
Les appareils de périphérie disposent souvent d'une mémoire ou d'une puissance de calcul limitées. Diverses optimisations peuvent être appliquées aux modèles afin qu'ils puissent être exécutés dans le respect de ces contraintes. De plus, certaines optimisations permettent d'utiliser du matériel spécialisé pour une inférence accélérée.
LiteRT et le kit d'optimisation de modèle TensorFlow fournissent des outils permettant de minimiser la complexité de l'optimisation de l'inférence.
Nous vous recommandons de tenir compte de l'optimisation du modèle lors du processus de développement de votre application. Ce document présente quelques bonnes pratiques pour optimiser les modèles TensorFlow en vue de leur déploiement sur du matériel Edge.
Pourquoi optimiser les modèles ?
L'optimisation des modèles peut aider au développement d'applications de plusieurs manières principales.
Réduction de la taille
Certaines formes d'optimisation peuvent être utilisées pour réduire la taille d'un modèle. Les modèles plus petits présentent les avantages suivants :
- Taille de stockage réduite : les modèles plus petits occupent moins d'espace de stockage sur les appareils de vos utilisateurs. Par exemple, une application Android utilisant un modèle plus petit prendra moins d'espace de stockage sur l'appareil mobile d'un utilisateur.
- Taille de téléchargement réduite : les modèles plus petits nécessitent moins de temps et de bande passante pour être téléchargés sur les appareils des utilisateurs.
- Utilisation réduite de la mémoire : les modèles plus petits utilisent moins de RAM lorsqu'ils sont exécutés, ce qui libère de la mémoire pour d'autres parties de votre application et peut se traduire par de meilleures performances et une meilleure stabilité.
Dans tous ces cas, la quantification peut réduire la taille d'un modèle, potentiellement au détriment de la précision. L'élagage et le clustering peuvent réduire la taille d'un modèle à télécharger en le rendant plus facilement compressible.
Réduction de la latence
La latence correspond au temps nécessaire pour exécuter une seule inférence avec un modèle donné. Certaines formes d'optimisation peuvent réduire la quantité de calcul nécessaire pour exécuter l'inférence à l'aide d'un modèle, ce qui réduit la latence. La latence peut également avoir un impact sur la consommation d'énergie.
Actuellement, la quantification peut être utilisée pour réduire la latence en simplifiant les calculs effectués lors de l'inférence, potentiellement au détriment d'une certaine précision.
Compatibilité des accélérateurs
Certains accélérateurs matériels, tels que l'Edge TPU, peuvent exécuter l'inférence extrêmement rapidement avec des modèles correctement optimisés.
En général, ces types d'appareils nécessitent que les modèles soient quantifiés d'une manière spécifique. Consultez la documentation de chaque accélérateur matériel pour en savoir plus sur ses exigences.
Compromis
Les optimisations peuvent entraîner des modifications de la précision du modèle, qui doivent être prises en compte lors du processus de développement de l'application.
Les changements de précision dépendent du modèle individuel optimisé et sont difficiles à prédire à l'avance. En général, les modèles optimisés pour la taille ou la latence perdent un peu de précision. Selon votre application, cela peut avoir un impact ou non sur l'expérience de vos utilisateurs. Dans de rares cas, certains modèles peuvent gagner en précision grâce au processus d'optimisation.
Types d'optimisation
LiteRT est actuellement compatible avec l'optimisation par quantification, élagage et clustering.
Ces outils font partie du kit d'optimisation de modèles TensorFlow, qui fournit des ressources pour les techniques d'optimisation de modèles compatibles avec TensorFlow Lite.
Quantification
La quantification fonctionne en réduisant la précision des nombres utilisés pour représenter les paramètres d'un modèle, qui sont par défaut des nombres à virgule flottante sur 32 bits. Cela permet de réduire la taille du modèle et d'accélérer les calculs.
Les types de quantification suivants sont disponibles dans LiteRT :
| Technique | Exigences en matière de données | Réduction de la taille | Précision | Matériel compatible |
|---|---|---|---|---|
| Quantification float16 post-entraînement | Aucune donnée | Jusqu'à 50 % | Perte de précision insignifiante | Processeur, GPU |
| Quantification de la plage dynamique post-entraînement | Aucune donnée | Jusqu'à 75 % | Perte de précision la plus faible | Processeur, GPU (Android) |
| Quantification par nombres entiers post-entraînement | Échantillon représentatif non étiqueté | Jusqu'à 75 % | Faible perte de précision | CPU, GPU (Android), EdgeTPU |
| Entraînement tenant compte de la quantification | Données d'entraînement étiquetées | Jusqu'à 75 % | Perte de précision la plus faible | CPU, GPU (Android), EdgeTPU |
L'arbre de décision suivant vous aide à sélectionner les schémas de quantification que vous pourriez vouloir utiliser pour votre modèle, en fonction de la taille et de la précision attendues du modèle.
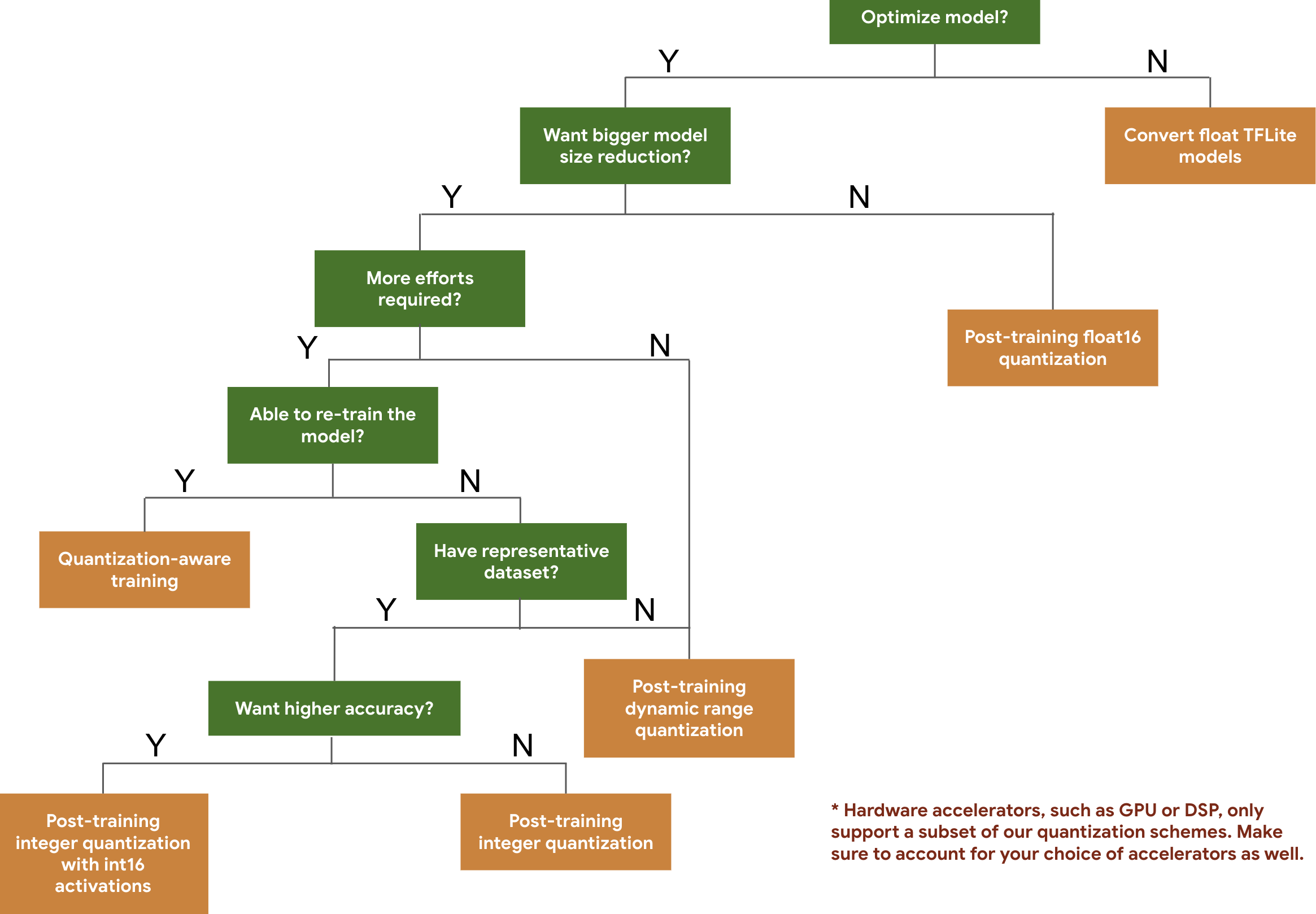
Vous trouverez ci-dessous les résultats de latence et de précision pour la quantification post-entraînement et l'entraînement utilisant la quantification sur quelques modèles. Tous les chiffres de latence sont mesurés sur des appareils Pixel 2 à l'aide d'un seul grand cœur de processeur. À mesure que la boîte à outils s'améliorera, les chiffres suivants augmenteront :
| Modèle | Justesse Top-1 (originale) | Justesse Top-1 (quantifiée post-entraînement) | Justesse Top-1 (entraînement utilisant la quantification) | Latence (d'origine) (ms) | Latence (quantifiée après l'entraînement) (ms) | Latence (entraînement utilisant la quantification) (ms) | Taille (d'origine) (Mo) | Taille (optimisée) (Mo) |
|---|---|---|---|---|---|---|---|---|
| Mobilenet-v1-1-224 | 0,709 | 0.657 | 0.70 | 124 | 112 | 64 | 16.9 | 4.3 |
| Mobilenet-v2-1-224 | 0.719 | 0.637 | 0,709 | 89 | 98 | 54 | 14 | 3.6 |
| Inception_v3 | 0.78 | 0.772 | 0,775 | 1130 | 845 | 543 | 95,7 | 23.9 |
| Resnet_v2_101 | 0.770 | 0.768 | N/A | 3973 | 2868 | N/A | 178.3 | 44.9 |
Quantification par nombres entiers avec activations int16 et pondérations int8
La quantification avec activations int16 est un schéma de quantification par nombres entiers complet avec des activations en int16 et des pondérations en int8. Ce mode peut améliorer la précision du modèle quantifié par rapport au schéma de quantification d'entiers complet avec des activations et des poids en int8 tout en conservant une taille de modèle similaire. Il est recommandé lorsque les activations sont sensibles à la quantification.
REMARQUE : Actuellement, seules les implémentations de noyaux de référence non optimisées sont disponibles dans TFLite pour ce schéma de quantification. Par conséquent, les performances seront lentes par défaut par rapport aux noyaux int8. Pour profiter pleinement de ce mode, vous devez actuellement utiliser du matériel spécialisé ou un logiciel personnalisé.
Vous trouverez ci-dessous les résultats de précision de certains modèles qui bénéficient de ce mode.
| Modèle | Type de métrique de précision | Précision (activations float32) | Précision (activations int8) | Précision (activations int16) |
|---|---|---|---|---|
| Wav2letter | Taux d'erreur sur les mots | 6,7 % | 7,7 % | 7,2 % |
| DeepSpeech 0.5.1 (déroulé) | CER | 6,13 % | 43,67 % | 6,52 % |
| YoloV3 | mAP(IOU=0.5) | 0.577 | 0,563 | 0.574 |
| MobileNetV1 | Justesse Top-1 | 0.7062 | 0,694 | 0.6936 |
| MobileNetV2 | Justesse Top-1 | 0.718 | 0.7126 | 0.7137 |
| MobileBert | F1(correspondance exacte) | 88,81(81,23) | 2.08(0) | 88,73(81,15) |
Élagage
L'élagage consiste à supprimer les paramètres d'un modèle qui n'ont qu'un impact mineur sur ses prédictions. Les modèles élagués ont la même taille sur le disque et la même latence d'exécution, mais peuvent être compressés plus efficacement. L'élagage est donc une technique utile pour réduire la taille de téléchargement des modèles.
À l'avenir, LiteRT permettra de réduire la latence des modèles élagués.
Clustering
Le clustering fonctionne en regroupant les poids de chaque couche d'un modèle dans un nombre prédéfini de clusters, puis en partageant les valeurs de centroïde pour les poids appartenant à chaque cluster individuel. Cela réduit le nombre de valeurs de poids uniques dans un modèle, ce qui réduit sa complexité.
Par conséquent, les modèles regroupés peuvent être compressés plus efficacement, ce qui offre des avantages de déploiement similaires à l'élagage.
Workflow de développement
Pour commencer, vérifiez si les modèles dans modèles hébergés peuvent fonctionner pour votre application. Sinon, nous recommandons aux utilisateurs de commencer par l'outil de quantification post-entraînement, car il est largement applicable et ne nécessite pas de données d'entraînement.
Dans les cas où les cibles de précision et de latence ne sont pas atteintes, ou lorsque la prise en charge de l'accélérateur matériel est importante, l'entraînement tenant compte de la quantification est la meilleure option. Pour découvrir d'autres techniques d'optimisation, consultez le kit d'optimisation de modèles TensorFlow.
Si vous souhaitez réduire davantage la taille de votre modèle, vous pouvez essayer l'élagage et/ou le clustering avant de quantifier vos modèles.