
Edge डिवाइसों में अक्सर मेमोरी या कंप्यूटेशनल पावर सीमित होती है. मॉडल पर कई तरह के ऑप्टिमाइज़ेशन लागू किए जा सकते हैं, ताकि उन्हें इन शर्तों के मुताबिक चलाया जा सके. इसके अलावा, कुछ ऑप्टिमाइज़ेशन से अनुमान लगाने की प्रोसेस को तेज़ करने के लिए, खास हार्डवेयर का इस्तेमाल किया जा सकता है.
LiteRT और TensorFlow Model Optimization Toolkit, अनुमान लगाने की प्रोसेस को ऑप्टिमाइज़ करने के लिए टूल उपलब्ध कराते हैं.
हमारा सुझाव है कि ऐप्लिकेशन डेवलपमेंट प्रोसेस के दौरान, मॉडल ऑप्टिमाइज़ेशन पर ध्यान दें. इस दस्तावेज़ में, एज हार्डवेयर पर डिप्लॉयमेंट के लिए TensorFlow मॉडल को ऑप्टिमाइज़ करने के कुछ सबसे सही तरीके बताए गए हैं.
मॉडल को ऑप्टिमाइज़ क्यों करना चाहिए
मॉडल ऑप्टिमाइज़ेशन, ऐप्लिकेशन डेवलपमेंट में कई तरह से मदद कर सकता है.
साइज़ कम करना
मॉडल के साइज़ को कम करने के लिए, ऑप्टिमाइज़ेशन के कुछ तरीकों का इस्तेमाल किया जा सकता है. छोटे मॉडल के ये फ़ायदे हैं:
- स्टोरेज का कम साइज़: छोटे मॉडल, आपके उपयोगकर्ताओं के डिवाइसों पर कम स्टोरेज स्पेस लेते हैं. उदाहरण के लिए, छोटे मॉडल का इस्तेमाल करने वाला Android ऐप्लिकेशन, उपयोगकर्ता के फ़ोन या टैबलेट पर कम स्टोरेज स्पेस लेगा.
- डाउनलोड करने के लिए कम साइज़: छोटे मॉडल को लोगों के डिवाइसों पर डाउनलोड करने के लिए, कम समय और बैंडविथ की ज़रूरत होती है.
- कम मेमोरी का इस्तेमाल: छोटे मॉडल को चलाने के लिए कम रैम की ज़रूरत होती है. इससे आपके ऐप्लिकेशन के अन्य हिस्सों के लिए मेमोरी खाली हो जाती है. साथ ही, इससे परफ़ॉर्मेंस और स्थिरता बेहतर हो सकती है.
क्वांटाइज़ेशन से, इन सभी मामलों में मॉडल का साइज़ कम किया जा सकता है. हालांकि, इससे मॉडल की परफ़ॉर्मेंस पर असर पड़ सकता है. प्रूनिंग और क्लस्टरिंग की मदद से, मॉडल को डाउनलोड करने के लिए उसके साइज़ को कम किया जा सकता है. ऐसा इसलिए, क्योंकि इससे मॉडल को आसानी से कंप्रेस किया जा सकता है.
इंतज़ार का समय कम करने की सेटिंग
लेटेंसी से पता चलता है कि किसी मॉडल के साथ एक बार अनुमान लगाने में कितना समय लगता है. ऑप्टिमाइज़ेशन के कुछ तरीकों से, मॉडल का इस्तेमाल करके अनुमान लगाने के लिए ज़रूरी कंप्यूटेशन की मात्रा कम की जा सकती है. इससे लेटेन्सी कम हो जाती है. लेटेंसी का असर, बिजली की खपत पर भी पड़ सकता है.
फ़िलहाल, क्वांटाइज़ेशन का इस्तेमाल करके, अनुमान लगाने के दौरान होने वाली कैलकुलेशन को आसान बनाया जा सकता है. इससे अनुमान लगाने में लगने वाला समय कम हो जाता है. हालांकि, इससे अनुमान की सटीकता पर असर पड़ सकता है.
ऐक्सलरेटर के साथ काम करने की सुविधा
Edge TPU जैसे कुछ हार्डवेयर ऐक्सलरेटर, सही तरीके से ऑप्टिमाइज़ किए गए मॉडल के साथ बहुत तेज़ी से अनुमान लगा सकते हैं.
आम तौर पर, इस तरह के डिवाइसों के लिए मॉडल को खास तरीके से क्वांटाइज़ करने की ज़रूरत होती है. हर हार्डवेयर ऐक्सलरेटर की ज़रूरी शर्तों के बारे में ज़्यादा जानने के लिए, उनके दस्तावेज़ देखें.
ट्रेड-ऑफ़
ऑप्टिमाइज़ेशन से मॉडल की परफ़ॉर्मेंस में बदलाव हो सकता है. इसलिए, ऐप्लिकेशन डेवलपमेंट प्रोसेस के दौरान इस बात का ध्यान रखना ज़रूरी है.
सटीकता में होने वाले बदलाव, ऑप्टिमाइज़ किए जा रहे मॉडल पर निर्भर करते हैं. साथ ही, इनके बारे में पहले से अनुमान लगाना मुश्किल होता है. आम तौर पर, साइज़ या इंतज़ार के समय के लिए ऑप्टिमाइज़ किए गए मॉडल की सटीकता में थोड़ी कमी आएगी. आपके ऐप्लिकेशन के आधार पर, इससे उपयोगकर्ताओं के अनुभव पर असर पड़ सकता है या नहीं भी पड़ सकता. कुछ मामलों में, ऑप्टिमाइज़ेशन की प्रोसेस की वजह से, कुछ मॉडल ज़्यादा सटीक नतीजे दे सकते हैं.
ऑप्टिमाइज़ेशन के टाइप
फ़िलहाल, LiteRT में क्वानटाइज़ेशन, प्रूनिंग, और क्लस्टरिंग के ज़रिए ऑप्टिमाइज़ेशन किया जा सकता है.
ये TensorFlow Model Optimization Toolkit का हिस्सा हैं. यह टूलकिट, मॉडल ऑप्टिमाइज़ेशन की उन तकनीकों के लिए संसाधन उपलब्ध कराती है जो TensorFlow Lite के साथ काम करती हैं.
क्वांटाइज़ेशन
क्वांटाइज़ेशन की मदद से, मॉडल के पैरामीटर को दिखाने के लिए इस्तेमाल की गई संख्याओं की सटीक जानकारी को कम किया जाता है. डिफ़ॉल्ट रूप से, ये 32-बिट फ़्लोटिंग पॉइंट नंबर होते हैं. इससे मॉडल का साइज़ छोटा हो जाता है और कैलकुलेशन तेज़ी से होता है.
LiteRT में, इस तरह के क्वांटाइज़ेशन उपलब्ध हैं:
| तकनीक | डेटा से जुड़ी ज़रूरी शर्तें | साइज़ कम करना | सटीक जवाब | इस सुविधा के साथ काम करने वाला हार्डवेयर |
|---|---|---|---|---|
| ट्रेनिंग के बाद float16 क्वानटाइज़ेशन | कोई डेटा नहीं मिला | 50% तक | सटीकता में मामूली कमी | सीपीयू, जीपीयू |
| ट्रेनिंग के बाद डाइनैमिक रेंज क्वांटाइज़ेशन | कोई डेटा नहीं मिला | 75% तक | सटीकता में सबसे कम अंतर | सीपीयू, जीपीयू (Android) |
| ट्रेनिंग के बाद पूर्णांक क्वांटाइज़ेशन | बिना लेबल वाला प्रतिनिधि सैंपल | 75% तक | सटीकता में मामूली कमी | सीपीयू, जीपीयू (Android), EdgeTPU |
| क्वांटाइज़ेशन-अवेयर ट्रेनिंग | लेबल किया गया ट्रेनिंग डेटा | 75% तक | सटीकता में सबसे कम अंतर | सीपीयू, जीपीयू (Android), EdgeTPU |
यहां दिए गए फ़्लोचार्ट की मदद से, अपने मॉडल के लिए क्वानटाइज़ेशन स्कीम चुनी जा सकती हैं. इसके लिए, आपको सिर्फ़ मॉडल के अनुमानित साइज़ और सटीक होने की जानकारी देनी होगी.
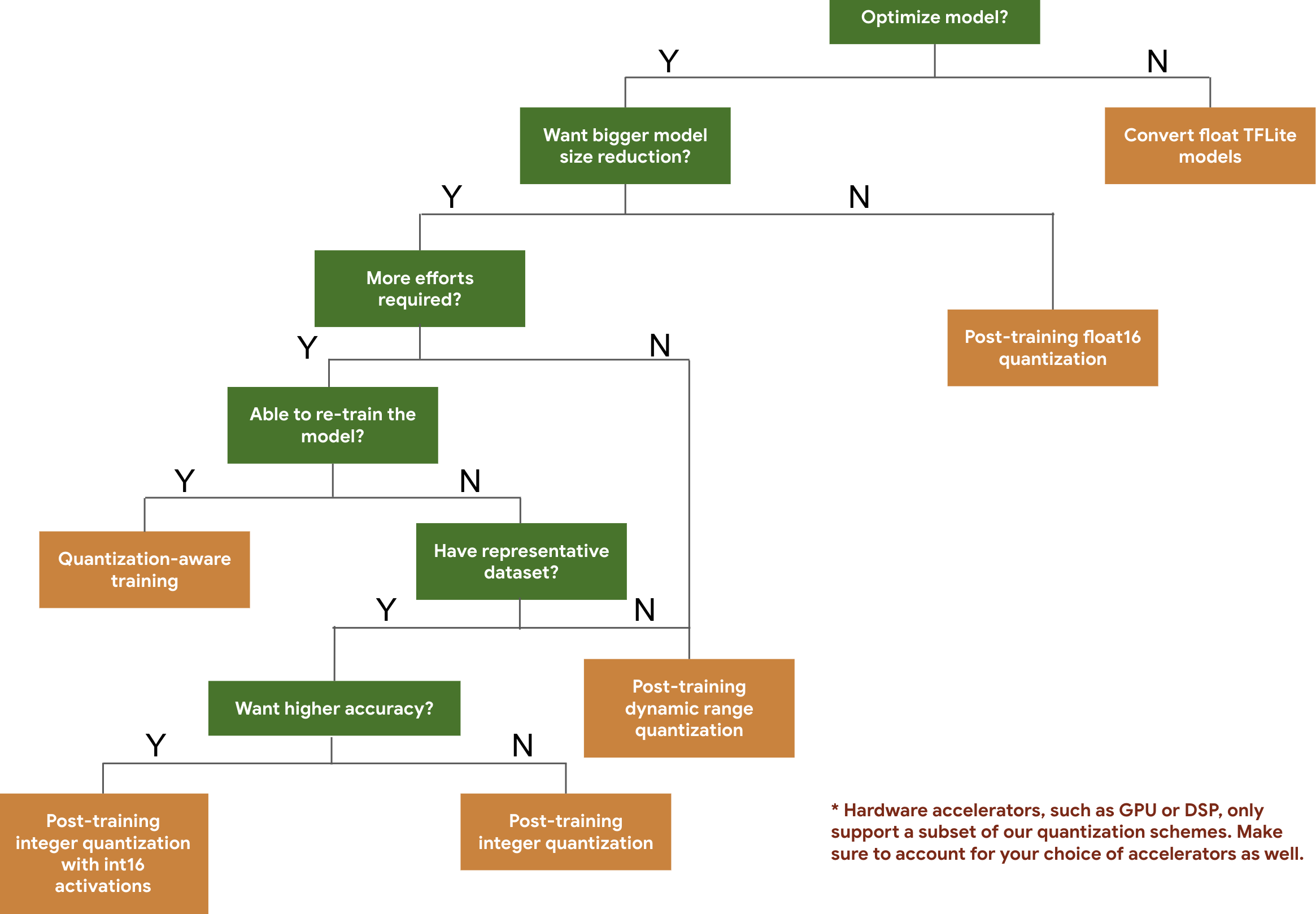
यहां कुछ मॉडल पर, ट्रेनिंग के बाद क्वानटाइज़ेशन और क्वानटाइज़ेशन के बारे में जानकारी देने वाली ट्रेनिंग के लिए, लेटेन्सी और सटीक नतीजे दिए गए हैं. सभी लेटेंसी नंबर, Pixel 2 डिवाइसों पर मेज़र किए जाते हैं. इसके लिए, एक बड़े कोर सीपीयू का इस्तेमाल किया जाता है. टूलकिट में सुधार होने के साथ-साथ, यहां दिए गए आंकड़े भी बेहतर होते जाएंगे:
| मॉडल | टॉप-1 एक्यूरेसी (ओरिजनल) | टॉप-1 ऐक्यूरेसी (ट्रेनिंग के बाद क्वॉन्टाइज़ किया गया) | टॉप-1 ऐक्यूरेसी (क्वांटाइज़ेशन अवेयर ट्रेनिंग) | विलंबता (मूल) (मि॰से॰) | इंतज़ार का समय (ट्रेनिंग के बाद क्वॉन्टाइज़ किया गया) (मि॰से॰) | क्वांटाइज़ेशन अवेयर ट्रेनिंग के दौरान इंतज़ार का समय (मि॰से॰) | साइज़ (ओरिजनल) (एमबी) | साइज़ (ऑप्टिमाइज़ किया गया) (एमबी) |
|---|---|---|---|---|---|---|---|---|
| Mobilenet-v1-1-224 | 0.709 | 0.657 | 0.70 | 124 | 112 | 64 | 16.9 | 4.3 |
| Mobilenet-v2-1-224 | 0.719 | 0.637 | 0.709 | 89 | 98 | 54 | 14 | 3.6 |
| Inception_v3 | 0.78 | 0.772 | 0.775 | 1130 | 845 | 543 | 95.7 | 23.9 |
| Resnet_v2_101 | 0.770 | 0.768 | लागू नहीं | 3973 | 2868 | लागू नहीं | 178.3 | 44.9 |
int16 ऐक्टिवेशन और int8 वेट के साथ फ़ुल इंटिजर क्वांटाइज़ेशन
int16 ऐक्टिवेशन के साथ क्वांटाइज़ेशन, इंटिजर क्वांटाइज़ेशन की पूरी स्कीम है. इसमें int16 में ऐक्टिवेशन और int8 में वेट होते हैं. इस मोड से, क्वॉन्टाइज़ किए गए मॉडल की सटीकता को बेहतर बनाया जा सकता है. इसकी तुलना में, इंट8 में ऐक्टिवेशन और वेट, दोनों के साथ फ़ुल इंटिजर क्वॉन्टाइज़ेशन स्कीम का इस्तेमाल किया जाता है. हालांकि, मॉडल का साइज़ एक जैसा रहता है. इसकी सलाह तब दी जाती है, जब ऐक्टिवेशन, क्वॉन्टाइज़ेशन के लिए संवेदनशील हों.
ध्यान दें: फ़िलहाल, इस क्वानटाइज़ेशन स्कीम के लिए, TFLite में सिर्फ़ नॉन-ऑप्टिमाइज़्ड रेफ़रंस कर्नल उपलब्ध हैं. इसलिए, डिफ़ॉल्ट रूप से परफ़ॉर्मेंस, int8 कर्नल की तुलना में धीमी होगी. फ़िलहाल, इस मोड के सभी फ़ायदों का ऐक्सेस, खास हार्डवेयर या कस्टम सॉफ़्टवेयर के ज़रिए पाया जा सकता है.
यहां कुछ ऐसे मॉडल के नतीजों की सटीक जानकारी दी गई है जिन्हें इस मोड से फ़ायदा मिलता है.
| मॉडल | सटीकता वाली मेट्रिक का टाइप | ऐक्युरसी (float32 ऐक्टिवेशन) | सटीकता (int8 ऐक्टिवेशन) | सटीक (int16 ऐक्टिवेशन) |
|---|---|---|---|---|
| Wav2letter | WER | 6.7% | 7.7% | 7.2% |
| DeepSpeech 0.5.1 (अनरोल्ड) | CER | 6.13% | 43.67% | 6.52% |
| YoloV3 | mAP(IOU=0.5) | 0.577 | 0.563 | 0.574 |
| MobileNetV1 | टॉप-1 ऐक्यूरेसी | 0.7062 | 0.694 | 0.6936 |
| MobileNetV2 | टॉप-1 ऐक्यूरेसी | 0.718 | 0.7126 | 0.7137 |
| MobileBert | F1(एग्ज़ैक्ट मैच) | 88.81(81.23) | 2.08(0) | 88.73(81.15) |
प्रूनिंग
प्रूनिंग की सुविधा, मॉडल में मौजूद उन पैरामीटर को हटाकर काम करती है जिनका अनुमानों पर बहुत कम असर पड़ता है. प्रून किए गए मॉडल का साइज़ डिस्क पर एक जैसा होता है. साथ ही, रनटाइम लेटेन्सी भी एक जैसी होती है. हालांकि, इन्हें ज़्यादा असरदार तरीके से कंप्रेस किया जा सकता है. इसलिए, मॉडल के डाउनलोड साइज़ को कम करने के लिए, प्रूनिंग एक उपयोगी तकनीक है.
आने वाले समय में, LiteRT की मदद से प्रून किए गए मॉडल के लिए लेटेन्सी कम की जा सकेगी.
गुच्छ
क्लस्टरिंग की प्रोसेस में, मॉडल की हर लेयर के वेट को पहले से तय किए गए क्लस्टर की संख्या के हिसाब से ग्रुप किया जाता है. इसके बाद, हर क्लस्टर से जुड़े वेट के लिए सेंट्रॉइड वैल्यू शेयर की जाती हैं. इससे मॉडल में यूनीक वज़न की वैल्यू की संख्या कम हो जाती है. इसलिए, इसकी जटिलता कम हो जाती है.
इस वजह से, क्लस्टर किए गए मॉडल को ज़्यादा असरदार तरीके से कंप्रेस किया जा सकता है. इससे, प्रूनिंग की तरह ही डिप्लॉयमेंट के फ़ायदे मिलते हैं.
डेवलपमेंट वर्कफ़्लो
शुरुआत में, यह देखें कि होस्ट किए गए मॉडल आपके ऐप्लिकेशन के लिए काम कर सकते हैं या नहीं. अगर ऐसा नहीं है, तो हमारा सुझाव है कि उपयोगकर्ता पोस्ट-ट्रेनिंग क्वांटाइज़ेशन टूल का इस्तेमाल शुरू करें. ऐसा इसलिए, क्योंकि यह टूल ज़्यादातर मॉडल पर लागू होता है और इसके लिए ट्रेनिंग डेटा की ज़रूरत नहीं होती.
जिन मामलों में सटीक नतीजे और कम समय में नतीजे पाने के टारगेट पूरे नहीं होते या हार्डवेयर ऐक्सलरेटर की मदद से ट्रेनिंग करना ज़रूरी होता है उनके लिए, क्वांटाइज़ेशन-अवेयर ट्रेनिंग बेहतर विकल्प है. TensorFlow Model Optimization Toolkit में, ऑप्टिमाइज़ेशन की अन्य तकनीकें देखें.
अगर आपको अपने मॉडल का साइज़ और कम करना है, तो मॉडल को क्वांटाइज़ करने से पहले, प्रूनिंग और/या क्लस्टरिंग का इस्तेमाल करें.