
ईमेल वगैरह के ज़रिए ग्राहकों के सवालों के जवाब देना, कई कारोबारों के लिए ज़रूरी होता है. हालांकि, यह काम काफ़ी मुश्किल हो सकता है. थोड़ी कोशिश करके, Gemma जैसे आर्टिफ़िशियल इंटेलिजेंस (एआई) मॉडल की मदद से इस काम को आसान बनाया जा सकता है.
हर कारोबार, ईमेल जैसी क्वेरी को अलग-अलग तरीके से हैंडल करता है. इसलिए, यह ज़रूरी है कि आप जनरेटिव एआई जैसी टेक्नोलॉजी को अपने कारोबार की ज़रूरतों के हिसाब से इस्तेमाल कर पाएं. इस प्रोजेक्ट में, बेकरी को मिले ईमेल से ऑर्डर की जानकारी निकालने की समस्या को हल किया गया है. इस जानकारी को स्ट्रक्चर्ड डेटा में बदला जाता है, ताकि इसे ऑर्डर मैनेज करने वाले सिस्टम में तुरंत जोड़ा जा सके. Gemma मॉडल को ट्यून किया जा सकता है. इसके लिए, आपको 10 से 20 उदाहरण देने होंगे. इनमें, ग्राहकों की पूछताछ और आपको मिलने वाले जवाब शामिल होने चाहिए. इससे, आपको अपने ग्राहकों के ईमेल प्रोसेस करने, उनके सवालों के जवाब तुरंत देने, और अपने मौजूदा कारोबारी सिस्टम के साथ इंटिग्रेट करने में मदद मिलेगी. इस प्रोजेक्ट को एआई ऐप्लिकेशन पैटर्न के तौर पर बनाया गया है. इसे अपने कारोबार के लिए Gemma मॉडल से फ़ायदा पाने के लिए, बढ़ाया और अडैप्ट किया जा सकता है.
प्रोजेक्ट और इसे बढ़ाने के तरीके के बारे में वीडियो की खास जानकारी के लिए, Business Email AI Assistant Build with Google AI वीडियो देखें. इसमें, इसे बनाने वाले लोगों से मिली अहम जानकारी भी शामिल है. इस प्रोजेक्ट के कोड की समीक्षा, Gemma Cookbook की कोड रिपॉज़िटरी में जाकर भी की जा सकती है. इसके अलावा, प्रोजेक्ट को बढ़ाने के लिए यहां दिए गए निर्देशों का पालन करें.
खास जानकारी
इस ट्यूटोरियल में, Gemma, Python, और Flask का इस्तेमाल करके बनाए गए, कारोबार के लिए ईमेल लिखने में मदद करने वाले ऐप्लिकेशन को सेट अप करने, चलाने, और बढ़ाने का तरीका बताया गया है. इस प्रोजेक्ट में, बुनियादी वेब यूज़र इंटरफ़ेस उपलब्ध कराया जाता है. इसमें अपनी ज़रूरतों के हिसाब से बदलाव किया जा सकता है. इस ऐप्लिकेशन को, ग्राहक के ईमेल से डेटा निकालने के लिए बनाया गया है. यह डेटा, एक काल्पनिक बेकरी के लिए स्ट्रक्चर किया जाता है. इस ऐप्लिकेशन पैटर्न का इस्तेमाल, कारोबार से जुड़े किसी भी ऐसे काम के लिए किया जा सकता है जिसमें टेक्स्ट इनपुट और टेक्स्ट आउटपुट का इस्तेमाल किया जाता है.
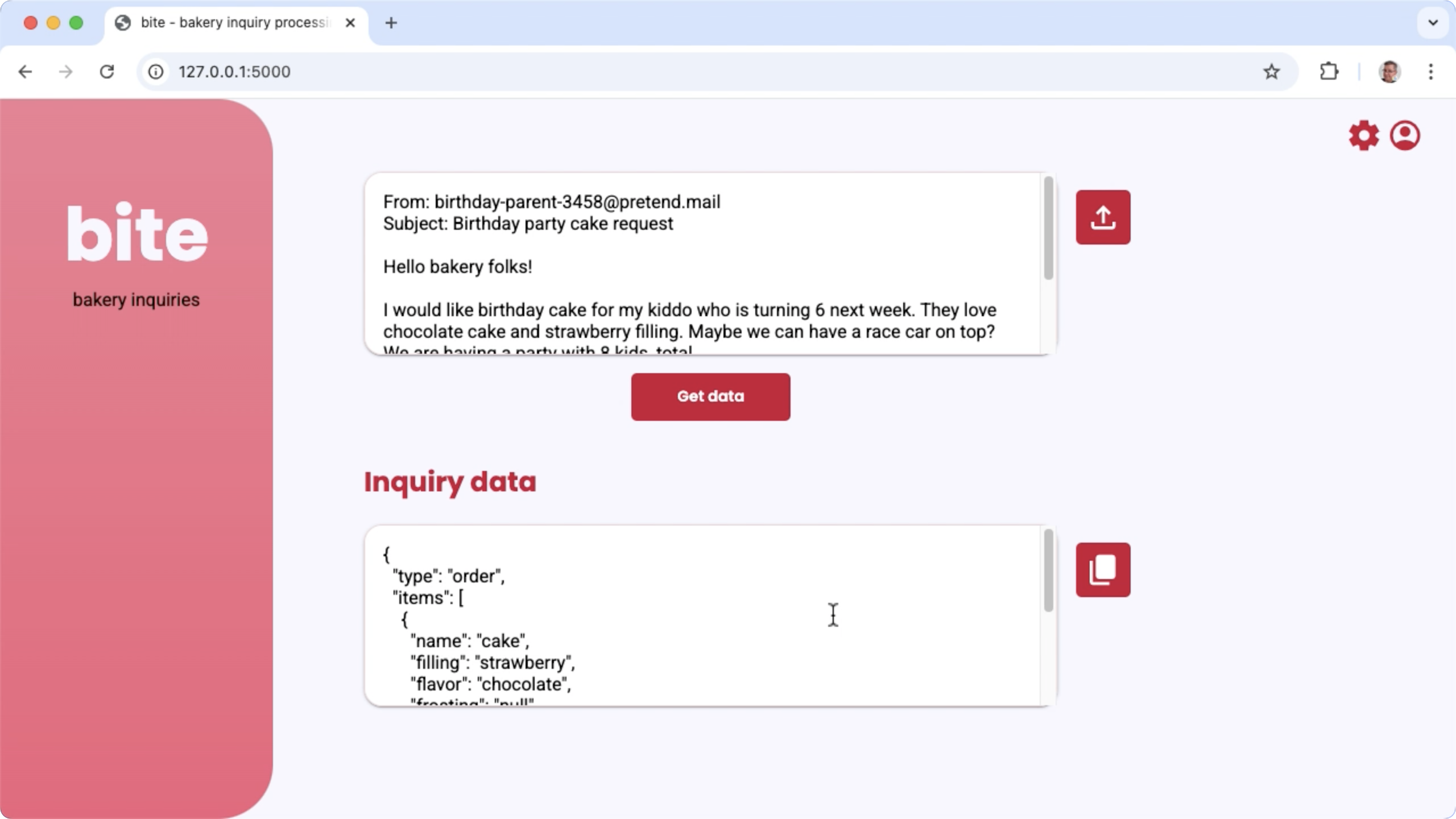
पहली इमेज. बेकरी से जुड़े ईमेल के सवालों को प्रोसेस करने के लिए प्रोजेक्ट यूज़र इंटरफ़ेस
हार्डवेयर की ज़रूरी शर्तें
ट्यूनिंग की इस प्रोसेस को ऐसे कंप्यूटर पर चलाएं जिसमें ग्राफ़िक्स प्रोसेसिंग यूनिट (जीपीयू) या टेंसर प्रोसेसिंग यूनिट (टीपीयू) हो. साथ ही, उसमें मौजूदा मॉडल और ट्यूनिंग डेटा को सेव करने के लिए, ज़रूरत के हिसाब से जीपीयू या टीपीयू मेमोरी हो. इस प्रोजेक्ट में ट्यूनिंग कॉन्फ़िगरेशन को चलाने के लिए, आपको करीब 16 जीबी GPU मेमोरी, इतनी ही रेगुलर रैम, और कम से कम 50 जीबी डिस्क स्पेस की ज़रूरत होगी.
इस ट्यूटोरियल में, Gemma मॉडल ट्यूनिंग के हिस्से को Colab एनवायरमेंट में चलाया जा सकता है. इसके लिए, T4 GPU रनटाइम का इस्तेमाल करें. अगर इस प्रोजेक्ट को Google Cloud के वीएम इंस्टेंस पर बनाया जा रहा है, तो इन ज़रूरी शर्तों के मुताबिक इंस्टेंस को कॉन्फ़िगर करें:
- जीपीयू हार्डवेयर: इस प्रोजेक्ट को चलाने के लिए, NVIDIA T4 की ज़रूरत होती है. हालांकि, NVIDIA L4 या इसके बाद के वर्शन का इस्तेमाल करने का सुझाव दिया जाता है
- ऑपरेटिंग सिस्टम: Linux पर डीप लर्निंग का विकल्प चुनें. खास तौर पर, पहले से इंस्टॉल किए गए जीपीयू सॉफ़्टवेयर ड्राइवर के साथ CUDA 12.3 M124 के साथ डीप लर्निंग वीएम चुनें.
- बूट डिस्क का साइज़: अपने डेटा, मॉडल, और सॉफ़्टवेयर के लिए, कम से कम 50 जीबी डिस्क स्पेस उपलब्ध कराएं.
प्रोजेक्ट सेटअप करना
इन निर्देशों में, इस प्रोजेक्ट को डेवलपमेंट और टेस्टिंग के लिए तैयार करने का तरीका बताया गया है. सेटअप करने के सामान्य चरणों में, ज़रूरी सॉफ़्टवेयर इंस्टॉल करना, कोड रिपॉज़िटरी से प्रोजेक्ट को क्लोन करना, कुछ एनवायरमेंट वैरिएबल सेट करना, Python लाइब्रेरी इंस्टॉल करना, और वेब ऐप्लिकेशन की जांच करना शामिल है.
इंस्टॉल और कॉन्फ़िगर करना
यह प्रोजेक्ट, पैकेज मैनेज करने और ऐप्लिकेशन चलाने के लिए Python 3 और वर्चुअल एनवायरमेंट (venv) का इस्तेमाल करता है. यहां दिए गए इंस्टॉलेशन के निर्देश, Linux होस्ट मशीन के लिए हैं.
ज़रूरी सॉफ़्टवेयर इंस्टॉल करने के लिए:
Python 3 और Python के लिए
venvवर्चुअल एनवायरमेंट पैकेज इंस्टॉल करें:sudo apt update sudo apt install git pip python3-venv
प्रोजेक्ट का क्लोन बनाना
प्रोजेक्ट कोड को अपने डेवलपमेंट कंप्यूटर पर डाउनलोड करें. प्रोजेक्ट का सोर्स कोड पाने के लिए, आपको git सोर्स कंट्रोल सॉफ़्टवेयर की ज़रूरत होगी.
प्रोजेक्ट कोड डाउनलोड करने के लिए:
नीचे दिए गए कमांड का इस्तेमाल करके, git रिपॉज़िटरी को क्लोन करें:
git clone https://github.com/google-gemini/gemma-cookbook.gitअगर चाहें, तो अपनी लोकल Git रिपॉज़िटरी को स्पार्स चेकआउट का इस्तेमाल करने के लिए कॉन्फ़िगर करें, ताकि आपके पास सिर्फ़ प्रोजेक्ट की फ़ाइलें हों:
cd gemma-cookbook/ git sparse-checkout set Demos/business-email-assistant/ git sparse-checkout init --cone
Python लाइब्रेरी इंस्टॉल करना
Python पैकेज और डिपेंडेंसी मैनेज करने के लिए, venv Python वर्चुअल एनवायरमेंट चालू करके Python लाइब्रेरी इंस्टॉल करें. पक्का करें कि आपने pip इंस्टॉलर की मदद से Python लाइब्रेरी इंस्टॉल करने से पहले, Python वर्चुअल एनवायरमेंट चालू कर लिया हो. Python वर्चुअल एनवायरमेंट इस्तेमाल करने के बारे में ज़्यादा जानने के लिए, Python venv का दस्तावेज़ देखें.
Python लाइब्रेरी इंस्टॉल करने के लिए:
टर्मिनल विंडो में,
business-email-assistantडायरेक्ट्री पर जाएं:cd Demos/business-email-assistant/इस प्रोजेक्ट के लिए, Python वर्चुअल एनवायरमेंट (venv) को कॉन्फ़िगर करें और चालू करें:
python3 -m venv venv source venv/bin/activatesetup_pythonस्क्रिप्ट का इस्तेमाल करके, इस प्रोजेक्ट के लिए ज़रूरी Python लाइब्रेरी इंस्टॉल करें:./setup_python.sh
एनवायरमेंट वैरिएबल सेट करना
इस प्रोजेक्ट को चलाने के लिए, कुछ एनवायरमेंट वैरिएबल की ज़रूरत होती है. इनमें Kaggle का उपयोगकर्ता नाम और Kaggle का एपीआई टोकन शामिल है. Gemma मॉडल डाउनलोड करने के लिए, आपके पास Kaggle खाता होना चाहिए. साथ ही, आपको Gemma मॉडल के ऐक्सेस का अनुरोध करना होगा. इस प्रोजेक्ट के लिए, आपको दो .env फ़ाइलों में अपना Kaggle उपयोगकर्ता नाम और Kaggle API टोकन जोड़ना होगा. इन्हें वेब ऐप्लिकेशन और ट्यूनिंग प्रोग्राम, दोनों ही पढ़ सकते हैं.
एनवायरमेंट वैरिएबल सेट करने के लिए:
- Kaggle के दस्तावेज़ में दिए गए निर्देशों का पालन करके, अपना Kaggle उपयोगकर्ता नाम और टोकन कुंजी पाएं.
- Gemma Setup पेज पर, Gemma का ऐक्सेस पाएं निर्देशों का पालन करके, Gemma मॉडल का ऐक्सेस पाएं.
- प्रोजेक्ट के लिए एनवायरमेंट वैरिएबल फ़ाइलें बनाएं. इसके लिए, प्रोजेक्ट के क्लोन में इन जगहों पर
.envटेक्स्ट फ़ाइल बनाएं:email-processing-webapp/.env model-tuning/.env
.envटेक्स्ट फ़ाइलें बनाने के बाद, दोनों फ़ाइलों में ये सेटिंग जोड़ें:KAGGLE_USERNAME=<YOUR_KAGGLE_USERNAME_HERE> KAGGLE_KEY=<YOUR_KAGGLE_KEY_HERE>
ऐप्लिकेशन को चलाएं और उसकी जांच करें
प्रोजेक्ट को इंस्टॉल और कॉन्फ़िगर करने के बाद, वेब ऐप्लिकेशन चलाएं. इससे यह पुष्टि की जा सकेगी कि आपने इसे सही तरीके से कॉन्फ़िगर किया है. आपको अपने इस्तेमाल के लिए प्रोजेक्ट में बदलाव करने से पहले, इसकी जांच करनी चाहिए.
प्रोजेक्ट को चलाने और उसकी जांच करने के लिए:
टर्मिनल विंडो में,
email-processing-webappडायरेक्ट्री पर जाएं:cd business-email-assistant/email-processing-webapp/run_appस्क्रिप्ट का इस्तेमाल करके, ऐप्लिकेशन चलाएं:./run_app.shवेब ऐप्लिकेशन शुरू करने के बाद, प्रोग्राम कोड में एक यूआरएल दिखता है. इस यूआरएल पर जाकर, ब्राउज़ किया जा सकता है और जांच की जा सकती है. आम तौर पर, यह पता यह होता है:
http://127.0.0.1:5000/वेब इंटरफ़ेस में, पहले इनपुट फ़ील्ड के नीचे मौजूद डेटा पाएं बटन दबाकर, मॉडल से जवाब जनरेट करें.
ऐप्लिकेशन चलाने के बाद, मॉडल से पहला जवाब मिलने में ज़्यादा समय लगता है. ऐसा इसलिए होता है, क्योंकि पहली जनरेशन के रन पर, मॉडल को शुरू करने के चरणों को पूरा करना होता है. पहले से चल रहे वेब ऐप्लिकेशन पर, प्रॉम्प्ट से जुड़े अनुरोधों और जनरेशन को कम समय में पूरा किया जा सकता है.
आवेदन की समयसीमा बढ़ाना
ऐप्लिकेशन चालू होने के बाद, उपयोगकर्ता इंटरफ़ेस और कारोबार के लॉजिक में बदलाव करके इसे बढ़ाया जा सकता है. इससे यह ऐप्लिकेशन, आपके या आपके कारोबार से जुड़े कामों के लिए काम करेगा. ऐप्लिकेशन कोड का इस्तेमाल करके, Gemma मॉडल के व्यवहार में भी बदलाव किया जा सकता है. इसके लिए, आपको प्रॉम्प्ट के उन कॉम्पोनेंट में बदलाव करना होगा जिन्हें ऐप्लिकेशन, जनरेटिव एआई मॉडल को भेजता है.
ऐप्लिकेशन, मॉडल को निर्देश देता है. साथ ही, उपयोगकर्ता से मिले इनपुट डेटा के साथ मॉडल का पूरा प्रॉम्प्ट भी देता है. मॉडल के व्यवहार में बदलाव करने के लिए, इन निर्देशों में बदलाव किया जा सकता है. जैसे, जनरेट किए जाने वाले JSON के पैरामीटर के नाम और स्ट्रक्चर के बारे में बताना. मॉडल के व्यवहार में बदलाव करने का एक आसान तरीका यह है कि मॉडल के जवाब के लिए अतिरिक्त निर्देश या दिशा-निर्देश दिए जाएं. जैसे, यह तय करना कि जनरेट किए गए जवाबों में कोई मार्कडाउन फ़ॉर्मैटिंग शामिल नहीं होनी चाहिए.
प्रॉम्प्ट के निर्देशों में बदलाव करने के लिए:
- डेवलपमेंट प्रोजेक्ट में,
business-email-assistant/email-processing-webapp/app.pyकोड फ़ाइल खोलें. app.pyकोड में,get_prompt():फ़ंक्शन में अतिरिक्त निर्देश जोड़ें:def get_prompt(): return """ Extract the relevant details of this request and return them in JSON code, with no additional markdown formatting:\n"""
इस उदाहरण में, निर्देशों में "with no additional markdown formatting" वाक्यांश जोड़ा गया है.
प्रॉम्प्ट में ज़्यादा जानकारी देने से, जनरेट किए गए आउटपुट पर काफ़ी असर पड़ सकता है. साथ ही, इसे लागू करने में ज़्यादा मेहनत नहीं लगती. आपको सबसे पहले इस तरीके को आज़माना चाहिए, ताकि यह देखा जा सके कि मॉडल से आपको मनमुताबिक नतीजे मिल रहे हैं या नहीं. हालांकि, Gemma मॉडल के व्यवहार में बदलाव करने के लिए, प्रॉम्प्ट के निर्देशों का इस्तेमाल करने की कुछ सीमाएं हैं. खास तौर पर, मॉडल के लिए इनपुट टोकन की कुल सीमा, जो Gemma 2 के लिए 8,192 टोकन है. इसके लिए, आपको प्रॉम्प्ट में दिए गए निर्देशों और नए डेटा के साइज़ के बीच संतुलन बनाए रखना होगा, ताकि आप उस सीमा से ज़्यादा न हों.
मॉडल को ट्यून करना
किसी खास टास्क के लिए, Gemma मॉडल से ज़्यादा भरोसेमंद जवाब पाने के लिए, फ़ाइन-ट्यूनिंग करने का सुझाव दिया जाता है. खास तौर पर, अगर आपको मॉडल से किसी खास स्ट्रक्चर में JSON जनरेट कराना है, जिसमें खास तौर पर नाम वाले पैरामीटर शामिल हैं, तो आपको मॉडल को उस तरह से ट्यून करना चाहिए. मॉडल से जो काम कराना है उसके हिसाब से, 10 से 20 उदाहरणों की मदद से बुनियादी फ़ंक्शनलिटी हासिल की जा सकती है. ट्यूटोरियल के इस सेक्शन में, किसी खास टास्क के लिए Gemma मॉडल पर फ़ाइन-ट्यूनिंग को सेट अप करने और उसे चलाने का तरीका बताया गया है.
यहां दिए गए निर्देशों में बताया गया है कि वर्चुअल मशीन एनवायरमेंट पर फ़ाइन-ट्यूनिंग कैसे की जाती है. हालांकि, इस प्रोजेक्ट के लिए Colab नोटबुक का इस्तेमाल करके भी फ़ाइन-ट्यूनिंग की जा सकती है.
हार्डवेयर की ज़रूरी शर्तें
फ़ाइन-ट्यूनिंग के लिए कंप्यूट की ज़रूरतें, प्रोजेक्ट के बाकी हिस्सों के लिए हार्डवेयर की ज़रूरी शर्तों के जैसी ही होती हैं. अगर इनपुट टोकन की संख्या 256 और बैच साइज़ 1 तक सीमित है, तो Colab एनवायरमेंट में T4 GPU रनटाइम के साथ ट्यूनिंग ऑपरेशन चलाया जा सकता है.
डेटा तैयार करना
Gemma मॉडल को ट्यून करने से पहले, आपको ट्यूनिंग के लिए डेटा तैयार करना होगा. किसी मॉडल को किसी खास टास्क के लिए ट्यून करते समय, आपको अनुरोध और जवाब के उदाहरणों के सेट की ज़रूरत होती है. इन उदाहरणों में, अनुरोध का टेक्स्ट बिना किसी निर्देश के और जवाब का अनुमानित टेक्स्ट दिखना चाहिए. शुरुआत में, आपको करीब 10 उदाहरणों वाला डेटासेट तैयार करना चाहिए. इन उदाहरणों में, अलग-अलग तरह के अनुरोध और उनके सही जवाब शामिल होने चाहिए. पक्का करें कि अनुरोध और जवाब बार-बार न दोहराए जा रहे हों. ऐसा होने पर, मॉडल के जवाब भी बार-बार दोहराए जा सकते हैं. साथ ही, अनुरोधों में होने वाले बदलावों के हिसाब से जवाब नहीं दिए जा सकते. अगर आपको स्ट्रक्चर्ड डेटा फ़ॉर्मैट में जवाब पाने के लिए मॉडल को ट्यून करना है, तो पक्का करें कि दिए गए सभी जवाब, उस डेटा आउटपुट फ़ॉर्मैट के मुताबिक हों जो आपको चाहिए. इस टेबल में, कोड के इस उदाहरण के डेटासेट के कुछ सैंपल रिकॉर्ड दिखाए गए हैं:
| अनुरोध | जवाब |
|---|---|
| नमस्ते इंडियन बेकरी सेंट्रल,\nक्या आपके पास 10 पेड़े और तीस बूंदी के लड्डू उपलब्ध हैं? क्या आपके पास वेनिला फ़्रॉस्टिंग और चॉकलेट फ़्लेवर वाले केक भी उपलब्ध हैं. मुझे 6 इंच का साइज़ चाहिए | { "type": "inquiry", "items": [ { "name": "pendas", "quantity": 10 }, { "name": "bundi ladoos", "quantity": 30 }, { "name": "cake", "filling": null, "frosting": "vanilla", "flavor": "chocolate", "size": "6 in" } ] } |
| हमने Google Maps पर आपका कारोबार देखा. क्या आपके यहाँ जलेबी और गुलाब जामुन मिलते हैं? | { "type": "inquiry", "items": [ { "name": "jellabi", "quantity": null }, { "name": "gulab jamun", "quantity": null } ] } |
पहली टेबल. बेकरी के ईमेल डेटा निकालने वाले टूल के लिए, ट्यूनिंग डेटासेट की आंशिक सूची.
डेटा फ़ॉर्मैट और लोडिंग
ट्यूनिंग डेटा को किसी भी फ़ॉर्मैट में सेव किया जा सकता है. जैसे, डेटाबेस रिकॉर्ड, JSON फ़ाइलें, CSV या सादे टेक्स्ट वाली फ़ाइलें. हालांकि, आपके पास Python कोड की मदद से रिकॉर्ड वापस पाने का तरीका होना चाहिए. यह प्रोजेक्ट, data डायरेक्ट्री से JSON फ़ाइलों को डिक्शनरी ऑब्जेक्ट के कलेक्शन में पढ़ता है.
इस उदाहरण ट्यूनिंग प्रोग्राम में, ट्यूनिंग डेटासेट को model-tuning/main.py फ़ंक्शन का इस्तेमाल करके model-tuning/main.py मॉड्यूल में लोड किया जाता है:prepare_tuning_dataset()
def prepare_tuning_dataset():
# collect data from JSON files
prompt_data = read_json_files_to_dicts("./data")
...
जैसा कि पहले बताया गया है, डेटासेट को ऐसे फ़ॉर्मैट में सेव किया जा सकता है जो आपके लिए सुविधाजनक हो. हालांकि, आपको अनुरोधों को उनसे जुड़े जवाबों के साथ वापस पाने की सुविधा मिलनी चाहिए. साथ ही, उन्हें टेक्स्ट स्ट्रिंग में असेंबल करने की सुविधा मिलनी चाहिए, जिसका इस्तेमाल ट्यूनिंग रिकॉर्ड के तौर पर किया जाता है.
ट्यूनिंग रिकॉर्ड इकट्ठा करना
ट्यूनिंग की प्रोसेस के लिए, प्रोग्राम हर अनुरोध और जवाब को एक स्ट्रिंग में इकट्ठा करता है. इसमें प्रॉम्प्ट के निर्देश और जवाब का कॉन्टेंट शामिल होता है. इसके बाद, ट्यूनिंग प्रोग्राम, स्ट्रिंग को टोकन में बदलता है, ताकि मॉडल इसका इस्तेमाल कर सके. model-tuning/main.py मॉड्यूल prepare_tuning_dataset() फ़ंक्शन में, ट्यूनिंग रिकॉर्ड को असेंबल करने का कोड यहां दिया गया है:
def prepare_tuning_dataset():
...
# prepare data for tuning
tuning_dataset = []
template = "{instruction}\n{response}"
for prompt in prompt_data:
tuning_dataset.append(template.format(instruction=prompt["prompt"],
response=prompt["response"]))
return tuning_dataset
यह फ़ंक्शन, डेटा को इनपुट के तौर पर लेता है और उसे फ़ॉर्मैट करता है. इसके लिए, निर्देश और जवाब के बीच लाइन ब्रेक जोड़ा जाता है.
मॉडल के वेट जनरेट करना
ट्यूनिंग का डेटा उपलब्ध होने और लोड होने के बाद, ट्यूनिंग प्रोग्राम चलाया जा सकता है. इस उदाहरण ऐप्लिकेशन के लिए ट्यूनिंग की प्रोसेस में, Keras NLP लाइब्रेरी का इस्तेमाल किया जाता है. इससे मॉडल को लो रैंक अडैप्टेशन या LoRA तकनीक के साथ ट्यून किया जाता है, ताकि नए मॉडल वेट जनरेट किए जा सकें. फ़ुल प्रिसिज़न ट्यूनिंग की तुलना में, LoRA का इस्तेमाल करने पर मेमोरी की खपत काफ़ी कम होती है. ऐसा इसलिए, क्योंकि यह मॉडल के वेट में होने वाले बदलावों का अनुमान लगाता है. इसके बाद, मॉडल के व्यवहार में बदलाव करने के लिए, अनुमानित वेट को मौजूदा मॉडल के वेट पर ओवरले किया जा सकता है.
ट्यूनिंग रन करने और नए वेट का हिसाब लगाने के लिए:
टर्मिनल विंडो में,
model-tuning/डायरेक्ट्री पर जाएं.cd business-email-assistant/model-tuning/tune_modelस्क्रिप्ट का इस्तेमाल करके, ट्यूनिंग की प्रोसेस चलाएं:./tune_model.sh
ट्यूनिंग की प्रोसेस में कई मिनट लगते हैं. यह आपके पास उपलब्ध कंप्यूट संसाधनों पर निर्भर करता है. ट्यूनिंग प्रोग्राम पूरा होने पर, model-tuning/weights डायरेक्ट्री में नए *.h5वेट फ़ाइलें सेव करता है. इनका फ़ॉर्मैट यह होता है:
gemma2-2b_inquiry_tuned_4_epoch##.lora.h5
समस्या का हल
अगर ट्यूनिंग पूरी नहीं होती है, तो इसकी दो वजहें हो सकती हैं:
- मेमोरी या संसाधनों का खत्म होना: ये गड़बड़ियां तब होती हैं, जब फ़ाइन-ट्यूनिंग की प्रोसेस में, उपलब्ध जीपीयू मेमोरी या सीपीयू मेमोरी से ज़्यादा मेमोरी का अनुरोध किया जाता है. पक्का करें कि ट्यूनिंग की प्रोसेस के दौरान, वेब ऐप्लिकेशन न चल रहा हो. अगर आपको 16 जीबी जीपीयू मेमोरी वाले डिवाइस पर ट्यूनिंग करनी है, तो पक्का करें कि
token_limitको 256 पर औरbatch_sizeको 1 पर सेट किया गया हो. - GPU ड्राइवर इंस्टॉल नहीं हैं या वे JAX के साथ काम नहीं करते: ट्यूनिंग की प्रोसेस के लिए, यह ज़रूरी है कि कंप्यूट डिवाइस में ऐसे हार्डवेयर ड्राइवर इंस्टॉल हों जो JAX लाइब्रेरी के वर्शन के साथ काम करते हों. ज़्यादा जानकारी के लिए, JAX इंस्टॉल करने से जुड़ा दस्तावेज़ देखें.
फ़ाइन-ट्यून किए गए मॉडल को डिप्लॉय करना
ट्यूनिंग की प्रोसेस, ट्यूनिंग डेटा और ट्यूनिंग ऐप्लिकेशन में सेट किए गए कुल इपॉक के आधार पर कई वेट जनरेट करती है. डिफ़ॉल्ट रूप से, ट्यूनिंग प्रोग्राम, मॉडल के वेट की तीन फ़ाइलें जनरेट करता है. हर फ़ाइल, ट्यूनिंग के एक इपॉक के लिए होती है. हर ट्यूनिंग इपोक, ऐसे वेट जनरेट करता है जो ट्यूनिंग डेटा के नतीजों को ज़्यादा सटीक तरीके से दिखाते हैं. ट्यूनिंग प्रोसेस के टर्मिनल आउटपुट में, हर इपोक के लिए सटीकता की दरें देखी जा सकती हैं. ये इस तरह दिखती हैं:
...
8/8 ━━━━━━━━━━━━━━━━━━━━ 121s 195ms/step - loss: 0.5432 - sparse_categorical_accuracy: 0.5982
Epoch 2/3
8/8 ━━━━━━━━━━━━━━━━━━━━ 2s 194ms/step - loss: 0.3320 - sparse_categorical_accuracy: 0.6966
Epoch 3/3
8/8 ━━━━━━━━━━━━━━━━━━━━ 2s 192ms/step - loss: 0.2135 - sparse_categorical_accuracy: 0.7848
आपको सटीकता दर को 0.80 के आस-पास रखना है, ताकि यह ज़्यादा न हो. साथ ही, इसे 1.00 के बहुत करीब भी नहीं रखना है. ऐसा इसलिए, क्योंकि इसका मतलब है कि वज़न, ट्यूनिंग डेटा को ओवरफ़िट करने के करीब पहुंच गए हैं. ऐसा होने पर, मॉडल उन अनुरोधों के लिए सही जवाब नहीं देता जो ट्यूनिंग के उदाहरणों से काफ़ी अलग होते हैं. डिफ़ॉल्ट रूप से, डिप्लॉयमेंट स्क्रिप्ट, ईपॉक 3 के वज़न चुनती है. आम तौर पर, इनकी सटीकता दर 0.80 के आस-पास होती है.
जनरेट किए गए वेट को वेब ऐप्लिकेशन पर डिप्लॉय करने के लिए:
टर्मिनल विंडो में,
model-tuningडायरेक्ट्री पर जाएं:cd business-email-assistant/model-tuning/deploy_weightsस्क्रिप्ट का इस्तेमाल करके, ट्यूनिंग की प्रोसेस चलाएं:./deploy_weights.sh
इस स्क्रिप्ट को चलाने के बाद, आपको email-processing-webapp/weights/ डायरेक्ट्री में एक नई *.h5 फ़ाइल दिखेगी.
नए मॉडल को आज़माना
ऐप्लिकेशन में नए वेट डिप्लॉय करने के बाद, अब आपको नए मॉडल को आज़माना चाहिए. इसके लिए, वेब ऐप्लिकेशन को फिर से चलाएं और जवाब जनरेट करें.
प्रोजेक्ट को चलाने और उसकी जांच करने के लिए:
टर्मिनल विंडो में,
email-processing-webappडायरेक्ट्री पर जाएं:cd business-email-assistant/email-processing-webapp/run_appस्क्रिप्ट का इस्तेमाल करके, ऐप्लिकेशन चलाएं:./run_app.shवेब ऐप्लिकेशन शुरू करने के बाद, प्रोग्राम कोड में एक यूआरएल दिखता है. इस यूआरएल पर जाकर, ब्राउज़ किया जा सकता है और जांच की जा सकती है. आम तौर पर, यह पता होता है:
http://127.0.0.1:5000/वेब इंटरफ़ेस में, पहले इनपुट फ़ील्ड के नीचे मौजूद डेटा पाएं बटन दबाकर, मॉडल से जवाब जनरेट करें.
आपने अब किसी ऐप्लिकेशन में Gemma मॉडल को ट्यून और डिप्लॉय कर दिया है! ऐप्लिकेशन के साथ एक्सपेरिमेंट करें और अपने टास्क के लिए, ट्यून किए गए मॉडल की जनरेट करने की क्षमता की सीमाओं का पता लगाने की कोशिश करें. अगर आपको ऐसे उदाहरण मिलते हैं जिनमें मॉडल ठीक से काम नहीं कर रहा है, तो उन अनुरोधों को ट्यूनिंग के उदाहरण वाले डेटा की सूची में जोड़ें. इसके लिए, अनुरोध जोड़ें और उसका सही जवाब दें. इसके बाद, ट्यूनिंग की प्रोसेस को फिर से चलाएं, नए वेट को फिर से डिप्लॉय करें, और आउटपुट की जांच करें.
अन्य संसाधन
इस प्रोजेक्ट के बारे में ज़्यादा जानने के लिए, Gemma Cookbook की कोड रिपॉज़िटरी देखें. अगर आपको ऐप्लिकेशन बनाने में मदद चाहिए या आपको अन्य डेवलपर के साथ मिलकर काम करना है, तो Google Developers Community Discord सर्वर पर जाएं. Google के एआई की मदद से बनाए गए अन्य प्रोजेक्ट के बारे में जानने के लिए, वीडियो प्लेलिस्ट देखें.