
モデルで使用する ML オペレータは、TensorFlow モデルを LiteRT 形式に変換するプロセスに影響する可能性があります。LiteRT コンバータは、一般的な推論モデルで使用される TensorFlow オペレーションの一部しかサポートしていません。そのため、すべてのモデルを直接変換できるわけではありません。コンバータ ツールを使用すると、追加の演算子を含めることができますが、この方法でモデルを変換するには、モデルの実行に使用する LiteRT ランタイム環境を変更する必要もあります。これにより、Google Play 開発者サービスなどの標準のランタイム デプロイ オプションを使用する機能が制限される可能性があります。
LiteRT Converter は、モデル構造を分析し、直接サポートされているオペレーターと互換性を持たせるために最適化を適用するように設計されています。たとえば、モデル内の ML 演算子によっては、コンバータがそれらの演算子を 省略または融合して、LiteRT の対応する演算子にマッピングすることがあります。
サポートされているオペレーションでも、パフォーマンス上の理由から、特定の使用パターンが想定されることがあります。LiteRT で使用できる TensorFlow モデルを構築する方法を理解するには、オペレーションがどのように変換および最適化されるか、またこのプロセスによって課せられる制限について慎重に検討することが重要です。
サポートされている演算子
LiteRT の組み込み演算子は、TensorFlow コア ライブラリの一部である演算子のサブセットです。TensorFlow モデルには、複合演算子やユーザーが定義した新しい演算子などのカスタム演算子が含まれている場合もあります。次の図は、これらの演算子の関係を示しています。
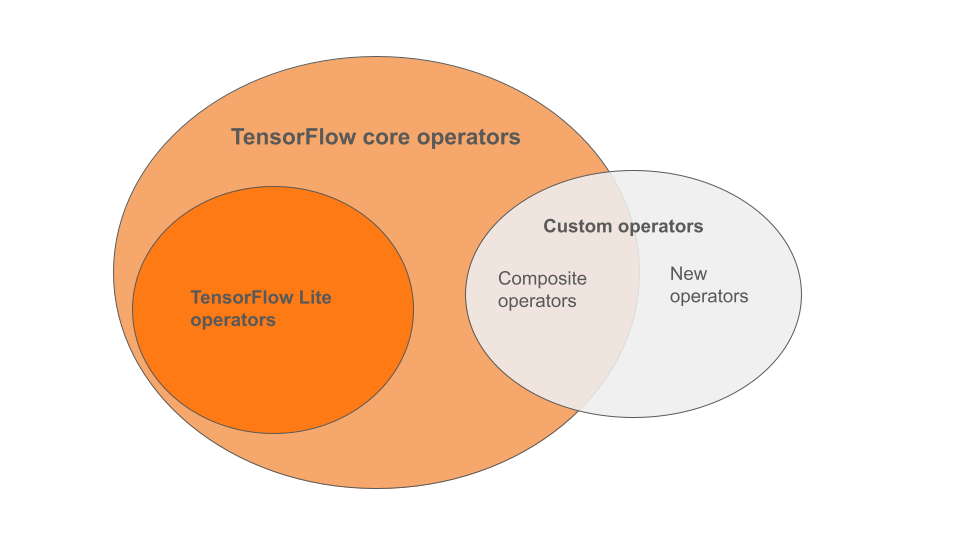
この ML モデル オペレーターの範囲には、変換プロセスでサポートされている 3 種類のモデルがあります。
- LiteRT 組み込み演算子のみを含むモデル。(推奨)
- 組み込み演算子と選択した TensorFlow コア演算子を含むモデル。
- 組み込み演算子、TensorFlow コア演算子、カスタム演算子を含むモデル。
モデルに LiteRT でネイティブにサポートされているオペレーションのみが含まれている場合、変換に追加のフラグは必要ありません。このタイプのモデルはスムーズに変換され、デフォルトの LiteRT ランタイムを使用して最適化と実行が簡単になるため、このパスが推奨されます。また、Google Play 開発者サービスなど、モデルのデプロイ オプションも増えます。LiteRT コンバータ ガイドをご覧ください。組み込みオペレーターのリストについては、LiteRT Ops ページをご覧ください。
コア ライブラリから特定の TensorFlow オペレーションを含める必要がある場合は、変換時にそれを指定し、ランタイムにそれらのオペレーションが含まれていることを確認する必要があります。詳細な手順については、TensorFlow 演算子を選択するをご覧ください。
可能な限り、変換されたモデルにカスタム オペレーターを含めるという最後のオプションは避けてください。カスタム オペレータは、複数のプリミティブ TensorFlow コア オペレータを組み合わせて作成されたオペレータか、完全に新しいオペレータとして定義されたオペレータです。カスタム オペレーターを変換すると、組み込みの LiteRT ライブラリ外の依存関係が発生し、モデル全体のサイズが増加する可能性があります。カスタム オペレーションは、モバイルやデバイスのデプロイ用に特別に作成されていない場合、リソースが制約されたデバイスにデプロイすると、サーバー環境と比較してパフォーマンスが低下する可能性があります。最後に、選択した TensorFlow コア オペレーターを含める場合と同様に、カスタム オペレーターを使用するには、モデルのランタイム環境を変更する必要があります。これにより、Google Play 開発者サービスなどの標準ランタイム サービスを利用できなくなります。
サポートされているタイプ
ほとんどの LiteRT オペレーションは、浮動小数点(float32)と量子化(uint8、int8)の両方の推論を対象としていますが、tf.float16 や文字列などの他の型では、まだ多くのオペレーションが対象外です。
浮動小数点モデルと量子化モデルの違いは、オペレーションのバージョンが異なること以外に、変換方法も異なります。量子化された変換には、テンソルの動的範囲情報が必要です。これには、モデル トレーニング中の「偽量子化」、キャリブレーション データセットによる範囲情報の取得、または「オンザフライ」範囲推定が必要です。詳細については、量子化をご覧ください。
単純な変換、定数畳み込みと融合
直接的な同等物がない場合でも、多くの TensorFlow オペレーションを LiteRT で処理できます。これは、グラフから簡単に削除できるオペレーション(tf.identity)、テンソルに置き換えられるオペレーション(tf.placeholder)、より複雑なオペレーションに統合されるオペレーション(tf.nn.bias_add)に当てはまります。サポートされているオペレーションの一部も、これらのプロセスのいずれかによって削除されることがあります。
通常、グラフから削除される TensorFlow オペレーションの例を以下に示します。
tf.addtf.debugging.check_numericstf.constanttf.divtf.dividetf.fake_quant_with_min_max_argstf.fake_quant_with_min_max_varstf.identitytf.maximumtf.minimumtf.multiplytf.no_optf.placeholdertf.placeholder_with_defaulttf.realdivtf.reduce_maxtf.reduce_mintf.reduce_sumtf.rsqrttf.shapetf.sqrttf.squaretf.subtracttf.tiletf.nn.batch_norm_with_global_normalizationtf.nn.bias_addtf.nn.fused_batch_normtf.nn.relutf.nn.relu6
試験運用版のオペレーション
次の LiteRT オペレーションは存在しますが、カスタムモデルの準備ができていません。
CALLCONCAT_EMBEDDINGSCUSTOMEMBEDDING_LOOKUP_SPARSEHASHTABLE_LOOKUPLSH_PROJECTIONSKIP_GRAMSVDF