|
|
|
 Ver o código-fonte no GitHub Ver o código-fonte no GitHub
|
|
Este codelab ilustra como criar um classificador de texto personalizado usando o ajuste eficiente de parâmetros (PET). Em vez de ajustar todo o modelo, os métodos de PET atualizam apenas uma pequena quantidade de parâmetros, o que torna o treinamento relativamente fácil e rápido. Isso também facilita a aprendizagem de novos comportamentos com dados de treinamento relativamente pequenos. A metodologia é descrita em detalhes em Towards Agile Text Classifiers for Everyone, que mostra como essas técnicas podem ser aplicadas a várias tarefas de segurança e alcançar o estado da arte com apenas algumas centenas de exemplos de treinamento.
Este codelab usa o método de PET LoRA e
o modelo Gemma menor (gemma_instruct_2b_en), já que ele pode ser executado com mais rapidez
e eficiência. O colab aborda as etapas de ingestão de dados, formatação
para o LLM, treinamento de pesos de LoRA e avaliação dos resultados. Este
codelab é treinado com o conjunto de dados ETHOS, um conjunto de dados disponível publicamente
para detectar discurso de ódio, criado com base em comentários do YouTube e do Reddit.
Quando treinado com apenas 200 exemplos (1/4 do conjunto de dados), ele alcança F1: 0,80 e
ROC-AUC: 0,78, um pouco acima do SOTA atualmente informado na
classificação (na época em que este artigo foi escrito, 15 de fevereiro de 2024). Quando
treinado com os 800 exemplos completos, ele alcança uma pontuação F1 de 83,74 e uma
pontuação ROC-AUC de 88,17. Modelos maiores, como gemma_instruct_7b_en, geralmente têm um desempenho melhor, mas os custos de treinamento e execução também são maiores.
Aviso de gatilho: como este codelab desenvolve um classificador de segurança para detectar discurso de ódio, os exemplos e a avaliação dos resultados contêm linguagem horrível.
Instalação e configuração
Para este codelab, você vai precisar de uma versão recente do keras (3), keras-nlp
(0.8.0) e uma conta do Kaggle para fazer o download de um modelo Gemma.
import kagglehub
kagglehub.login()
pip install -q -U keras-nlppip install -q -U keras
import os
os.environ["KERAS_BACKEND"] = "tensorflow"
Carregar o conjunto de dados ETHOS
Nesta seção, você vai carregar o conjunto de dados em que vai treinar nosso classificador e pré-processá-lo em um conjunto de treinamento e teste. Você vai usar o conjunto de dados de pesquisa ETHOS, que foi coletado para detectar discurso de ódio nas mídias sociais. Confira mais informações sobre como o conjunto de dados foi coletado no artigo ETHOS: um conjunto de dados de detecção de discurso de ódio on-line.
import pandas as pd
gh_root = 'https://raw.githubusercontent.com'
gh_repo = 'intelligence-csd-auth-gr/Ethos-Hate-Speech-Dataset'
gh_path = 'master/ethos/ethos_data/Ethos_Dataset_Binary.csv'
data_url = f'{gh_root}/{gh_repo}/{gh_path}'
df = pd.read_csv(data_url, delimiter=';')
df['hateful'] = (df['isHate'] >= df['isHate'].median()).astype(int)
# Shuffle the dataset.
df = df.sample(frac=1, random_state=32)
# Split into train and test.
df_train, df_test = df[:800], df[800:]
# Display a sample of the data.
df.head(5)[['hateful', 'comment']]
Fazer o download e instanciar o modelo
Conforme descrito na documentação, é possível usar o modelo Gemma de várias maneiras. Com o Keras, você precisa fazer o seguinte:
import keras
import keras_nlp
# For reproducibility purposes.
keras.utils.set_random_seed(1234)
# Download the model from Kaggle using Keras.
model = keras_nlp.models.GemmaCausalLM.from_preset('gemma_instruct_2b_en')
# Set the sequence length to a small enough value to fit in memory in Colab.
model.preprocessor.sequence_length = 128
model.generate('Question: what is the capital of France? ', max_length=32)
Pré-processamento de texto e tokens de separador
Para ajudar o modelo a entender melhor nossa intenção, você pode pré-processar o texto e usar tokens de separador. Isso torna menos provável que o modelo gere um texto que não se encaixe no formato esperado. Por exemplo, você pode tentar solicitar uma classificação de sentimento do modelo escrevendo um comando como este:
Classify the following text into one of the following classes:[Positive,Negative]
Text: you look very nice today
Classification:
Nesse caso, o modelo pode ou não gerar o que você está procurando. Por exemplo, se o texto contiver caracteres de nova linha, é provável que ele tenha um efeito negativo na performance do modelo. Uma abordagem mais robusta é usar tokens de separador. O prompt vai ficar assim:
Classify the following text into one of the following classes:[Positive,Negative]
<separator>
Text: you look very nice today
<separator>
Prediction:
Isso pode ser abstrato usando uma função que pré-processa o texto:
def preprocess_text(
text: str,
labels: list[str],
instructions: str,
separator: str,
) -> str:
prompt = f'{instructions}:[{",".join(labels)}]'
return separator.join([prompt, f'Text:{text}', 'Prediction:'])
Agora, se você executar a função usando o mesmo comando e texto, você vai receber a mesma saída:
text = 'you look very nice today'
prompt = preprocess_text(
text=text,
labels=['Positive', 'Negative'],
instructions='Classify the following text into one of the following classes',
separator='\n<separator>\n',
)
print(prompt)
Classify the following text into one of the following classes:[Positive,Negative] <separator> Text:you look very nice today <separator> Prediction:
Pós-processamento de saída
As saídas do modelo são tokens com várias probabilidades. Normalmente, para
gerar texto, você seleciona entre os tokens mais prováveis e
constrói frases, parágrafos ou até documentos completos. No entanto, para fins
de classificação, o que realmente importa é se o modelo acredita que
Positive é mais provável do que Negative ou vice-versa.
Considerando o modelo que você instanciar anteriormente, é assim que você pode processar a saída
nas probabilidades independentes de o próximo token ser Positive ou
Negative, respectivamente:
import numpy as np
def compute_output_probability(
model: keras_nlp.models.GemmaCausalLM,
prompt: str,
target_classes: list[str],
) -> dict[str, float]:
# Shorthands.
preprocessor = model.preprocessor
tokenizer = preprocessor.tokenizer
# NOTE: If a token is not found, it will be considered same as "<unk>".
token_unk = tokenizer.token_to_id('<unk>')
# Identify the token indices, which is the same as the ID for this tokenizer.
token_ids = [tokenizer.token_to_id(word) for word in target_classes]
# Throw an error if one of the classes maps to a token outside the vocabulary.
if any(token_id == token_unk for token_id in token_ids):
raise ValueError('One of the target classes is not in the vocabulary.')
# Preprocess the prompt in a single batch. This is done one sample at a time
# for illustration purposes, but it would be more efficient to batch prompts.
preprocessed = model.preprocessor.generate_preprocess([prompt])
# Identify output token offset.
padding_mask = preprocessed["padding_mask"]
token_offset = keras.ops.sum(padding_mask) - 1
# Score outputs, extract only the next token's logits.
vocab_logits = model.score(
token_ids=preprocessed["token_ids"],
padding_mask=padding_mask,
)[0][token_offset]
# Compute the relative probability of each of the requested tokens.
token_logits = [vocab_logits[ix] for ix in token_ids]
logits_tensor = keras.ops.convert_to_tensor(token_logits)
probabilities = keras.activations.softmax(logits_tensor)
return dict(zip(target_classes, probabilities.numpy()))
Para testar essa função, execute-a com o comando criado anteriormente:
compute_output_probability(
model=model,
prompt=prompt,
target_classes=['Positive', 'Negative'],
)
{'Positive': 0.99994016, 'Negative': 5.984089e-05}
Como agrupar tudo como um classificador
Para facilitar o uso, você pode agrupar todas as funções que acabou de criar em um
classificador semelhante ao sklearn com funções conhecidas e fáceis de usar, como
predict() e predict_score().
import dataclasses
@dataclasses.dataclass(frozen=True)
class AgileClassifier:
"""Agile classifier to be wrapped around a LLM."""
# The classes whose probability will be predicted.
labels: tuple[str, ...]
# Provide default instructions and control tokens, can be overridden by user.
instructions: str = 'Classify the following text into one of the following classes'
separator_token: str = '<separator>'
end_of_text_token: str = '<eos>'
def encode_for_prediction(self, x_text: str) -> str:
return preprocess_text(
text=x_text,
labels=self.labels,
instructions=self.instructions,
separator=self.separator_token,
)
def encode_for_training(self, x_text: str, y: int) -> str:
return ''.join([
self.encode_for_prediction(x_text),
self.labels[y],
self.end_of_text_token,
])
def predict_score(
self,
model: keras_nlp.models.GemmaCausalLM,
x_text: str,
) -> list[float]:
prompt = self.encode_for_prediction(x_text)
token_probabilities = compute_output_probability(
model=model,
prompt=prompt,
target_classes=self.labels,
)
return [token_probabilities[token] for token in self.labels]
def predict(
self,
model: keras_nlp.models.GemmaCausalLM,
x_eval: str,
) -> int:
return np.argmax(self.predict_score(model, x_eval))
agile_classifier = AgileClassifier(labels=('Positive', 'Negative'))
Ajuste fino do modelo
LoRA significa "adaptação de baixa classificação". É uma técnica de ajuste fino que pode ser usada para ajustar com eficiência modelos de linguagem grandes. Leia mais sobre isso no artigo LoRA: adaptação de baixa classificação de modelos de linguagem grandes.
A implementação do Keras do Gemma fornece um método enable_lora() que pode ser
usado para ajustes finos:
# Enable LoRA for the model and set the LoRA rank to 4.
model.backbone.enable_lora(rank=4)
Depois de ativar o LoRA, você pode iniciar o processo de ajuste fino. Isso leva aproximadamente 5 minutos por época no Colab:
import tensorflow as tf
# Create dataset with preprocessed text + labels.
map_fn = lambda x: agile_classifier.encode_for_training(*x)
x_train = list(map(map_fn, df_train[['comment', 'hateful']].values))
ds_train = tf.data.Dataset.from_tensor_slices(x_train).batch(2)
# Compile the model using the Adam optimizer and appropriate loss function.
model.compile(
loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer=keras.optimizers.Adam(learning_rate=0.0005),
weighted_metrics=[keras.metrics.SparseCategoricalAccuracy()],
)
# Begin training.
model.fit(ds_train, epochs=4)
Epoch 1/4 400/400 ━━━━━━━━━━━━━━━━━━━━ 354s 703ms/step - loss: 1.1365 - sparse_categorical_accuracy: 0.5874 Epoch 2/4 400/400 ━━━━━━━━━━━━━━━━━━━━ 338s 716ms/step - loss: 0.7579 - sparse_categorical_accuracy: 0.6662 Epoch 3/4 400/400 ━━━━━━━━━━━━━━━━━━━━ 324s 721ms/step - loss: 0.6818 - sparse_categorical_accuracy: 0.6894 Epoch 4/4 400/400 ━━━━━━━━━━━━━━━━━━━━ 323s 725ms/step - loss: 0.5922 - sparse_categorical_accuracy: 0.7220 <keras.src.callbacks.history.History at 0x7eb7e369c490>
O treinamento para mais épocas resulta em maior precisão, até que ocorra a superadaptação.
Inspecionar os resultados
Agora você pode inspecionar a saída do classificador ágil que acabou de treinar. Esse código vai gerar a pontuação da classe prevista com base em um trecho de texto:
text = 'you look really nice today'
scores = agile_classifier.predict_score(model, text)
dict(zip(agile_classifier.labels, scores))
{'Positive': 0.99899644, 'Negative': 0.0010035498}
Model Evaluation
Por fim, você vai avaliar o desempenho do modelo usando duas métricas comuns: a pontuação F1 e a AUC-ROC. A pontuação F1 captura erros falsos negativos e falsos positivos avaliando a média harmônica da precisão e do recall em um determinado limite de classificação. O AUC-ROC, por outro lado, captura a compensação entre a taxa de verdadeiro positivo e a taxa de falso positivo em vários limites e calcula a área sob essa curva.
y_true = df_test['hateful'].values
# Compute the scores (aka probabilities) for each of the labels.
y_score = [agile_classifier.predict_score(model, x) for x in df_test['comment']]
# The label with highest score is considered the predicted class.
y_pred = np.argmax(y_score, axis=1)
# Extract the probability of a comment being considered hateful.
y_prob = [x[agile_classifier.labels.index('Negative')] for x in y_score]
from sklearn.metrics import f1_score, roc_auc_score
print(f'F1: {f1_score(y_true, y_pred):.2f}')
print(f'AUC-ROC: {roc_auc_score(y_true, y_prob):.2f}')
F1: 0.84 AUC-ROC: 0.88
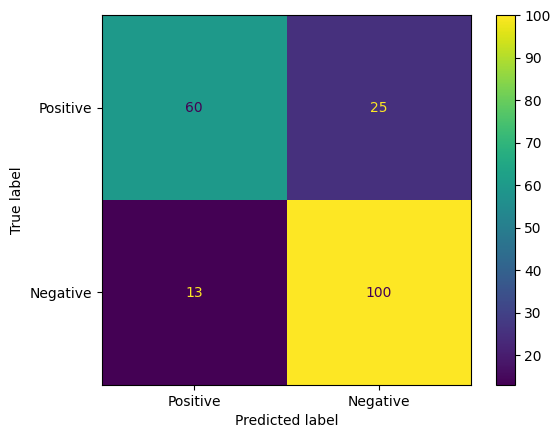
Outra maneira interessante de avaliar as previsões do modelo são as matrizes de confusão. Uma matriz de confusão vai mostrar visualmente os diferentes tipos de erros de previsão.
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
cm = confusion_matrix(y_true, y_pred)
ConfusionMatrixDisplay(
confusion_matrix=cm,
display_labels=agile_classifier.labels,
).plot()
<sklearn.metrics._plot.confusion_matrix.ConfusionMatrixDisplay at 0x7eb7e2d29ab0>
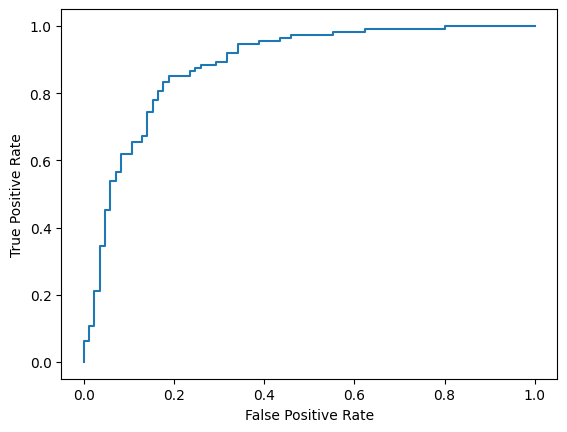
Por fim, você também pode analisar a curva ROC para ter uma ideia dos possíveis erros de previsão com diferentes limites de pontuação.
from sklearn.metrics import RocCurveDisplay, roc_curve
fpr, tpr, _ = roc_curve(y_true, y_prob, pos_label=1)
RocCurveDisplay(fpr=fpr, tpr=tpr).plot()
<sklearn.metrics._plot.roc_curve.RocCurveDisplay at 0x7eb4d130ef20>
Apêndice
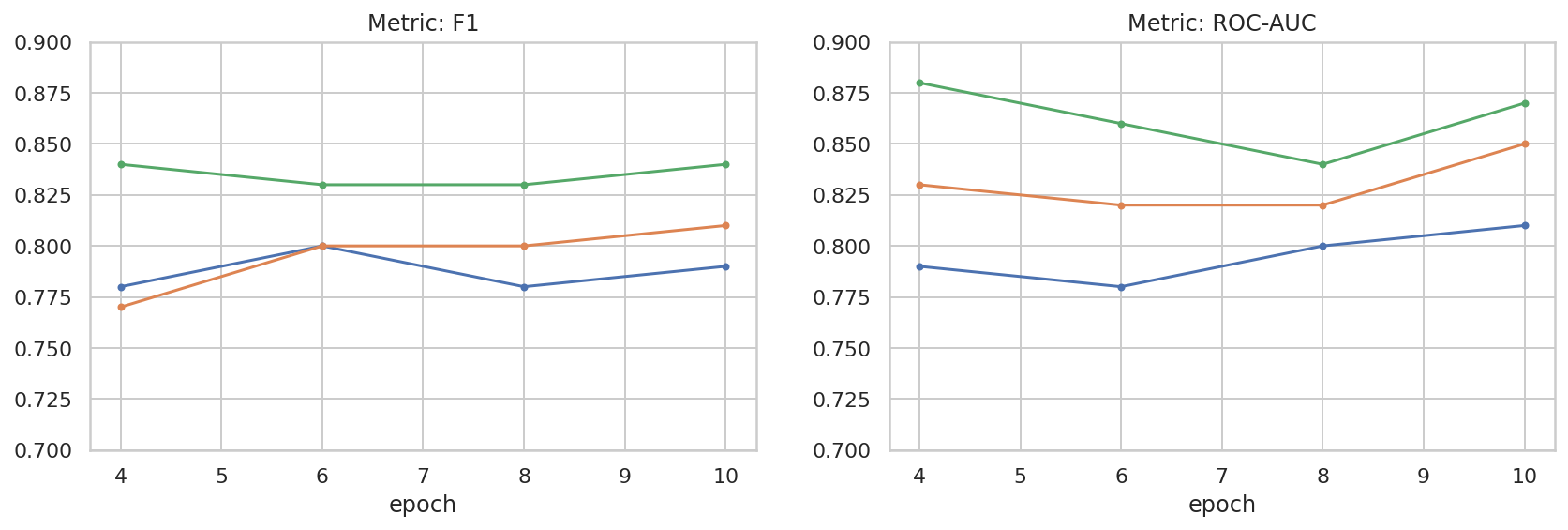
Fizemos uma análise básica do espaço de hiperparâmetros para entender melhor a relação entre o tamanho do conjunto de dados e a performance. Confira o gráfico a seguir.
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
sns.set_theme(style="whitegrid")
results_f1 = pd.DataFrame([
{'training_size': 800, 'epoch': 4, 'metric': 'f1', 'score': 0.84},
{'training_size': 800, 'epoch': 6, 'metric': 'f1', 'score': 0.83},
{'training_size': 800, 'epoch': 8, 'metric': 'f1', 'score': 0.83},
{'training_size': 800, 'epoch': 10, 'metric': 'f1', 'score': 0.84},
{'training_size': 400, 'epoch': 4, 'metric': 'f1', 'score': 0.77},
{'training_size': 400, 'epoch': 6, 'metric': 'f1', 'score': 0.80},
{'training_size': 400, 'epoch': 8, 'metric': 'f1', 'score': 0.80},
{'training_size': 400, 'epoch': 10,'metric': 'f1', 'score': 0.81},
{'training_size': 200, 'epoch': 4, 'metric': 'f1', 'score': 0.78},
{'training_size': 200, 'epoch': 6, 'metric': 'f1', 'score': 0.80},
{'training_size': 200, 'epoch': 8, 'metric': 'f1', 'score': 0.78},
{'training_size': 200, 'epoch': 10, 'metric': 'f1', 'score': 0.79},
])
results_roc_auc = pd.DataFrame([
{'training_size': 800, 'epoch': 4, 'metric': 'roc-auc', 'score': 0.88},
{'training_size': 800, 'epoch': 6, 'metric': 'roc-auc', 'score': 0.86},
{'training_size': 800, 'epoch': 8, 'metric': 'roc-auc', 'score': 0.84},
{'training_size': 800, 'epoch': 10, 'metric': 'roc-auc', 'score': 0.87},
{'training_size': 400, 'epoch': 4, 'metric': 'roc-auc', 'score': 0.83},
{'training_size': 400, 'epoch': 6, 'metric': 'roc-auc', 'score': 0.82},
{'training_size': 400, 'epoch': 8, 'metric': 'roc-auc', 'score': 0.82},
{'training_size': 400, 'epoch': 10,'metric': 'roc-auc', 'score': 0.85},
{'training_size': 200, 'epoch': 4, 'metric': 'roc-auc', 'score': 0.79},
{'training_size': 200, 'epoch': 6, 'metric': 'roc-auc', 'score': 0.78},
{'training_size': 200, 'epoch': 8, 'metric': 'roc-auc', 'score': 0.80},
{'training_size': 200, 'epoch': 10, 'metric': 'roc-auc', 'score': 0.81},
])
plot_opts = dict(style='.-', ylim=(0.7, 0.9))
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(14, 4))
process_results_df = lambda df: df.set_index('epoch').groupby('training_size')['score']
process_results_df(results_f1).plot(title='Metric: F1', ax=ax1, **plot_opts)
process_results_df(results_roc_auc).plot(title='Metric: ROC-AUC', ax=ax2, **plot_opts)
fig.show()