
Modelli aperti di Gemma
Una famiglia di modelli aperti leggeri e all'avanguardia creati sulla base della stessa ricerca e tecnologia utilizzata per creare i modelli Gemini
Progettazione responsabile
Grazie all'integrazione di misure di sicurezza complete, questi modelli contribuiscono a garantire soluzioni di IA responsabili e affidabili tramite set di dati selezionati e ottimizzazione rigorosa.
Prestazioni senza pari in termini di dimensioni
I modelli Gemma raggiungono risultati di benchmark eccezionali con dimensioni di 2 miliardi, 7 miliardi, 9 miliardi e 27 miliardi, superando persino alcuni modelli open più grandi.
Deployment flessibile
Esegui il deployment su mobile, web e cloud utilizzando Keras, JAX, MediaPipe, PyTorch, Hugging Face e altro ancora.
Prova Gemma 2
Riprogettato per prestazioni straordinarie ed efficienza senza pari, Gemma 2 è ottimizzato per un'inferenza ultraveloce su diversi hardware.
5 scatti
MMLU
Il benchmark MMLU è un test che misura l'ampiezza delle conoscenze e la capacità di risoluzione dei problemi acquisite dai modelli linguistici di grandi dimensioni durante la pre-addestramento.
25 scatti
ARC-C
Il benchmark ARC-c è un sottoinsieme più mirato del set di dati ARC-e, contenente solo domande a cui è stata data una risposta errata da algoritmi comuni (basati sul recupero e sulla cooccorrenza delle parole).
5 scatti
GSM8K
Il benchmark GSM8K testa la capacità di un modello linguistico di risolvere problemi matematici di livello scolastico che spesso richiedono più passaggi di ragionamento.
3-5-shot
AGIEval
Il benchmark AGIEval testa l'intelligenza generale di un modello linguistico utilizzando domande tratte da esami reali progettati per valutare le capacità intellettuali umane.
3 scatti, CoT
BBH
Il benchmark BBH (BIG-Bench Hard) si concentra su attività ritenute al di là delle capacità degli attuali modelli linguistici, testandone i limiti in vari domini di ragionamento e comprensione.
3 foto, F1
RILASCIA
DROP è un benchmark di comprensione della lettura che richiede un ragionamento discreto sui paragrafi.
5 scatti
Winogrande
Il benchmark Winogrande testa la capacità di un modello linguistico di risolvere attività di completamento dei campi con opzioni binarie ambigue, che richiedono un ragionamento di buon senso generalizzato.
10 scatti
HellaSwag
Il benchmark HellaSwag mette alla prova la capacità di un modello linguistico di comprendere e applicare il ragionamento di buon senso selezionando la fine più logica di una storia.
4 scatti
MATEMATICA
MATH valuta la capacità di un modello linguistico di risolvere problemi matematici complessi con enunciato, che richiedono ragionamento, risoluzione di problemi a più passaggi e comprensione di concetti matematici.
Zero-shot
ARC-e
Il benchmark ARC-e verifica le capacità avanzate di risposta alle domande di un modello linguistico con domande di scienza a scelta multipla autentiche a livello di scuola elementare.
Zero-shot
PIQA
Il benchmark PIQA testa la capacità di un modello linguistico di comprendere e applicare la conoscenza fisica di senso comune rispondendo a domande sulle interazioni fisiche quotidiane.
Zero-shot
SIQA
Il benchmark SIQA valuta la comprensione delle interazioni sociali e del buon senso sociale da parte di un modello linguistico ponendo domande sulle azioni delle persone e sulle loro implicazioni sociali.
Zero-shot
Boolq
Il benchmark BoolQ verifica la capacità di un modello linguistico di rispondere a domande di tipo sì/no che si verificano naturalmente, testando la capacità dei modelli di svolgere attività di inferenza del linguaggio naturale reali.
5 scatti
TriviaQA
Il benchmark TriviaQA valuta le competenze di comprensione della lettura con triplette di domande, risposte ed evidenze.
5 scatti
NQ
Il benchmark NQ (Natural Questions) testa la capacità di un modello linguistico di trovare e comprendere le risposte all'interno di interi articoli di Wikipedia, simulando scenari di risposta alle domande reali.
pass@1
HumanEval
Il benchmark HumanEval testa le capacità di generazione di codice di un modello linguistico valutando se le sue soluzioni superano i test delle unità funzionali per i problemi di programmazione.
3 scatti
MBPP
Il benchmark MBPP testa la capacità di un modello linguistico di risolvere problemi di programmazione di base in Python, concentrandosi sui concetti di programmazione fondamentali e sull'utilizzo della libreria standard.
100%
75%
50%
25%
0%
100%
75%
50%
25%
0%
Gemma 1
2,5 miliardi
Gemma 2
2,6 miliardi
Mistral
7 miliardi
LLAMA 3
8 miliardi
Gemma 1
7 miliardi
Gemma 2
Oltre 9 miliardi
Gemma 2
27 mld
Gemma 1
2,5 miliardi
Gemma 2
2,6 miliardi
Mistral
7 miliardi
LLAMA 3
8 miliardi
Gemma 1
7 miliardi
Gemma 2
Oltre 9 miliardi
Gemma 2
27 mld
Gemma 1
2,5 miliardi
Gemma 2
2,6 miliardi
Mistral
7 miliardi
LLAMA 3
8 miliardi
Gemma 1
7 miliardi
Gemma 2
Oltre 9 miliardi
Gemma 2
27 mld
Gemma 1
2,5 miliardi
Gemma 2
2,6 miliardi
Mistral
7 miliardi
LLAMA 3
8 miliardi
Gemma 1
7 miliardi
Gemma 2
Oltre 9 miliardi
Gemma 2
27 mld
Gemma 1
2,5 miliardi
Gemma 2
2,6 miliardi
Mistral
7 miliardi
LLAMA 3
8 miliardi
Gemma 1
7 miliardi
Gemma 2
Oltre 9 miliardi
Gemma 2
27 mld
Gemma 1
2,5 miliardi
Gemma 2
2,6 miliardi
Mistral
7 miliardi
LLAMA 3
8 miliardi
Gemma 1
7 miliardi
Gemma 2
Oltre 9 miliardi
Gemma 2
27 mld
Gemma 1
2,5 miliardi
Gemma 2
2,6 miliardi
Mistral
7 miliardi
LLAMA 3
8 miliardi
Gemma 1
7 miliardi
Gemma 2
Oltre 9 miliardi
Gemma 2
27 mld
Gemma 1
2,5 miliardi
Gemma 2
2,6 miliardi
Mistral
7 miliardi
LLAMA 3
8 miliardi
Gemma 1
7 miliardi
Gemma 2
Oltre 9 miliardi
Gemma 2
27 mld
Gemma 1
2,5 miliardi
Gemma 2
2,6 miliardi
Mistral
7 miliardi
Gemma 1
7 miliardi
Gemma 2
Oltre 9 miliardi
Gemma 2
27 mld
Gemma 1
2,5 miliardi
Gemma 2
2,6 miliardi
Mistral
7 miliardi
Gemma 1
7 miliardi
Gemma 2
Oltre 9 miliardi
Gemma 2
27 mld
Gemma 1
2,5 miliardi
Gemma 2
2,6 miliardi
Mistral
7 miliardi
Gemma 1
7 miliardi
Gemma 2
Oltre 9 miliardi
Gemma 2
27 mld
Gemma 1
2,5 miliardi
Gemma 2
2,6 miliardi
Mistral
7 miliardi
Gemma 1
7 miliardi
Gemma 2
Oltre 9 miliardi
Gemma 2
27 mld
Gemma 1
2,5 miliardi
Gemma 2
2,6 miliardi
Mistral
7 miliardi
Gemma 1
7 miliardi
Gemma 2
Oltre 9 miliardi
Gemma 2
27 mld
Gemma 1
2,5 miliardi
Gemma 2
2,6 miliardi
Mistral
7 miliardi
Gemma 1
7 miliardi
Gemma 2
Oltre 9 miliardi
Gemma 2
27 mld
Gemma 1
2,5 miliardi
Gemma 2
2,6 miliardi
Mistral
7 miliardi
Gemma 1
7 miliardi
Gemma 2
Oltre 9 miliardi
Gemma 2
27 mld
Gemma 1
2,5 miliardi
Gemma 2
2,6 miliardi
Mistral
7 miliardi
Gemma 1
7 miliardi
Gemma 2
Oltre 9 miliardi
Gemma 2
27 mld
Gemma 1
2,5 miliardi
Gemma 2
2,6 miliardi
Mistral
7 miliardi
Gemma 1
7 miliardi
Gemma 2
Oltre 9 miliardi
Gemma 2
27 mld
*Questi sono i benchmark per i modelli preaddestrati. Consulta il report tecnico per informazioni dettagliate sul rendimento con altre metodologie.
Modelli di ricerca
Scopri la famiglia di modelli Gemma estesa
PaliGemma 2 Novità
Ambito Gemma

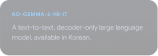

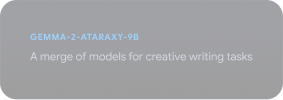
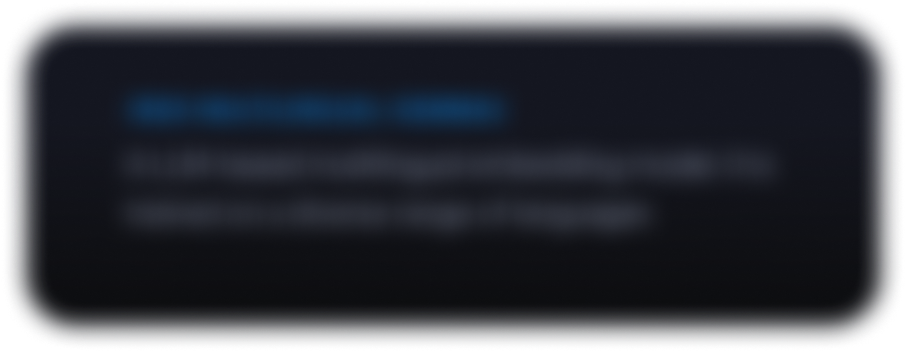
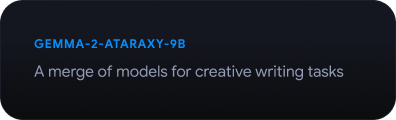

Esplorare il Gemmaverse
Un vasto ecosistema di modelli e strumenti Gemma creati dalla community, pronti a potenziare e ispirare la tua innovazione
Build
Inizia a creare con Gemma




Deployment modelli
Scegli il target di deployment
![]() Dispositivo mobile
Dispositivo mobile
Esegui il deployment on-device con Google AI Edge
Esegui il deployment direttamente sui dispositivi per una funzionalità offline a bassa latenza. Ideale per applicazioni che richiedono reattività e privacy in tempo reale, come app mobile, dispositivi IoT e sistemi embedded.
![]() Web
Web
Integrazione perfetta nelle applicazioni web
Migliora i tuoi siti web e servizi web con funzionalità di IA avanzate, attivando funzionalità interattive, contenuti personalizzati e automazione intelligente.
![]() Cloud
Cloud
Scalabilità senza problemi con l'infrastruttura cloud
Sfrutta la scalabilità e la flessibilità del cloud per gestire implementazioni su larga scala, carichi di lavoro impegnativi e applicazioni di IA complesse.