
Modelos abertos do Gemma
Uma família de modelos abertos leves e de última geração criados com a mesma pesquisa e tecnologia usadas para criar os modelos do Gemini
Responsabilidade incorporada ao design
Esses modelos incorporam medidas de segurança abrangentes e ajudam a garantir soluções de IA responsáveis e confiáveis com conjuntos de dados selecionados e ajustes rigorosos.
Desempenho incomparável
Os modelos Gemma alcançam resultados de comparação excepcionais nos tamanhos 2B, 7B, 9B e 27B, superando até mesmo alguns modelos abertos maiores.
Implantação flexível
Implante de forma integrada em dispositivos móveis, na Web e na nuvem usando Keras, JAX, MediaPipe, PyTorch, Hugging Face e muito mais.
Teste o Gemma 2
O Gemma 2 foi redesenhado para ter um desempenho superior e uma eficiência incomparável, otimizando a inferência em diversos hardwares.
5 fotos
MMLU
O comparativo de mercado MMLU é um teste que mede a amplitude do conhecimento e a capacidade de resolução de problemas adquirida por modelos de linguagem grandes durante o pré-treinamento.
25 fotos
ARC-C
O comparativo ARC-c é um subconjunto mais focado do conjunto de dados ARC-e, contendo apenas perguntas respondidas incorretamente por algoritmos comuns (base de recuperação e co-ocorrência de palavras).
5 fotos
GSM8K
O comparativo GSM8K testa a capacidade de um modelo de linguagem de resolver problemas de matemática do ensino fundamental que geralmente exigem várias etapas de raciocínio.
3 a 5 tiros
AGIEval
O comparativo AGIEval testa a inteligência geral de um modelo de linguagem usando perguntas derivadas de exames reais projetados para avaliar as habilidades intelectuais humanas.
3-shot, CoT
BBH
O comparativo de mercado BBH (BIG-Bench Hard) se concentra em tarefas consideradas além das habilidades dos modelos de linguagem atuais, testando os limites deles em vários domínios de raciocínio e compreensão.
3 fotos, F1
SOLTAR
O DROP é um comparativo de mercado de compreensão de leitura que exige raciocínio discreto sobre parágrafos.
5 fotos
Winogrande
O comparativo de mercado Winogrande testa a capacidade de um modelo de linguagem de resolver tarefas de preenchimento de lacunas ambíguas com opções binárias, exigindo raciocínio generalizado de senso comum.
10 fotos
HellaSwag
O comparativo HellaSwag desafia a capacidade de um modelo de linguagem de entender e aplicar o raciocínio de senso comum selecionando o final mais lógico de uma história.
4 fotos
MATH
O MATH avalia a capacidade de um modelo de linguagem de resolver problemas matemáticos complexos, exigindo raciocínio, resolução de problemas em várias etapas e a compreensão de conceitos matemáticos.
Zero-shot
ARC-e
O comparativo ARC-e testa as habilidades avançadas de resposta a perguntas de um modelo de linguagem com perguntas de múltipla escolha genuínas do ensino fundamental.
Zero-shot
PIQA
O comparativo de mercado PIQA testa a capacidade de um modelo de linguagem de entender e aplicar o conhecimento de senso comum físico respondendo a perguntas sobre interações físicas cotidianas.
Zero-shot
SIQA
O comparativo de mercado SIQA avalia a compreensão de um modelo de linguagem sobre interações sociais e senso comum social fazendo perguntas sobre as ações das pessoas e as implicações sociais delas.
Zero-shot
Boolq
O comparativo do BoolQ testa a capacidade de um modelo de linguagem de responder a perguntas "sim/não" que ocorrem naturalmente, testando a capacidade dos modelos de realizar tarefas de inferência de linguagem natural do mundo real.
5 fotos
TriviaQA
O comparativo TriviaQA testa as habilidades de compreensão de leitura com triplas de pergunta-resposta-prova.
5 fotos
NQ
O comparativo de NQ (perguntas naturais) testa a capacidade de um modelo de linguagem de encontrar e compreender respostas em artigos completos da Wikipédia, simulando cenários reais de resposta a perguntas.
pass@1
HumanEval
O comparativo HumanEval testa as habilidades de geração de código de um modelo de linguagem avaliando se as soluções passam nos testes de unidade funcionais para problemas de programação.
3 fotos
MBPP
O comparativo de mercado MBPP testa a capacidade de um modelo de linguagem de resolver problemas básicos de programação em Python, com foco em conceitos de programação fundamentais e uso de bibliotecas padrão.
100%
75%
50%
25%
0%
100%
75%
50%
25%
0%
Gemma 1
2,5 bilhões
Gemma 2
2,6 bilhões
Mistral
7B
LLAMA 3
8B
Gemma 1
7B
Gemma 2
9 bilhões
Gemma 2
27B
Gemma 1
2,5 bilhões
Gemma 2
2,6 bilhões
Mistral
7B
LLAMA 3
8B
Gemma 1
7B
Gemma 2
9 bilhões
Gemma 2
27B
Gemma 1
2,5 bilhões
Gemma 2
2,6 bilhões
Mistral
7B
LLAMA 3
8B
Gemma 1
7B
Gemma 2
9 bilhões
Gemma 2
27B
Gemma 1
2,5 bilhões
Gemma 2
2,6 bilhões
Mistral
7B
LLAMA 3
8B
Gemma 1
7B
Gemma 2
9 bilhões
Gemma 2
27B
Gemma 1
2,5 bilhões
Gemma 2
2,6 bilhões
Mistral
7B
LLAMA 3
8B
Gemma 1
7B
Gemma 2
9 bilhões
Gemma 2
27B
Gemma 1
2,5 bilhões
Gemma 2
2,6 bilhões
Mistral
7B
LLAMA 3
8B
Gemma 1
7B
Gemma 2
9 bilhões
Gemma 2
27B
Gemma 1
2,5 bilhões
Gemma 2
2,6 bilhões
Mistral
7B
LLAMA 3
8B
Gemma 1
7B
Gemma 2
9 bilhões
Gemma 2
27B
Gemma 1
2,5 bilhões
Gemma 2
2,6 bilhões
Mistral
7B
LLAMA 3
8B
Gemma 1
7B
Gemma 2
9 bilhões
Gemma 2
27B
Gemma 1
2,5 bilhões
Gemma 2
2,6 bilhões
Mistral
7B
Gemma 1
7B
Gemma 2
9 bilhões
Gemma 2
27B
Gemma 1
2,5 bilhões
Gemma 2
2,6 bilhões
Mistral
7B
Gemma 1
7B
Gemma 2
9 bilhões
Gemma 2
27B
Gemma 1
2,5 bilhões
Gemma 2
2,6 bilhões
Mistral
7B
Gemma 1
7B
Gemma 2
9 bilhões
Gemma 2
27B
Gemma 1
2,5 bilhões
Gemma 2
2,6 bilhões
Mistral
7B
Gemma 1
7B
Gemma 2
9 bilhões
Gemma 2
27B
Gemma 1
2,5 bilhões
Gemma 2
2,6 bilhões
Mistral
7B
Gemma 1
7B
Gemma 2
9 bilhões
Gemma 2
27B
Gemma 1
2,5 bilhões
Gemma 2
2,6 bilhões
Mistral
7B
Gemma 1
7B
Gemma 2
9 bilhões
Gemma 2
27B
Gemma 1
2,5 bilhões
Gemma 2
2,6 bilhões
Mistral
7B
Gemma 1
7B
Gemma 2
9 bilhões
Gemma 2
27B
Gemma 1
2,5 bilhões
Gemma 2
2,6 bilhões
Mistral
7B
Gemma 1
7B
Gemma 2
9 bilhões
Gemma 2
27B
Gemma 1
2,5 bilhões
Gemma 2
2,6 bilhões
Mistral
7B
Gemma 1
7B
Gemma 2
9 bilhões
Gemma 2
27B
*Esses são os comparativos para os modelos pré-treinados. Consulte o relatório técnico para saber mais sobre a performance com outras metodologias.
Modelos de pesquisa
Conheça a família de modelos estendida do Gemma
PaliGemma 2 Novo
Escopo do Gemma

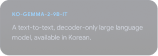

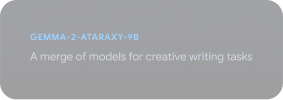
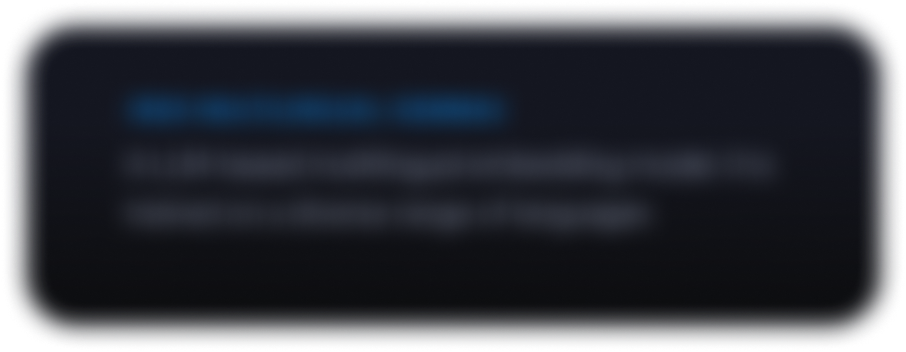
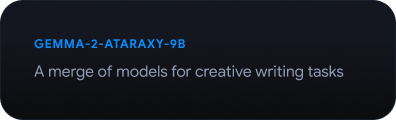

Conheça o Gemmaverse
Um vasto ecossistema de modelos e ferramentas do Gemma criados pela comunidade, prontos para impulsionar e inspirar sua inovação
Criar
Começar a criar com o Gemma




Implantar modelos
Escolher o destino da implantação
![]() Dispositivo móvel
Dispositivo móvel
Implantar no dispositivo com a IA de borda do Google
Implante diretamente nos dispositivos para funcionalidade off-line com baixa latência. Ideal para aplicativos que exigem privacidade e capacidade de resposta em tempo real, como apps para dispositivos móveis, dispositivos de IoT e sistemas embarcados.
![]() Web
Web
Integração perfeita a aplicativos da Web
Melhore seus sites e serviços da Web com recursos avançados de IA, como recursos interativos, conteúdo personalizado e automação inteligente.
![]() Cloud
Cloud
Escalone sem esforço com a infraestrutura em nuvem
Aproveite a escalabilidade e a flexibilidade da nuvem para lidar com implantações em grande escala, cargas de trabalho exigentes e aplicativos complexos de IA.


Como aproveitar a comunicação global
Participe da nossa competição global do Kaggle. Criar variantes do modelo Gemma para um idioma ou aspecto cultural específico