
Gemma 3
लाइटवेट और बेहतरीन ओपन मॉडल का कलेक्शन. इन्हें उसी रिसर्च और टेक्नोलॉजी का इस्तेमाल करके बनाया गया है जिसका इस्तेमाल हमारे Gemini 2.0 मॉडल में किया जाता है

मुश्किल टास्क पूरे करना
Gemma 3 की 128 हज़ार टोकन वाली कॉन्टेक्स्ट विंडो की मदद से, आपके ऐप्लिकेशन ज़्यादा जानकारी को प्रोसेस और समझ सकते हैं. इससे एआई की ज़्यादा बेहतर सुविधाएं मिलती हैं.

दुनिया भर में तुरंत पहुंचें
Gemma 3 की कई भाषाओं में काम करने की बेहतरीन सुविधाओं की मदद से, आसानी से अलग-अलग भाषाओं में बातचीत करें. दुनिया भर के दर्शकों तक पहुंचने वाले ऐप्लिकेशन बनाएं. ये ऐप्लिकेशन 140 से ज़्यादा भाषाओं में काम करते हैं.

शब्दों और इमेज को समझना
आसानी से ऐसे ऐप्लिकेशन बनाएं जो इमेज, टेक्स्ट, और वीडियो का विश्लेषण करते हैं. इससे इंटरैक्टिव और बेहतर ऐप्लिकेशन बनाने की नई संभावनाएं खुलती हैं.
दुनिया के सबसे बेहतर सिंगल-ऐक्सेलरेटर मॉडल का इस्तेमाल करके बनाएं


Gemma की मदद से मॉडल बनाना




जेमा की मदद से रिसर्च करना
बेहतर रिसर्च के लिए, खास Gemma मॉडल का बढ़ता कलेक्शन देखें.

TxGemma नया

ShieldGemma 2 नया
PaliGemma 2 नया
Gemma का स्कोप
Gemma 3 के बेंचमार्क को विज़ुअलाइज़ करना
एलएलएम के अलग-अलग मानदंडों के आधार पर, Gemma 3 के नतीजे देखने के लिए चार्ट के साथ इंटरैक्ट करें.
MMLU-Pro
एमएमएलयू बेंचमार्क एक ऐसा टेस्ट है जो प्री-ट्रेनिंग के दौरान, लार्ज लैंग्वेज मॉडल के ज़रिए हासिल किए गए ज्ञान और समस्या हल करने की क्षमता का आकलन करता है.
LiveCodeBench
LeetCode और Codeforces जैसे प्लैटफ़ॉर्म पर, असल दुनिया की कोडिंग से जुड़ी समस्याओं के लिए, कोड जनरेट करने की क्षमताओं का आकलन करता है.
dev
Bird-SQL
यह टेस्ट, किसी मॉडल की इस क्षमता की जांच करता है कि वह सामान्य भाषा में पूछे गए सवालों को अलग-अलग डोमेन में, जटिल SQL क्वेरी में कैसे बदलता है.
GPQA डायमंड
इस चैनल पर, जीव विज्ञान, भौतिक विज्ञान, और रसायन विज्ञान में पीएचडी करने वाले लोगों के लिखे गए मुश्किल सवालों के जवाब देने के लिए मॉडल को चुनौती दी जाती है.
SimpleQA
यह मेट्रिक, किसी मॉडल की इस क्षमता का आकलन करती है कि वह छोटे वाक्यांशों में, आसान और तथ्यों पर आधारित सवालों के जवाब दे सकता है या नहीं.
FACTS Grounding
यह जांच करता है कि दिए गए इनपुट दस्तावेज़ों के आधार पर, एलएलएम के जवाब तथ्यों के हिसाब से सही और ज़रूरत के मुताबिक जानकारी वाले हैं या नहीं.
MATH
MATH, किसी भाषा मॉडल की गणित के जटिल सवालों को हल करने की क्षमता का आकलन करता है. इसके लिए, रीज़निंग, कई चरणों में समस्या हल करने, और गणित के कॉन्सेप्ट को समझने की ज़रूरत होती है.
HiddenMath
प्रतियोगिता में शामिल गणित के सवालों का इंटरनल होल्डआउट सेट.
val
MMMU
यह मॉडल, अलग-अलग विषयों के बारे में, अलग-अलग तरीकों से समझने और तर्क करने की क्षमता का आकलन करता है. इसके लिए, कॉलेज लेवल की जानकारी की ज़रूरत होती है.
100%
75%
50%
25%
0%
100%
75%
50%
25%
0%
*अन्य तरीकों से परफ़ॉर्मेंस के बारे में जानकारी के लिए, तकनीकी रिपोर्ट देखें. तकनीकी रिपोर्ट पढ़ें

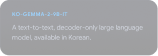

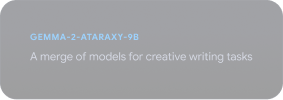
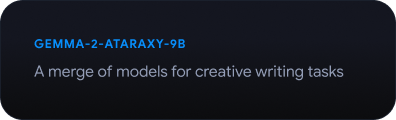

Gemmaverse को एक्सप्लोर करना
कम्यूनिटी के बनाए गए Gemma मॉडल और टूल का बड़ा नेटवर्क, जो आपके इनोवेशन को बढ़ावा देने और उसे प्रेरित करने के लिए तैयार है
डिप्लॉयमेंट का टारगेट चुनना
![]() मोबाइल
मोबाइल
Google के एआई एज (डिवाइस पर एआई) की मदद से, डिवाइस पर एआई मॉडल को डिप्लॉय करना
कम इंतज़ार और ऑफ़लाइन काम करने की सुविधा के लिए, सीधे डिवाइसों पर डिप्लॉय करें. यह उन ऐप्लिकेशन के लिए सही है जिन्हें रीयल-टाइम में जवाब देने और निजता की ज़रूरत होती है. जैसे, मोबाइल ऐप्लिकेशन, IoT डिवाइस, और एम्बेड किए गए सिस्टम.
![]() वेब
वेब
वेब ऐप्लिकेशन में आसानी से इंटिग्रेट किया जा सकता है
एआई की बेहतर सुविधाओं की मदद से, अपनी वेबसाइटों और वेब सेवाओं को बेहतर बनाएं. इन सुविधाओं की मदद से, इंटरैक्टिव सुविधाएं चालू की जा सकती हैं, उपयोगकर्ताओं के हिसाब से कॉन्टेंट दिखाया जा सकता है, और बेहतर ऑटोमेशन की सुविधाएं मिल सकती हैं.
![]() क्लाउड
क्लाउड
क्लाउड इन्फ़्रास्ट्रक्चर की मदद से, आसानी से स्केल करें
बड़े पैमाने पर डिप्लॉयमेंट, ज़्यादा काम करने वाले वर्कलोड, और एआई के जटिल ऐप्लिकेशन को मैनेज करने के लिए, क्लाउड के स्केलेबल और सुविधाजनक होने का फ़ायदा लें.