
Gemma 3
Gemini 2.0 モデルを支えるものと同じ研究とテクノロジーに基づいて構築された、軽量で最先端のオープンモデルのコレクション

複雑なタスクを処理する
Gemma 3 の 128,000 トークンのコンテキスト ウィンドウにより、アプリケーションは膨大な量の情報を処理して理解できるため、より高度な AI 機能を実現できます。

すぐにグローバル展開
Gemma 3 の比類のない多言語機能を活用して、言語を越えて簡単にコミュニケーションをとることができます。140 を超える言語に対応し、世界中のユーザーにリーチできるアプリを開発します。

単語と画像を理解する
画像、テキスト、動画を分析するアプリケーションを簡単に構築し、インタラクティブでインテリジェントなアプリケーションの新しい可能性を広げることができます。
世界最高のシングル アクセラレータ モデルで構築


Gemma で構築を開始する




Gemma で研究を推進する
高度な研究向けの Gemma モデルのコレクションをご確認ください。

TxGemma 新規

ShieldGemma 2新規
PaliGemma 2 新規
DataGemma
Gemma スコープ
Gemma 3 ベンチマークを可視化する
グラフを操作して、さまざまな LLM ベンチマークにおける Gemma 3 の結果を確認します。
MMLU-Pro
MMLU ベンチマークは、大規模言語モデルが事前トレーニング中に獲得した知識の広さと問題解決能力を測定するテストです。
LiveCodeBench
LeetCode や Codeforces などのプラットフォームの実際のコーディング問題でコード生成機能を評価します。
dev
Bird-SQL
さまざまなドメインの自然言語の質問を複雑な SQL クエリに変換するモデルの能力をテストします。
GPQA Diamond
生物学、物理学、化学の博士号取得者が作成した難しい問題でモデルをテストします。
SimpleQA
簡単な事実に関する質問に短いフレーズで回答するモデルの能力を評価します。
FACTS の根拠
指定された入力ドキュメントに基づいて、LLM の回答が事実に基づいて正確で十分に詳細であるかどうかを評価します。
MATH
MATH は、推論、複数ステップの問題解決、数学のコンセプトの理解を必要とする複雑な数学の問題を解く言語モデルの能力を評価します。
HiddenMath
競技の数学の問題の内部ホールドアウト セット。
val
MMMU
大学レベルの知識を必要とするさまざまな分野にわたるマルチモーダル理解と推論を評価します。
100%
75%
50%
25%
0%
100%
75%
50%
25%
0%
*他の手法でのパフォーマンスの詳細については、技術レポートをご覧ください。技術レポートを読む

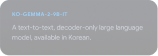

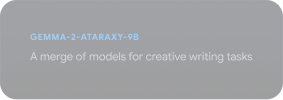
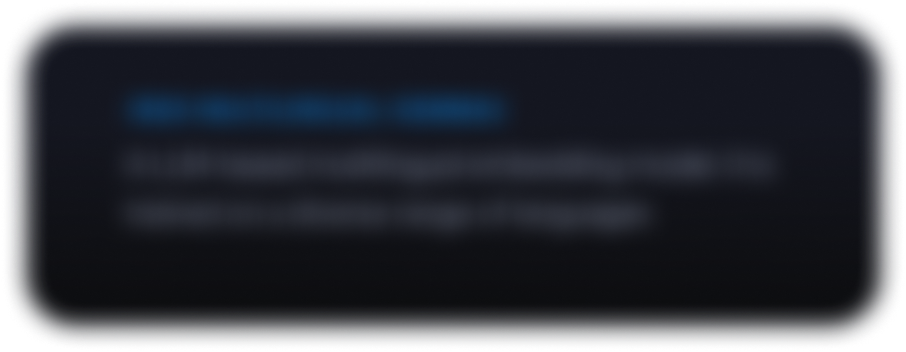
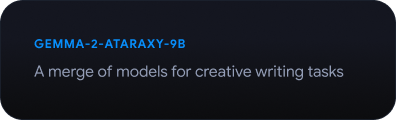

Gemmaverse を探索する
コミュニティが作成した Gemma モデルとツールの広大なエコシステム。イノベーションを推進し、刺激します。
デプロイ ターゲットを選択する
![]() モバイル
モバイル
Google AI Edge を使用してデバイスにデプロイする
デバイスに直接デプロイして、低レイテンシのオフライン機能を実現します。モバイルアプリ、IoT デバイス、組み込みシステムなど、リアルタイムの応答性とプライバシーが必要なアプリケーションに最適です。
![]() ウェブ
ウェブ
ウェブ アプリケーションにシームレスに統合
高度な AI 機能を使用してウェブサイトとウェブサービスを強化し、インタラクティブな機能、パーソナライズされたコンテンツ、インテリジェントな自動化を実現します。
![]() クラウド
クラウド
クラウド インフラストラクチャで簡単にスケーリングする
クラウドのスケーラビリティと柔軟性を活用して、大規模なデプロイ、負荷の高いワークロード、複雑な AI アプリケーションを処理します。
Google Cloud クレジットで学術研究を加速する
Google Cloud の Gemma 3 モデルを使用して、研究を進めましょう。今すぐ Google Cloud クレジットを申請して、研究の限界を押し広げ、科学コミュニティの発展に貢献しましょう。