
Kwantyzacja po trenowaniu to technika konwersji, która może zmniejszyć rozmiar modelu, a także skrócić czas oczekiwania procesora i akceleratora sprzętowego przy niewielkim pogorszeniu dokładności modelu. Możesz skwantyzować wytrenowany już model TensorFlow w formacie zmiennoprzecinkowym, gdy przekonwertujesz go na format LiteRT za pomocą konwertera LiteRT.
Metody optymalizacji
Do wyboru jest kilka opcji kwantyzacji po trenowaniu. Poniżej znajdziesz tabelę podsumowującą dostępne opcje i ich zalety:
| Metoda | Zalety | Sprzęt |
|---|---|---|
| Kwantyzacja zakresu dynamicznego | 4-krotnie mniejszy rozmiar, 2–3-krotnie większa szybkość | CPU |
| Pełna kwantyzacja liczb całkowitych | 4-krotnie mniejszy rozmiar, ponad 3-krotne przyspieszenie | Procesor, Edge TPU, Mikrokontrolery |
| Kwantyzacja Float16 | 2 razy mniejszy, akceleracja GPU | CPU, GPU |
Ten schemat decyzyjny pomoże Ci określić, która metoda kwantyzacji po trenowaniu jest najlepsza w Twoim przypadku:
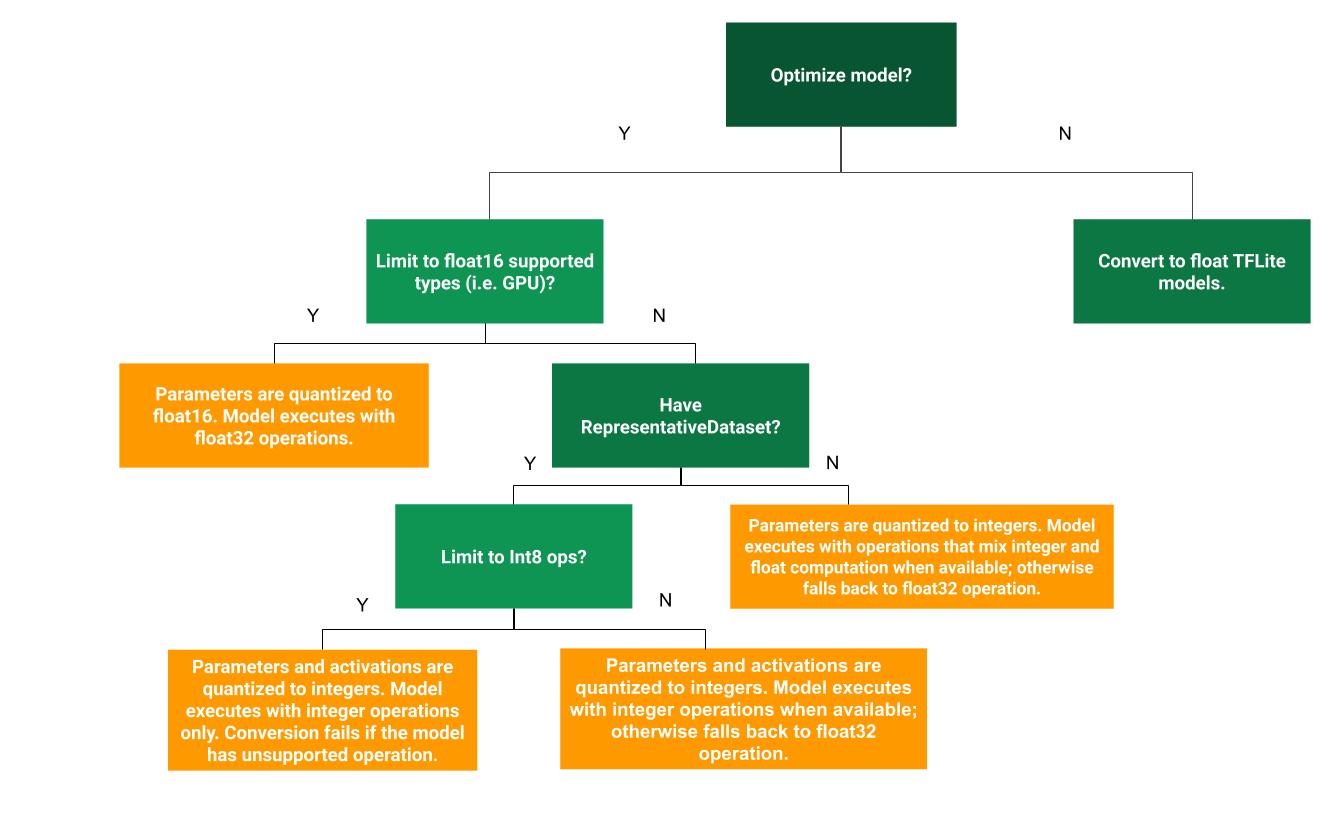
Bez kwantyzacji
Zalecamy rozpoczęcie od przekonwertowania modelu na model TFLite bez kwantyzacji. Spowoduje to wygenerowanie modelu TFLite z liczbami zmiennoprzecinkowymi.
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) tflite_quant_model = converter.convert()
Zalecamy wykonanie tego kroku na początku, aby sprawdzić, czy operatory oryginalnego modelu TF są zgodne z TFLite. Można go też użyć jako punktu odniesienia do debugowania błędów kwantyzacji wprowadzonych przez kolejne metody kwantyzacji po trenowaniu. Jeśli na przykład skwantyzowany model TFLite daje nieoczekiwane wyniki, a model TFLite z liczbami zmiennoprzecinkowymi jest dokładny, możemy zawęzić problem do błędów wprowadzonych przez skwantyzowaną wersję operatorów TFLite.
Kwantyzacja zakresu dynamicznego
Kwantyzacja zakresu dynamicznego zapewnia mniejsze zużycie pamięci i szybsze obliczenia bez konieczności dostarczania reprezentatywnego zbioru danych do kalibracji. Ten rodzaj kwantyzacji statycznie kwantyzuje tylko wagi z liczby zmiennoprzecinkowej na liczbę całkowitą w momencie konwersji, co zapewnia 8-bitową precyzję:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] tflite_quant_model = converter.convert()
Aby jeszcze bardziej skrócić czas oczekiwania podczas wnioskowania, operatory „dynamic-range” dynamicznie kwantyzują aktywacje na podstawie ich zakresu do 8 bitów i wykonują obliczenia z 8-bitowymi wagami i aktywacjami. Ta optymalizacja zapewnia opóźnienia zbliżone do opóźnień w przypadku wnioskowania w pełni opartego na liczbach stałoprzecinkowych. Dane wyjściowe są jednak nadal przechowywane w formacie zmiennoprzecinkowym, więc zwiększona szybkość operacji na zakresie dynamicznym jest mniejsza niż w przypadku pełnych obliczeń w formacie stałoprzecinkowym.
Kwantyzacja liczb całkowitych
Możesz dodatkowo skrócić czas oczekiwania, zmniejszyć maksymalne wykorzystanie pamięci i zapewnić zgodność z urządzeniami lub akceleratorami obsługującymi tylko liczby całkowite, jeśli upewnisz się, że wszystkie obliczenia w modelu są skwantowane do liczb całkowitych.
W przypadku pełnej kwantyzacji liczb całkowitych musisz skalibrować lub oszacować zakres, tzn. (min, max) wszystkich tensorów zmiennoprzecinkowych w modelu. W przeciwieństwie do tensorów stałych, takich jak wagi i odchylenia, tensorów zmiennych, takich jak dane wejściowe modelu, aktywacje (dane wyjściowe warstw pośrednich) i dane wyjściowe modelu, nie można skalibrować, dopóki nie przeprowadzimy kilku cykli wnioskowania. W rezultacie konwerter wymaga reprezentatywnego zbioru danych do kalibracji. Ten zbiór danych może być małym podzbiorem (około 100–500 próbek) danych treningowych lub walidacyjnych. Zapoznaj się z funkcją representative_dataset() poniżej.
Od wersji TensorFlow 2.7 możesz określić reprezentatywny zbiór danych za pomocą sygnatury, jak w tym przykładzie:
def representative_dataset():
for data in dataset:
yield {
"image": data.image,
"bias": data.bias,
}
Jeśli w danym modelu TensorFlow jest więcej niż jeden podpis, możesz określić wiele zbiorów danych, podając klucze podpisu:
def representative_dataset():
# Feed data set for the "encode" signature.
for data in encode_signature_dataset:
yield (
"encode", {
"image": data.image,
"bias": data.bias,
}
)
# Feed data set for the "decode" signature.
for data in decode_signature_dataset:
yield (
"decode", {
"image": data.image,
"hint": data.hint,
},
)
Reprezentatywny zbiór danych możesz wygenerować, podając listę tensorów wejściowych:
def representative_dataset():
for data in tf.data.Dataset.from_tensor_slices((images)).batch(1).take(100):
yield [tf.dtypes.cast(data, tf.float32)]
Od wersji TensorFlow 2.7 zalecamy korzystanie z metody opartej na sygnaturze zamiast metody opartej na liście tensorów wejściowych, ponieważ kolejność tensorów wejściowych można łatwo odwrócić.
Na potrzeby testów możesz użyć przykładowego zbioru danych w ten sposób:
def representative_dataset():
for _ in range(100):
data = np.random.rand(1, 244, 244, 3)
yield [data.astype(np.float32)]
Liczba całkowita z wartością zmiennoprzecinkową (z użyciem domyślnych danych wejściowych/wyjściowych typu float)
Aby w pełni skwantyzować model do liczb całkowitych, ale używać operatorów zmiennoprzecinkowych, gdy nie mają one implementacji w postaci liczb całkowitych (aby zapewnić płynne przekształcenie), wykonaj te czynności:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.representative_dataset = representative_dataset tflite_quant_model = converter.convert()
Tylko liczby całkowite
Tworzenie modeli wykorzystujących tylko liczby całkowite jest typowym przypadkiem użycia LiteRT dla mikrokontrolerów i Coral Edge TPU.
Aby zapewnić zgodność z urządzeniami obsługującymi tylko liczby całkowite (np. 8-bitowymi mikrokontrolerami) i akceleratorami (np. Coral Edge TPU), możesz wymusić pełną kwantyzację liczb całkowitych dla wszystkich operacji, w tym danych wejściowych i wyjściowych, wykonując te czynności:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.representative_dataset = representative_dataset converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8] converter.inference_input_type = tf.int8 # or tf.uint8 converter.inference_output_type = tf.int8 # or tf.uint8 tflite_quant_model = converter.convert()
Kwantyzacja Float16
Rozmiar modelu zmiennoprzecinkowego możesz zmniejszyć, kwantyzując wagi do formatu float16, czyli standardu IEEE dla 16-bitowych liczb zmiennoprzecinkowych. Aby włączyć kwantyzację wag w formacie float16, wykonaj te czynności:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.target_spec.supported_types = [tf.float16] tflite_quant_model = converter.convert()
Zalety kwantyzacji float16:
- Zmniejsza rozmiar modelu nawet o połowę (ponieważ wszystkie wagi stają się o połowę mniejsze niż pierwotnie).
- Powoduje to minimalną utratę dokładności.
- Obsługuje niektóre delegaty (np. delegat GPU), które mogą działać bezpośrednio na danych float16, co zapewnia szybsze wykonywanie niż obliczenia float32.
Wady kwantyzacji float16 są następujące:
- Nie zmniejsza ona czasu oczekiwania w takim stopniu jak kwantyzacja do obliczeń na liczbach stałoprzecinkowych.
- Domyślnie model skwantyzowany do formatu float16 „dekwantyzuje” wartości wag do formatu float32, gdy jest uruchamiany na procesorze. (Pamiętaj, że delegat GPU nie przeprowadzi tego odkwantyzowania, ponieważ może działać na danych float16).
Tylko liczby całkowite: aktywacje 16-bitowe z wagami 8-bitowymi (eksperymentalne)
Jest to eksperymentalny schemat kwantyzacji. Jest ona podobna do schematu „tylko liczby całkowite”, ale aktywacje są kwantyzowane na podstawie ich zakresu do 16 bitów, wagi są kwantyzowane do 8-bitowych liczb całkowitych, a wartości progowe są kwantyzowane do 64-bitowych liczb całkowitych. Będziemy to dalej nazywać kwantyzacją 16x8.
Główną zaletą tej kwantyzacji jest to, że może ona znacznie poprawić dokładność, a jednocześnie tylko nieznacznie zwiększyć rozmiar modelu.
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.representative_dataset = representative_dataset converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.target_spec.supported_ops = [tf.lite.OpsSet.EXPERIMENTAL_TFLITE_BUILTINS_ACTIVATIONS_INT16_WEIGHTS_INT8] tflite_quant_model = converter.convert()
Jeśli kwantyzacja 16x8 nie jest obsługiwana w przypadku niektórych operatorów w modelu, model nadal może być kwantyzowany, ale nieobsługiwani operatorzy są przechowywani w formacie zmiennoprzecinkowym. Aby to umożliwić, do parametru target_spec należy dodać tę opcję:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.representative_dataset = representative_dataset converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.target_spec.supported_ops = [tf.lite.OpsSet.EXPERIMENTAL_TFLITE_BUILTINS_ACTIVATIONS_INT16_WEIGHTS_INT8, tf.lite.OpsSet.TFLITE_BUILTINS] tflite_quant_model = converter.convert()
Przykłady przypadków użycia, w których poprawa dokładności dzięki temu schematowi kwantyzacji jest szczególnie widoczna:
- superrozdzielczość,
- przetwarzanie sygnału audio, np. wyciszanie szumów i formowanie wiązki;
- odszumianie obrazu,
- Rekonstrukcja HDR z jednego obrazu.
Wadą tej kwantyzacji jest:
- Obecnie wnioskowanie jest znacznie wolniejsze niż w przypadku 8-bitowych liczb całkowitych ze względu na brak zoptymalizowanej implementacji jądra.
- Obecnie jest on niezgodny z istniejącymi delegatami TFLite akcelerowanymi sprzętowo.
Samouczek dotyczący tego trybu kwantyzacji znajdziesz tutaj.
Dokładność modelu
Wagi są kwantyzowane po wytrenowaniu, więc może wystąpić utrata dokładności, zwłaszcza w przypadku mniejszych sieci. Wytrenowane w pełni skwantyzowane modele są udostępniane w przypadku konkretnych sieci na platformie Kaggle Models. Ważne jest sprawdzenie dokładności skwantyzowanego modelu, aby upewnić się, że wszelkie pogorszenie dokładności mieści się w dopuszczalnych granicach. Istnieją narzędzia do oceny dokładności modelu LiteRT.
Jeśli spadek dokładności jest zbyt duży, możesz użyć kwantyzacji z uwzględnieniem szkolenia. Wymaga to jednak wprowadzenia zmian podczas trenowania modelu, aby dodać fałszywe węzły kwantyzacji, podczas gdy techniki kwantyzacji po trenowaniu opisane na tej stronie wykorzystują istniejący, wstępnie wytrenowany model.
Reprezentacja skwantyzowanych tensorów
Kwantyzacja 8-bitowa przybliża wartości zmiennoprzecinkowe za pomocą tego wzoru:
\[real\_value = (int8\_value - zero\_point) \times scale\]
Reprezentacja składa się z 2 głównych części:
Wagi na osi (czyli na kanał) lub na tensorze reprezentowane przez 8-bitowe wartości w systemie uzupełnień do dwóch z zakresu [–127, 127] z punktem zerowym równym 0.
Aktywacje/dane wejściowe dla poszczególnych tensorów są reprezentowane przez wartości int8 w zakresie [-128, 127] w systemie uzupełnień do dwóch, z punktem zerowym w zakresie [-128, 127].
Szczegółowy opis naszego schematu kwantyzacji znajdziesz w specyfikacji kwantyzacji. Zachęcamy dostawców sprzętu, którzy chcą korzystać z interfejsu delegata TensorFlow Lite, do wdrożenia opisanego tam schematu kwantyzacji.