적 데이터를 사용하면 성능 병목 현상을 식별할 수 있습니다.
다음은 프로파일러에서 얻을 수 있는 통계와 성능을 개선할 수 있는 잠재적 솔루션의 예입니다.
- 사용 가능한 CPU 코어 수가 추론 스레드 수보다 작으면 CPU 스케줄링 오버헤드로 인해 성능이 저하될 수 있습니다. 모델 추론과 겹치지 않도록 애플리케이션에서 다른 CPU 집약적 작업을 다시 예약하거나 인터프리터 스레드 수를 조정할 수 있습니다.
- 연산자가 완전히 위임되지 않으면 모델 그래프의 일부가 예상되는 하드웨어 가속기가 아닌 CPU에서 실행됩니다. 지원되지 않는 연산자를 지원되는 유사한 연산자로 대체할 수 있습니다.