
קוונטיזציה אחרי אימון היא טכניקת המרה שיכולה להקטין את גודל המודל, וגם לשפר את זמן האחזור של המעבד ומאיץ החומרה, עם פגיעה קלה בדיוק של המודל. אפשר לכמת מודל TensorFlow מסוג float שכבר אומן, כשממירים אותו לפורמט LiteRT באמצעות LiteRT Converter.
שיטות אופטימיזציה
יש כמה אפשרויות לכמת את המודל אחרי האימון. בטבלה הבאה מפורטות האפשרויות והיתרונות שלהן:
| טכניקה | יתרונות | חומרה |
|---|---|---|
| קוונטיזציה של טווח דינמי | קטן פי 4, מהיר פי 2 עד פי 3 | CPU |
| קוונטיזציה מלאה של מספרים שלמים | קטן פי 4, מהיר פי 3 ויותר | CPU, Edge TPU, מיקרו-בקרים |
| כימות Float16 | קטן פי 2, האצת GPU | מעבד, GPU |
עץ ההחלטות הבא יכול לעזור לכם לקבוע איזו שיטת קוונטיזציה אחרי אימון הכי מתאימה לתרחיש השימוש שלכם:
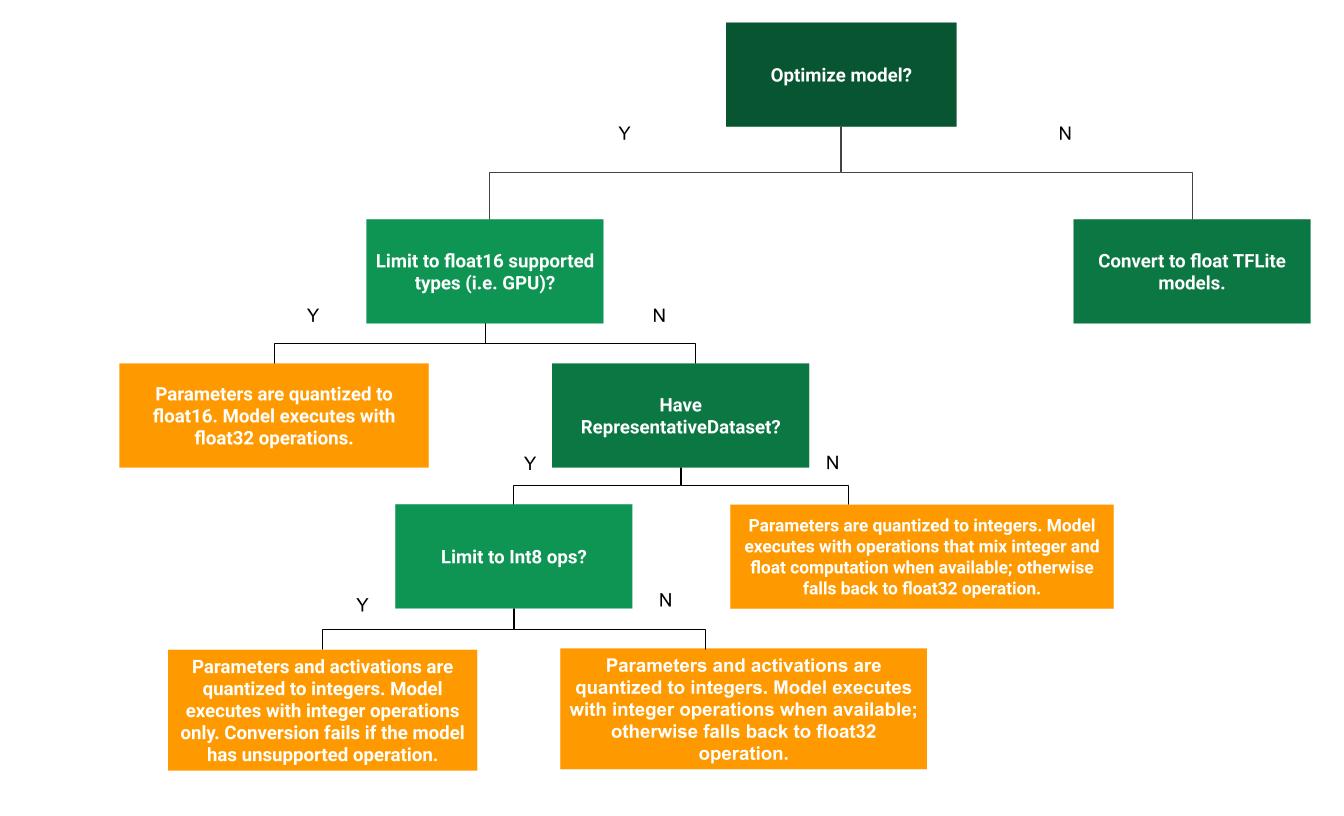
ללא קוונטיזציה
נקודת התחלה מומלצת היא המרה למודל TFLite בלי כימות. הפעולה הזו תיצור מודל TFLite מסוג float.
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) tflite_quant_model = converter.convert()
מומלץ לבצע את הפעולה הזו כשלב ראשוני כדי לוודא שהאופרטורים של מודל TF המקורי תואמים ל-TFLite, וגם כדי להשתמש בה כנקודת התייחסות לניפוי שגיאות קוונטיזציה שנובעות משיטות קוונטיזציה שמתבצעות אחרי האימון. לדוגמה, אם מודל TFLite שעבר קוונטיזציה מפיק תוצאות לא צפויות, אבל מודל TFLite עם נקודה צפה מדויק, אפשר לצמצם את הבעיה לשגיאות שנוצרו על ידי הגרסה שעברה קוונטיזציה של אופרטורים של TFLite.
קוונטיזציה של טווח דינמי
כימות טווח דינמי מספק שימוש מופחת בזיכרון וחישוב מהיר יותר, בלי שתצטרכו לספק מערך נתונים מייצג לכיול. בסוג הזה של קוונטיזציה, רק המשקלים מומרים מנקודה צפה למספר שלם בזמן ההמרה, והדיוק הוא 8 ביט:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] tflite_quant_model = converter.convert()
כדי להקטין עוד יותר את זמן האחזור במהלך ההסקה, אופרטורים של 'טווח דינמי' מבצעים קוונטיזציה דינמית של הפעלות על סמך הטווח שלהן ל-8 ביט, ומבצעים חישובים עם משקלים והפעלות של 8 ביט. האופטימיזציה הזו מספקת השהיות שקרובות להסקת מסקנות בנקודות קבועות לחלוטין. עם זאת, הפלט עדיין מאוחסן באמצעות נקודה צפה, כך שהמהירות המוגברת של פעולות טווח דינמי נמוכה מחישוב מלא של נקודה קבועה.
כימות מלא של מספרים שלמים
כדי לשפר עוד יותר את זמן האחזור, להקטין את השימוש בזיכרון בשיא ולשפר את התאימות למאיצי חומרה או למכשירי חומרה שמקבלים רק מספרים שלמים, צריך לוודא שכל החישובים במודל הם של מספרים שלמים.
כדי לבצע כימות של מספרים שלמים, צריך לכייל או להעריך את הטווח,
כלומר, (min, max) of all floating-point tensors in the model. בניגוד לטנסורים קבועים כמו משקלים והטיות, אי אפשר לכייל טנסורים משתנים כמו קלט המודל, הפעלות (פלט של שכבות ביניים) ופלט המודל, אלא אם מריצים כמה מחזורי הסקה. לכן, כדי לכייל את המודלים, הממיר צריך מערך נתונים מייצג. מערך הנתונים הזה יכול להיות קבוצת משנה קטנה (בערך 100-500 דוגמאות) של נתוני האימון או האימות. מידע נוסף זמין בפונקציה representative_dataset() שבהמשך.
החל מגרסה TensorFlow 2.7, אפשר לציין את מערך הנתונים המייצג באמצעות חתימה כמו בדוגמה הבאה:
def representative_dataset():
for data in dataset:
yield {
"image": data.image,
"bias": data.bias,
}
אם יש יותר מחתימה אחת במודל TensorFlow שצוין, אפשר לציין את מערך הנתונים המרובה על ידי ציון מפתחות החתימה:
def representative_dataset():
# Feed data set for the "encode" signature.
for data in encode_signature_dataset:
yield (
"encode", {
"image": data.image,
"bias": data.bias,
}
)
# Feed data set for the "decode" signature.
for data in decode_signature_dataset:
yield (
"decode", {
"image": data.image,
"hint": data.hint,
},
)
אפשר ליצור את מערך הנתונים המייצג על ידי ציון רשימה של טנסורים לקלט:
def representative_dataset():
for data in tf.data.Dataset.from_tensor_slices((images)).batch(1).take(100):
yield [tf.dtypes.cast(data, tf.float32)]
החל מגרסה TensorFlow 2.7, אנחנו ממליצים להשתמש בגישה שמבוססת על חתימה במקום בגישה שמבוססת על רשימת טנסורים של קלט, כי אפשר בקלות להפוך את הסדר של טנסור הקלט.
לצורך בדיקה, אפשר להשתמש במערך נתונים פיקטיבי באופן הבא:
def representative_dataset():
for _ in range(100):
data = np.random.rand(1, 244, 244, 3)
yield [data.astype(np.float32)]
מספר שלם עם חזרה לערך צף (באמצעות קלט/פלט צף שמוגדר כברירת מחדל)
כדי לבצע קוונטיזציה מלאה של מספרים שלמים במודל, אבל להשתמש באופרטורים של מספרים עשרוניים כשאין להם הטמעה של מספרים שלמים (כדי להבטיח שההמרה תתבצע בצורה חלקה), צריך לבצע את השלבים הבאים:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.representative_dataset = representative_dataset tflite_quant_model = converter.convert()
מספר שלם בלבד
יצירת מודלים של מספרים שלמים בלבד היא תרחיש נפוץ לשימוש ב-LiteRT for Microcontrollers וב-Coral Edge TPUs.
בנוסף, כדי להבטיח תאימות למכשירים עם מספרים שלמים בלבד (כמו מיקרו-בקרים של 8 ביט) ומאיצים (כמו Coral Edge TPU), אפשר לאכוף כימות של מספרים שלמים מלאים לכל הפעולות, כולל הקלט והפלט, באמצעות השלבים הבאים:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.representative_dataset = representative_dataset converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8] converter.inference_input_type = tf.int8 # or tf.uint8 converter.inference_output_type = tf.int8 # or tf.uint8 tflite_quant_model = converter.convert()
כימות Float16
כדי להקטין את הגודל של מודל נקודה צפה, אפשר לכמת את המשקלים ל-float16, התקן של IEEE למספרים של נקודה צפה עם 16 ביט. כדי להפעיל קוונטיזציה של משקלים מסוג float16, פועלים לפי השלבים הבאים:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.target_spec.supported_types = [tf.float16] tflite_quant_model = converter.convert()
היתרונות של קוונטיזציה מסוג float16 הם:
- היא מקטינה את גודל המודל עד למחצית (כי כל המשקלים הופכים למחצית מהגודל המקורי שלהם).
- היא גורמת לאובדן מינימלי של דיוק.
- הוא תומך בחלק מהנציגים (למשל, נציג ה-GPU) שיכולים לפעול ישירות על נתוני float16, וכך להשיג ביצוע מהיר יותר מאשר חישובי float32.
החסרונות של קוונטיזציה מסוג float16 הם:
- היא לא מפחיתה את זמן האחזור כמו קוונטיזציה למתמטיקה של נקודה קבועה.
- כברירת מחדל, מודל שעבר קוונטיזציה מסוג float16 יבצע "דה-קוונטיזציה" של ערכי המשקלים ל-float32 כשהוא יופעל ב-CPU. (שימו לב: נציג ה-GPU לא יבצע את ביטול הכימות הזה, כי הוא יכול לפעול על נתוני float16).
מספר שלם בלבד: הפעלות של 16 ביט עם משקלים של 8 ביט (ניסיוני)
זוהי סכמת כימות ניסיונית. היא דומה לתוכנית 'מספרים שלמים בלבד', אבל הפעלות עוברות קוונטיזציה על סמך הטווח שלהן ל-16 ביט, משקלים עוברים קוונטיזציה למספר שלם של 8 ביט והטיה עוברת קוונטיזציה למספר שלם של 64 ביט. התהליך הזה נקרא קוונטיזציה של 16x8.
היתרון העיקרי של הכמותיות הזו הוא שהיא יכולה לשפר את הדיוק באופן משמעותי, אבל רק להגדיל מעט את גודל המודל.
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.representative_dataset = representative_dataset converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.target_spec.supported_ops = [tf.lite.OpsSet.EXPERIMENTAL_TFLITE_BUILTINS_ACTIVATIONS_INT16_WEIGHTS_INT8] tflite_quant_model = converter.convert()
אם כימות 16x8 לא נתמך עבור חלק מהאופרטורים במודל, עדיין אפשר לכמת את המודל, אבל האופרטורים שלא נתמכים נשארים בפורמט float. כדי לאפשר את זה, צריך להוסיף את האפשרות הבאה ל-target_spec.
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.representative_dataset = representative_dataset converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.target_spec.supported_ops = [tf.lite.OpsSet.EXPERIMENTAL_TFLITE_BUILTINS_ACTIVATIONS_INT16_WEIGHTS_INT8, tf.lite.OpsSet.TFLITE_BUILTINS] tflite_quant_model = converter.convert()
דוגמאות לתרחישי שימוש שבהם שיפורי הדיוק שמתקבלים באמצעות תוכנית הכימות הזו כוללים:
- סופר-רזולוציה,
- עיבוד אותות אודיו, כמו סינון רעשים ועיצוב אלומה,
- הסרת רעשים מתמונות,
- שחזור HDR מתמונה אחת.
החיסרון של הכימות הזה הוא:
- נכון לעכשיו, ההסקה איטית באופן ניכר בהשוואה להסקה של מספרים שלמים מלאים בני 8 ביט, בגלל חוסר בהטמעה של ליבת מערכת אופטימלית.
- בשלב הזה, הוא לא תואם לנציגי TFLite קיימים עם האצת חומרה.
כאן אפשר למצוא הדרכה על מצב הכימות הזה.
מידת הדיוק של המודל
מכיוון שהמשקלים עוברים קוונטיזציה אחרי האימון, יכול להיות שתהיה ירידה ברמת הדיוק, במיוחד ברשתות קטנות יותר. מודלים שעברו אימון מראש וקוונטיזציה מלאה מסופקים לרשתות ספציפיות ב-Kaggle Models. חשוב לבדוק את רמת הדיוק של המודל שעבר קוונטיזציה כדי לוודא שכל ירידה ברמת הדיוק נמצאת בגבולות המקובלים. יש כלים להערכת הדיוק של מודל LiteRT.
לחלופין, אם ירידת הדיוק גבוהה מדי, כדאי להשתמש באימון עם התחשבות בקוונטיזציה. עם זאת, כדי לעשות זאת צריך לבצע שינויים במהלך אימון המודל כדי להוסיף צמתי קוונטיזציה מזויפים, בעוד ששיטות הקוונטיזציה אחרי האימון שמתוארות בדף הזה משתמשות במודל קיים שעבר אימון מקדים.
ייצוג של טנסורים שעברו קוונטיזציה
קוונטיזציה של 8 ביט מחשבת ערכים של נקודה צפה באמצעות הנוסחה הבאה.
\[real\_value = (int8\_value - zero\_point) \times scale\]
הייצוג כולל שני חלקים עיקריים:
משקלים לכל ציר (כלומר לכל ערוץ) או לכל טנזור שמיוצגים על ידי ערכי int8 בשיטת המשלים ל-2 בטווח [-127, 127] עם נקודת אפס ששווה ל-0.
הפעלות/קלט לכל טנסור שמיוצגים על ידי ערכי int8 בשיטת המשלים ל-2 בטווח [-128, 127], עם נקודת אפס בטווח [-128, 127].
במפרט הכמותי שלנו מפורטות שיטות הכימות. ספקי חומרה שרוצים להתחבר לממשק ההעברה של TensorFlow Lite מוזמנים להטמיע את שיטת הכימות שמתוארת שם.