
LiteRT is Google's on-device framework for high-performance ML & GenAI deployment on edge platforms.
Efficient conversion, runtime, and optimization for on-device machine learning.
Built on the battle-tested foundation of TensorFlow Lite
LiteRT isn't just new; it's the next generation of the world's most widely deployed machine learning runtime. It powers the apps you use every day, delivering low latency and high privacy on billions of devices.
Trusted by the most critical Google apps
100K+ applications, billions of global users
LiteRT Highlights

Cross Platform Ready

Unleash GenAI
Simplified hardware acceleration

Multi-framework support
Deploy via LiteRT
Streamline your deep learning workflow from training to on-device deployment.

1.Obtain a model
Use .tflite pre-trained models or convert PyTorch, JAX or TensorFlow models to .tflite.

2.Optimize
Use the LiteRT optimization toolkit to quantize your models post-training.

3.Run
Deploy your model with LiteRT and pick the optimal accelerator for your app.
Choose Your Development Path
Use LiteRT to deploy AI anywhere—from high-performance mobile apps to resource-constrained IoT devices.
Existing TFLite User
Transitioning to LiteRT to leverage enhanced performance and unified APIs across platforms (Android, Desktop, Web).
BYOM : Bring your own Models
Have a PyTorch model, looking to implement on-device vision or audio experiences.
Deploying Generative AI Models
Creating sophisticated on-device chatbots using optimized open-weight GenAI models like Gemma or another open-weight model.
[Advanced] Model Expert
Authoring custom models or performing deep hardware-specific CPU/GPU/NPU optimizations for peak performance.
Samples, models, and demo

See LiteRT sample app on GitHub
Complete, end-to-end sample apps.

See genAI models
Pre-trained, out-of-the-box Gen AI models.

See demos - Google AI Edge Gallery App
A gallery that showcases on-device ML/GenAI use cases using LiteRT.
Blogs and Announcements
Stay up to date with the latest announcements, technical deep dives, and performance benchmarks from the LiteRT team.

Building real-world on-device AI with LiteRT and NPU
Learn how industry leaders build real-world, high-performance on-device AI applications using LiteRT and NPUs.
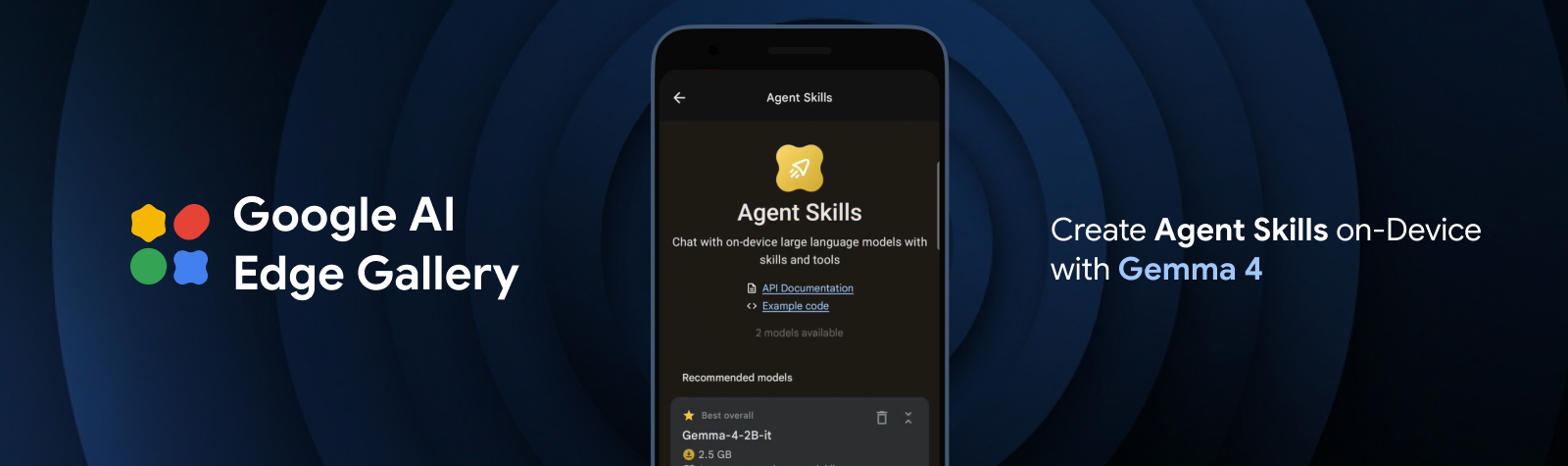
Bring state-of-the-art agentic skills to the edge with Gemma 4
Deploy agentic and multi-step planning capabilities entirely on-device with the new Gemma 4 family and LiteRT.

LiteRT: The universal framework for on-device AI
Google's unified on-device ML framework, evolving from TFLite for high-performance deployment.
MediaTek NPU and LiteRT: Powering the next generation of on-device AI
Expanding NPU acceleration support to MediaTek chipsets for high-efficiency AI.
Unlocking Peak Performance on Qualcomm NPU with LiteRT
Unlocking breakthrough performance for generative AI on Qualcomm Neural Processing Units.

LiteRT: Maximum Performance, Simplified
Introducing the CompiledModel API for automated hardware selection and async execution.
On-device GenAI in Chrome, Chromebook Plus, and Pixel Watch with LiteRT-LM
Deploy language models on wearables and browser-based platforms using LiteRT-LM.

Google AI Edge small language models, multimodality, and function calling
Latest insights on RAG, multimodality, and function calling for edge language models
Join the Community
LiteRT GitHub Community
Contribute directly to the project and collaborate with core developers.

Hugging Face Hub
Access optimized open-weight models on the Hugging Face Hub.