
Jeder Rechner ist ein Knoten in einem Graphen. Wir beschreiben, wie Sie ein neues
wie Sie einen Rechner initialisieren, wie Sie seine Berechnungen durchführen,
Eingabe- und Ausgabestreams, Zeitstempel und Optionen. Jeder Knoten im Diagramm
als Calculator implementiert. Der Großteil der Ausführung von Graphen erfolgt innerhalb der
Rechnern. Ein Rechner kann null oder mehr Eingabestreams und/oder Seiten
und erzeugt null oder mehr Ausgabestreams und/oder Seitenpakete.
CalculatorBase
Ein Rechner wird erstellt, indem eine neue Unterklasse der
CalculatorBase
-Klasse, implementiert eine Reihe von Methoden und registrieren die neue Unterklasse mit
Mediapipe Ein neuer Rechner muss mindestens die folgenden vier Methoden implementieren
GetContract()- Rechner:innen können die erwarteten Typen von Ein- und Ausgaben angeben eines Rechners in GetContract(). Wenn eine Grafik initialisiert wird, ruft das Framework eine statische Methode auf, um zu prüfen, ob die Pakettypen der verbundenen Ein- und Ausgaben mit den Informationen in diesem Spezifikation zu ändern.
Open()- Nachdem ein Diagramm gestartet wurde, ruft das Framework
Open()auf. Eingabeseite stehen dem Rechner jetzt Pakete zur Verfügung.Open()Interpretiert die Knotenkonfigurationsvorgänge (siehe Grafiken) und bereitet den Rechner für die Ausführung pro Graph vor. Diese Funktion kann auch Pakete in die Rechnerausgaben. Ein Fehler währendOpen()kann die Ausführung des Graphen beenden.
- Nachdem ein Diagramm gestartet wurde, ruft das Framework
Process()- Bei einem Rechner mit Eingaben ruft das Framework
Process()wiederholt auf wenn mindestens ein Eingabestream ein Paket verfügbar hat. Das Framework garantiert standardmäßig, dass alle Eingaben den gleichen Zeitstempel haben (siehe Weitere Informationen zur Synchronisierung. MehrereProcess()-Aufrufe können bei paralleler Ausführung gleichzeitig aufgerufen werden aktiviert ist. Wenn währendProcess()ein Fehler auftritt, ruft das FrameworkClose()und die Graphausführung wird beendet.
- Bei einem Rechner mit Eingaben ruft das Framework
Close()- Wenn alle Aufrufe an
Process()abgeschlossen sind oder wenn alle Eingabestreams geschlossen wurden, das FrameworkClose(). Diese Funktion wird immer aufgerufen,Open()wurde aufgerufen und erfolgreich, selbst wenn die Graphausführung beendet wurde weil ein Fehler aufgetreten ist. Über Eingabestreams sind keine Eingaben verfügbar währendClose(), hat aber immer noch Zugriff auf eingabeseitige Pakete und und daher Ausgaben schreiben kann. NachdemClose()zurückgegeben wurde, als toter Knoten betrachtet. Das Rechnerobjekt wird zerstört als sobald die Grafik ausgeführt wurde.
- Wenn alle Aufrufe an
Die folgenden Code-Snippets stammen aus CalculatorBase.h
class CalculatorBase {
public:
...
// The subclasses of CalculatorBase must implement GetContract.
// ...
static absl::Status GetContract(CalculatorContract* cc);
// Open is called before any Process() calls, on a freshly constructed
// calculator. Subclasses may override this method to perform necessary
// setup, and possibly output Packets and/or set output streams' headers.
// ...
virtual absl::Status Open(CalculatorContext* cc) {
return absl::OkStatus();
}
// Processes the incoming inputs. May call the methods on cc to access
// inputs and produce outputs.
// ...
virtual absl::Status Process(CalculatorContext* cc) = 0;
// Is called if Open() was called and succeeded. Is called either
// immediately after processing is complete or after a graph run has ended
// (if an error occurred in the graph). ...
virtual absl::Status Close(CalculatorContext* cc) {
return absl::OkStatus();
}
...
};
Das Leben eines Taschenrechners
Während der Initialisierung eines MediaPipe-Diagramms ruft das Framework eine
GetContract(), um zu bestimmen, welche Arten von Paketen erwartet werden.
Das Framework erstellt und zerstört den gesamten Rechner für jeden Graphen. (z.B. einmal pro Video oder einmal pro Bild). Teure oder große Objekte, die verborgen bleiben Konstante für Graphausführungen sollte als Eingabeseitenpakete bereitgestellt werden, Berechnungen bei nachfolgenden Durchläufen nicht wiederholt.
Nach der Initialisierung findet bei jeder Ausführung des Graphen die folgende Reihenfolge statt:
Open()Process()(wiederholt)Close()
Das Framework ruft Open() auf, um den Rechner zu initialisieren. Open() sollte
Interpretieren Sie alle Optionen und legen Sie den
Status pro Diagrammausführung fest. Open()
kann Eingabeseitenpakete abrufen und Pakete in die Rechnerausgaben schreiben. Wenn
geeignet, sollte SetOffset() aufgerufen werden, um die potenzielle Paketzwischenspeicherung zu reduzieren
von Eingabestreams.
Wenn während Open() oder Process() ein Fehler auftritt (wie durch einen von diesen angegeben)
und einen Nicht-Ok-Status zurückgibt, wird die Graphausführung ohne weitere Aufrufe beendet.
und der Rechner wird zerstört.
Bei einem Rechner mit Eingaben ruft das Framework Process() immer dann auf, wenn mindestens
für eine Eingabe ein Paket verfügbar ist. Das Framework garantiert, dass alle Eingaben
gleichen Zeitstempel, dass sich die Zeitstempel mit jedem Aufruf von Process() erhöhen und
dass alle Pakete zugestellt werden. Daher kann es sein, dass einige Eingaben
Pakete, wenn Process() aufgerufen wird. Eine Eingabe, deren Paket fehlt, scheint
ein leeres Paket (ohne Zeitstempel) erzeugen.
Das Framework ruft Close() nach allen Aufrufen von Process() auf. Alle Eingaben
sind erschöpft, aber Close() hat Zugriff auf eingabeseitige Pakete und kann
Ausgaben schreiben. Nachdem Close zurückgegeben wurde, wird der Rechner zerstört.
Rechner ohne Eingaben werden als Quellen bezeichnet. Ein Quellenrechner
Process() wird weiterhin aufgerufen, solange der Status Ok zurückgegeben wird. A
Der Quellenrechner gibt an, dass er aufgebraucht ist, indem ein Haltestellenstatus zurückgegeben wird.
(z. B. mediaPipe::tool::StatusStop()).
Ein- und Ausgaben identifizieren
Die öffentliche Schnittstelle zu einem Rechner besteht aus einer Reihe von Eingabestreams und
Ausgabestreams. In einer CalculatorGraphConfiguration
sind Rechner mit den Eingaben
anderer Rechner verbunden, die
Streams. Streamnamen werden normalerweise in Kleinbuchstaben geschrieben, während Eingabe- und Ausgabe-Tags
normalerweise in GROSSBUCHSTABEN. Im folgenden Beispiel lautet die Ausgabe mit dem Tag-Namen VIDEO:
die mit dem Eingang mit dem Tag-Namen VIDEO_IN über den Stream namens
video_stream
# Graph describing calculator SomeAudioVideoCalculator
node {
calculator: "SomeAudioVideoCalculator"
input_stream: "INPUT:combined_input"
output_stream: "VIDEO:video_stream"
}
node {
calculator: "SomeVideoCalculator"
input_stream: "VIDEO_IN:video_stream"
output_stream: "VIDEO_OUT:processed_video"
}
Eingabe- und Ausgabestreams können anhand der Indexnummer, des Tag-Namens oder
Kombination aus Tag-Name und Indexnummer. Sie sehen einige Beispiele für Eingabe- und
Ausgabekennungen im Beispiel unten. SomeAudioVideoCalculator identifiziert
Videoausgabe nach Tag und Audioausgaben durch die Kombination aus Tag und
-Index. Der Eingang mit dem Tag VIDEO ist mit dem Stream namens
video_stream. Die Ausgaben mit dem Tag AUDIO und den Indexen 0 und 1 sind
die mit den Streams audio_left und audio_right verbunden sind.
SomeAudioCalculator identifiziert Audioeingaben nur anhand des Index (kein Tag erforderlich).
# Graph describing calculator SomeAudioVideoCalculator
node {
calculator: "SomeAudioVideoCalculator"
input_stream: "combined_input"
output_stream: "VIDEO:video_stream"
output_stream: "AUDIO:0:audio_left"
output_stream: "AUDIO:1:audio_right"
}
node {
calculator: "SomeAudioCalculator"
input_stream: "audio_left"
input_stream: "audio_right"
output_stream: "audio_energy"
}
In der Rechnerimplementierung werden Ein- und Ausgaben auch durch Tags gekennzeichnet. mit dem Namen und der Indexnummer. In der folgenden Funktion werden Ein- und Ausgabe identifiziert:
- Nach Indexnummer: Der kombinierte Eingabestream wird einfach durch den Index identifiziert.
0 - Nach Tag-Name: Der Videoausgabestream wird durch den Tag-Namen "VIDEO" identifiziert.
- Nach Tag-Name und Indexnummer: Die ausgegebenen Audiostreams werden anhand des
Kombination aus Tag-Name
AUDIOund den Indexnummern0und1.
// c++ Code snippet describing the SomeAudioVideoCalculator GetContract() method
class SomeAudioVideoCalculator : public CalculatorBase {
public:
static absl::Status GetContract(CalculatorContract* cc) {
cc->Inputs().Index(0).SetAny();
// SetAny() is used to specify that whatever the type of the
// stream is, it's acceptable. This does not mean that any
// packet is acceptable. Packets in the stream still have a
// particular type. SetAny() has the same effect as explicitly
// setting the type to be the stream's type.
cc->Outputs().Tag("VIDEO").Set<ImageFrame>();
cc->Outputs().Get("AUDIO", 0).Set<Matrix>();
cc->Outputs().Get("AUDIO", 1).Set<Matrix>();
return absl::OkStatus();
}
In Bearbeitung
Process(), der auf einem Nicht-Quellknoten aufgerufen wird, muss absl::OkStatus() zurückgeben an
um anzuzeigen, dass alles funktioniert hat, oder einen anderen Statuscode, um einen Fehler zu signalisieren
Wenn ein externer Rechner tool::StatusStop() zurückgibt, signalisiert dies den
Diagramm vorzeitig abgebrochen. In diesem Fall werden alle Quellenrechner
und der Graphen verwendet,
Eingabestreams werden geschlossen (und verbleibende Pakete werden durch den
Diagramm).
Auf einen Quellknoten in einem Diagramm wird Process() so lange wie möglich aufgerufen
da sie absl::OkStatus( zurückgibt. Um anzuzeigen, dass keine weiteren Daten vorliegen,
generierte Rückgabe tool::StatusStop(). Jeder andere Status gibt an, dass ein Fehler
aufgetreten.
Close() gibt absl::OkStatus() zurück, wenn der Vorgang erfolgreich war. Sonstiger Status
zeigt einen Fehler an.
Hier ist die grundlegende Process()-Funktion. Dabei wird die Methode Input() verwendet,
nur verwendet werden, wenn der Rechner nur über eine einzige Eingabe verfügt), um die Eingabedaten anzufordern. Es
verwendet dann std::unique_ptr, um den für das Ausgabepaket erforderlichen Arbeitsspeicher zuzuweisen.
und führt die Berechnungen durch. Wenn der Vorgang abgeschlossen ist, wird der Zeiger losgelassen, wenn er
des Ausgabestreams.
absl::Status MyCalculator::Process() {
const Matrix& input = Input()->Get<Matrix>();
std::unique_ptr<Matrix> output(new Matrix(input.rows(), input.cols()));
// do your magic here....
// output->row(n) = ...
Output()->Add(output.release(), InputTimestamp());
return absl::OkStatus();
}
Rechneroptionen
Rechner akzeptieren Verarbeitungsparameter über (1) Eingabestreampakete (2)
Eingabeseitenpakete und (3) Rechneroptionen. Rechneroptionen, wenn
angegeben, als Literalwerte im Feld node_options der
CalculatorGraphConfiguration.Node-Nachricht.
node {
calculator: "TfLiteInferenceCalculator"
input_stream: "TENSORS:main_model_input"
output_stream: "TENSORS:main_model_output"
node_options: {
[type.googleapis.com/mediapipe.TfLiteInferenceCalculatorOptions] {
model_path: "mediapipe/models/detection_model.tflite"
}
}
}
Das Feld node_options akzeptiert die Proto3-Syntax. Alternativ können Sie mit dem Rechner
Optionen können im Feld options mithilfe der Proto2-Syntax angegeben werden.
node {
calculator: "TfLiteInferenceCalculator"
input_stream: "TENSORS:main_model_input"
output_stream: "TENSORS:main_model_output"
node_options: {
[type.googleapis.com/mediapipe.TfLiteInferenceCalculatorOptions] {
model_path: "mediapipe/models/detection_model.tflite"
}
}
}
Nicht alle Rechner akzeptieren Rechneroptionen. Um Optionen anzunehmen, muss ein
normalerweise einen neuen protobuf-Nachrichtentyp definiert,
Optionen wie PacketClonerCalculatorOptions. Der Rechner ermittelt dann
diese protobuf-Nachricht in ihrer CalculatorBase::Open-Methode lesen und möglicherweise
ist auch in seiner CalculatorBase::GetContract-Funktion
CalculatorBase::Process-Methode. Normalerweise wird der neue Nachrichtentyp
protobuf
als protobuf-Schema mit einer „.proto“-Datei definiert Datei und ein
mediapipe_proto_library()-Build-Regel.
mediapipe_proto_library(
name = "packet_cloner_calculator_proto",
srcs = ["packet_cloner_calculator.proto"],
visibility = ["//visibility:public"],
deps = [
"//mediapipe/framework:calculator_options_proto",
"//mediapipe/framework:calculator_proto",
],
)
Beispielrechner
In diesem Abschnitt wird die Implementierung von PacketClonerCalculator erläutert, die
und wird in vielen Rechnergrafiken verwendet.
PacketClonerCalculator erstellt einfach eine Kopie der letzten Eingabepakete
on demand.
PacketClonerCalculator ist nützlich, wenn die Zeitstempel eingehender Datenpakete
nicht perfekt aufeinander abgestimmt. Angenommen, wir haben einen Raum mit Mikrofon, Licht
und einer Videokamera, die Sinnesdaten sammelt. Jeder der Sensoren
arbeitet unabhängig und erhebt unregelmäßig Daten. Angenommen, die Ausgabe
jedes Sensors:
- Mikrofon = Lautstärke in Dezibel im Raum (Ganzzahl)
- Lichtsensor = Helligkeit des Raums (Ganzzahl)
- Videokamera = RGB-Bildframe des Raums (ImageFrame)
Unsere einfache Wahrnehmungs-Pipeline wurde entwickelt, um Sinnesdaten aus diesen drei Sensoren, sodass jedes Mal, wenn Frame-Daten von der Kamera vorliegen, wird mit den zuletzt erfassten Daten zur Mikrofonlautstärke und dem Licht synchronisiert Helligkeitsdaten des Sensors. Um dies mit MediaPipe zu erreichen, verfügt unsere Perception-Pipeline über drei Eingabestreams:
- Room_mic_signal – Jedes Datenpaket in diesem Eingabestream ist eine Ganzzahl die die Lautstärke der Geräusche in einem Raum mit Zeitstempel darstellt.
- Room_lightening_sensor – Jedes Datenpaket in diesem Eingabestream ist eine Ganzzahl Daten, die angeben, wie hell der Raum beleuchtet ist, mit Zeitstempel.
- Room_video_tick_signal – Jedes Datenpaket in diesem Eingabestream Bildframe aus Videodaten, die das von der Kamera aufgenommene Video darstellen Raum mit Zeitstempel.
Unten siehst du die Implementierung von PacketClonerCalculator. Sie können die
GetContract()-, Open()- und Process()-Methoden sowie die Instanz.
Variable current_, die die neuesten Eingabepakete enthält.
// This takes packets from N+1 streams, A_1, A_2, ..., A_N, B.
// For every packet that appears in B, outputs the most recent packet from each
// of the A_i on a separate stream.
#include <vector>
#include "absl/strings/str_cat.h"
#include "mediapipe/framework/calculator_framework.h"
namespace mediapipe {
// For every packet received on the last stream, output the latest packet
// obtained on all other streams. Therefore, if the last stream outputs at a
// higher rate than the others, this effectively clones the packets from the
// other streams to match the last.
//
// Example config:
// node {
// calculator: "PacketClonerCalculator"
// input_stream: "first_base_signal"
// input_stream: "second_base_signal"
// input_stream: "tick_signal"
// output_stream: "cloned_first_base_signal"
// output_stream: "cloned_second_base_signal"
// }
//
class PacketClonerCalculator : public CalculatorBase {
public:
static absl::Status GetContract(CalculatorContract* cc) {
const int tick_signal_index = cc->Inputs().NumEntries() - 1;
// cc->Inputs().NumEntries() returns the number of input streams
// for the PacketClonerCalculator
for (int i = 0; i < tick_signal_index; ++i) {
cc->Inputs().Index(i).SetAny();
// cc->Inputs().Index(i) returns the input stream pointer by index
cc->Outputs().Index(i).SetSameAs(&cc->Inputs().Index(i));
}
cc->Inputs().Index(tick_signal_index).SetAny();
return absl::OkStatus();
}
absl::Status Open(CalculatorContext* cc) final {
tick_signal_index_ = cc->Inputs().NumEntries() - 1;
current_.resize(tick_signal_index_);
// Pass along the header for each stream if present.
for (int i = 0; i < tick_signal_index_; ++i) {
if (!cc->Inputs().Index(i).Header().IsEmpty()) {
cc->Outputs().Index(i).SetHeader(cc->Inputs().Index(i).Header());
// Sets the output stream of index i header to be the same as
// the header for the input stream of index i
}
}
return absl::OkStatus();
}
absl::Status Process(CalculatorContext* cc) final {
// Store input signals.
for (int i = 0; i < tick_signal_index_; ++i) {
if (!cc->Inputs().Index(i).Value().IsEmpty()) {
current_[i] = cc->Inputs().Index(i).Value();
}
}
// Output if the tick signal is non-empty.
if (!cc->Inputs().Index(tick_signal_index_).Value().IsEmpty()) {
for (int i = 0; i < tick_signal_index_; ++i) {
if (!current_[i].IsEmpty()) {
cc->Outputs().Index(i).AddPacket(
current_[i].At(cc->InputTimestamp()));
// Add a packet to output stream of index i a packet from inputstream i
// with timestamp common to all present inputs
} else {
cc->Outputs().Index(i).SetNextTimestampBound(
cc->InputTimestamp().NextAllowedInStream());
// if current_[i], 1 packet buffer for input stream i is empty, we will set
// next allowed timestamp for input stream i to be current timestamp + 1
}
}
}
return absl::OkStatus();
}
private:
std::vector<Packet> current_;
int tick_signal_index_;
};
REGISTER_CALCULATOR(PacketClonerCalculator);
} // namespace mediapipe
Normalerweise verfügt ein Rechner nur über eine .cc-Datei. .h ist nicht erforderlich, da Mediapipe nutzt die Registrierung, um Rechner bekannt zu machen. Nachdem Sie Rechnerklasse definiert haben, registrieren Sie sie mit einem Makroaufruf REGISTER_CALCULATOR(calculator_class_name).
Unten sehen Sie ein einfaches MediaPipe-Diagramm mit 3 Eingabestreams, 1 Knoten (PacketClonerCalculator) und zwei Ausgabestreams.
input_stream: "room_mic_signal"
input_stream: "room_lighting_sensor"
input_stream: "room_video_tick_signal"
node {
calculator: "PacketClonerCalculator"
input_stream: "room_mic_signal"
input_stream: "room_lighting_sensor"
input_stream: "room_video_tick_signal"
output_stream: "cloned_room_mic_signal"
output_stream: "cloned_lighting_sensor"
}
Das folgende Diagramm zeigt, wie PacketClonerCalculator seine Ausgabe definiert
Pakete (unten) basierend auf der Reihe von Eingabepaketen (oben).
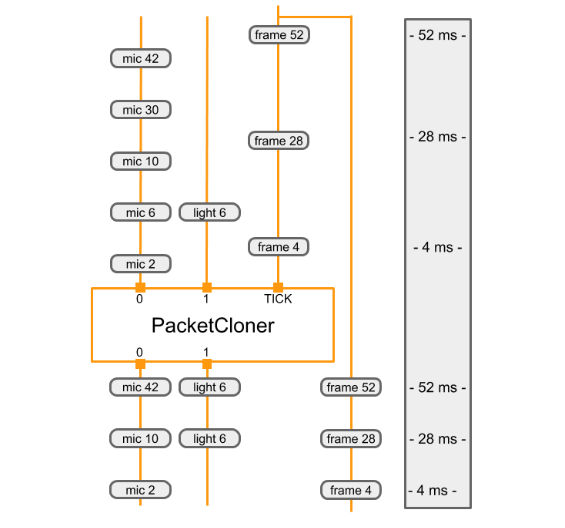 |
|---|
| Bei jedem Empfang eines Pakets in seinem TICK-Eingabestream gibt PacketKlonrCalculator das neueste Paket aus jedem seiner Eingabestreams aus. Die Reihenfolge der Ausgabepakete (unten) wird durch die Sequenz der Eingabepakete (oben) und deren Zeitstempel bestimmt. Die Zeitstempel werden rechts im Diagramm angezeigt. |