
Présentation
Cette page décrit la conception et les étapes nécessaires pour convertir les opérations composites dans TensorFlow en opérations fusionnées dans LiteRT. Cette infrastructure est à usage général et permet de convertir n'importe quelle opération composite dans TensorFlow en une opération fusionnée correspondante dans LiteRT.
Un exemple d'utilisation de cette infrastructure est la fusion des opérations TensorFlow RNN dans LiteRT, comme indiqué ici.
Que sont les opérations fusionnées ?

Les opérations TensorFlow peuvent être des opérations primitives (par exemple, tf.add) ou être composées à partir d'autres opérations primitives (par exemple, tf.einsum). Une opération primitive apparaît sous la forme d'un seul nœud dans le graphe TensorFlow, tandis qu'une opération composite est une collection de nœuds dans le graphe TensorFlow. L'exécution d'une opération composite équivaut à l'exécution de chacune de ses opérations primitives constitutives.
Une opération fusionnée correspond à une seule opération qui englobe tous les calculs effectués par chaque opération primitive au sein de l'opération composite correspondante.
Avantages des opérations fusionnées
Les opérations fusionnées existent pour maximiser les performances de leurs implémentations de noyau sous-jacentes, en optimisant le calcul global et en réduisant l'empreinte mémoire. C'est très utile, en particulier pour les charges de travail d'inférence à faible latence et les plates-formes mobiles aux ressources limitées.
Les opérations fusionnées fournissent également une interface de niveau supérieur pour définir des transformations complexes telles que la quantification, qui seraient autrement irréalisables ou très difficiles à effectuer à un niveau plus précis.
LiteRT comporte de nombreuses instances d'opérations fusionnées pour les raisons évoquées ci-dessus. Ces opérations fusionnées correspondent généralement à des opérations composites dans le programme TensorFlow source. Parmi les exemples d'opérations composites dans TensorFlow qui sont implémentées en tant qu'opération fusionnée unique dans LiteRT, on trouve diverses opérations RNN telles que les opérations LSTM séquentielles unidirectionnelles et bidirectionnelles, la convolution (conv2d, bias add, relu), la couche entièrement connectée (matmul, bias add, relu) et plus encore. Dans LiteRT, la quantification LSTM n'est actuellement implémentée que dans les opérations LSTM fusionnées.
Problèmes liés aux opérations fusionnées
La conversion d'opérations composites de TensorFlow en opérations fusionnées dans LiteRT est un problème difficile. Voici pourquoi :
Les opérations composites sont représentées dans le graphe TensorFlow sous la forme d'un ensemble d'opérations primitives sans limite bien définie. Il peut être très difficile d'identifier (par exemple, par correspondance de modèle) le sous-graphique correspondant à une telle opération composite.
Il peut exister plusieurs implémentations TensorFlow ciblant une opération LiteRT fusionnée. Par exemple, il existe de nombreuses implémentations LSTM dans TensorFlow (Keras, Babelfish/lingvo, etc.). Chacune d'elles est composée de différentes opérations primitives, mais elles peuvent toutes être converties en la même opération LSTM fusionnée dans LiteRT.
La conversion des opérations fusionnées s'est donc avérée assez difficile.
Convertir une opération composite en opération personnalisée TFLite (recommandé)
Encapsulez l'opération composite dans un tf.function.
Dans de nombreux cas, une partie du modèle peut être mappée à une seule opération dans TFLite. Cela peut aider à améliorer les performances lors de l'écriture d'une implémentation optimisée pour des opérations spécifiques. Pour pouvoir créer une opération fusionnée dans TFLite, identifiez la partie du graphique qui représente une opération fusionnée et enveloppez-la dans une tf.function avec l'attribut "experimental_implements" sur un tf.function, qui a la valeur d'attribut tfl_fusable_op avec la valeur true. Si l'opération personnalisée accepte des attributs, transmettez-les dans le même "experimental_implements".
Exemple :
def get_implements_signature():
implements_signature = [
# 'name' will be used as a name for the operation.
'name: "my_custom_fused_op"',
# attr "tfl_fusable_op" is required to be set with true value.
'attr {key: "tfl_fusable_op" value { b: true } }',
# Example attribute "example_option" that the op accepts.
'attr {key: "example_option" value { i: %d } }' % 10
]
return ' '.join(implements_signature)
@tf.function(experimental_implements=get_implements_signature())
def my_custom_fused_op(input_1, input_2):
# An empty function that represents pre/post processing example that
# is not represented as part of the Tensorflow graph.
output_1 = tf.constant(0.0, dtype=tf.float32, name='first_output')
output_2 = tf.constant(0.0, dtype=tf.float32, name='second_output')
return output_1, output_2
class TestModel(tf.Module):
def __init__(self):
super(TestModel, self).__init__()
self.conv_1 = tf.keras.layers.Conv2D(filters=1, kernel_size=(3, 3))
self.conv_2 = tf.keras.layers.Conv2D(filters=1, kernel_size=(3, 3))
@tf.function(input_signature=[
tf.TensorSpec(shape=[1, 28, 28, 3], dtype=tf.float32),
tf.TensorSpec(shape=[1, 28, 28, 3], dtype=tf.float32),
])
def simple_eval(self, input_a, input_b):
return my_custom_fused_op(self.conv_1(input_a), self.conv_2(input_b))
Notez qu'il n'est pas nécessaire de définir allow_custom_ops sur le convertisseur, car l'attribut tfl_fusable_op l'implique déjà.
Implémenter une opération personnalisée et l'enregistrer avec l'interpréteur TFLite
Implémentez votre opération fusionnée en tant qu'opération personnalisée TFLite. Pour en savoir plus, consultez les instructions.
Notez que le nom avec lequel l'opération doit être enregistrée doit être semblable à celui spécifié dans l'attribut name de la signature d'implémentation.
Voici un exemple d'op dans l'exemple :
TfLiteRegistration reg = {};
// This name must match the name specified in the implements signature.
static constexpr char kOpName[] = "my_custom_fused_op";
reg.custom_name = kOpName;
reg.prepare = [](TfLiteContext* context, TfLiteNode* node) -> TfLiteStatus {
// Add your code.
return kTfLiteOk;
};
reg.invoke = [](TfLiteContext* context, TfLiteNode* node) -> TfLiteStatus {
// Add your code.
return kTfLiteOk;
};
reg.builtin_code = kTfLiteCustom;
resolver->AddCustom(kOpName, ®);
Convertir une opération composite en opération fusionnée (Advanced)
L'architecture globale pour convertir les opérations composites TensorFlow en opérations fusionnées LiteRT est la suivante :
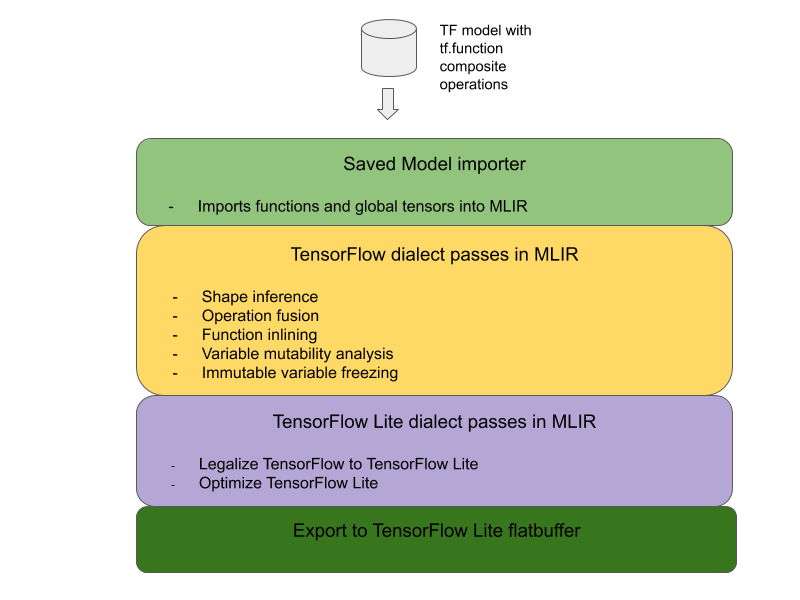
Encapsulez l'opération composite dans un tf.function.
Dans le code source du modèle TensorFlow, identifiez et abstrayez l'opération composite dans une tf.function avec l'annotation de fonction experimental_implements. Consultez un exemple de recherche d'intégration. La fonction définit l'interface et ses arguments doivent être utilisés pour implémenter la logique de conversion.
Écrire le code de conversion
Le code de conversion est écrit selon l'interface de la fonction avec l'annotation implements. Consultez un exemple de fusion pour la recherche d'embedding. Conceptuellement, le code de conversion remplace l'implémentation composite de cette interface par l'implémentation fusionnée.
Dans la passe prepare-composite-functions, insérez votre code de conversion.
Dans des cas d'utilisation plus avancés, il est possible d'implémenter des transformations complexes des opérandes de l'opération composite afin de dériver les opérandes de l'opération fusionnée. Consultez le code de conversion Keras LSTM comme exemple.
Convertir en LiteRT
Utilisez l'API TFLiteConverter.from_saved_model pour effectuer la conversion vers LiteRT.
dans le détail
Nous allons maintenant décrire les détails généraux de la conception de la conversion en opérations fusionnées dans LiteRT.
Composer des opérations dans TensorFlow
L'utilisation de tf.function avec l'attribut de fonction experimental_implements permet aux utilisateurs de composer explicitement de nouvelles opérations à l'aide d'opérations primitives TensorFlow et de spécifier l'interface que l'opération composite résultante implémente. Cela est très utile, car cela permet :
- Limite bien définie pour l'opération composite dans le graphe TensorFlow sous-jacent.
- Spécifiez explicitement l'interface implémentée par cette opération. Les arguments de tf.function correspondent à ceux de cette interface.
Prenons l'exemple d'une opération composite définie pour implémenter la recherche d'embedding. Cela correspond à une opération fusionnée dans LiteRT.
@tf.function(
experimental_implements="embedding_lookup")
def EmbFprop(embs, ids_vec):
"""Embedding forward prop.
Effectively, it computes:
num = size of ids_vec
rets = zeros([num, embedding dim])
for i in range(num):
rets[i, :] = embs[ids_vec[i], :]
return rets
Args:
embs: The embedding matrix.
ids_vec: A vector of int32 embedding ids.
Returns:
The result of embedding lookups. A matrix of shape
[num ids in ids_vec, embedding dims].
"""
num = tf.shape(ids_vec)[0]
rets = inplace_ops.empty([num] + emb_shape_suf, py_utils.FPropDtype(p))
def EmbFpropLoop(i, embs, ids_vec, rets):
# row_id = ids_vec[i]
row_id = tf.gather(ids_vec, i)
# row = embs[row_id]
row = tf.reshape(tf.gather(embs, row_id), [1] + emb_shape_suf)
# rets[i] = row
rets = inplace_ops.alias_inplace_update(rets, [i], row)
return embs, ids_vec, rets
_, _, rets = functional_ops.For(
start=0,
limit=num,
delta=1,
inputs=[embs, ids_vec, rets],
body=EmbFpropLoop,
rewrite_with_while=compiled)
if len(weight_shape) > 2:
rets = tf.reshape(rets, [num, symbolic.ToStatic(p.embedding_dim)])
return rets
En faisant en sorte que les modèles utilisent des opérations composites via tf.function, comme illustré ci-dessus, il devient possible de créer une infrastructure générale pour identifier et convertir ces opérations en opérations LiteRT fusionnées.
Étendre le convertisseur LiteRT
Le convertisseur LiteRT publié plus tôt cette année ne permettait d'importer des modèles TensorFlow que sous forme de graphique avec toutes les variables remplacées par leurs valeurs constantes correspondantes. Cela ne fonctionne pas pour la fusion d'opérations, car ces graphiques ont toutes les fonctions intégrées afin que les variables puissent être transformées en constantes.
Pour exploiter tf.function avec la fonctionnalité experimental_implements pendant le processus de conversion, les fonctions doivent être conservées jusqu'à une étape ultérieure du processus de conversion.
Par conséquent, nous avons implémenté un nouveau workflow d'importation et de conversion des modèles TensorFlow dans le convertisseur pour prendre en charge le cas d'utilisation de la fusion d'opérations composites. Voici les nouvelles fonctionnalités ajoutées :
- Importer des modèles enregistrés TensorFlow dans MLIR
- fusionner les opérations composites
- Analyse de la mutabilité des variables
- geler toutes les variables en lecture seule
Cela nous permet d'effectuer la fusion d'opérations à l'aide des fonctions représentant les opérations composites avant l'intégration de fonctions et le gel de variables.
Implémenter la fusion d'opérations
Examinons plus en détail le pass de fusion des opérations. Ce pass effectue les opérations suivantes :
- Parcourez toutes les fonctions du module MLIR.
- Si une fonction possède l'attribut tf._implements, elle appelle l'utilitaire de fusion d'opération approprié en fonction de la valeur de l'attribut.
- L'utilitaire de fusion d'opérations fonctionne sur les opérandes et les attributs de la fonction (qui servent d'interface pour la conversion), et remplace le corps de la fonction par un corps de fonction équivalent contenant l'opération fusionnée.
- Dans de nombreux cas, le corps remplacé contiendra des opérations autres que l'opération fusionnée. Elles correspondent à certaines transformations statiques sur les opérandes de la fonction afin d'obtenir les opérandes de l'opération fusionnée. Étant donné que tous ces calculs peuvent être éliminés par constante, ils ne seraient pas présents dans le FlatBuffer exporté, où seule l'opération fusionnée existerait.
Voici un extrait de code du pass qui montre le workflow principal :
void PrepareCompositeFunctionsPass::ConvertTFImplements(FuncOp func,
StringAttr attr) {
if (attr.getValue() == "embedding_lookup") {
func.eraseBody();
func.addEntryBlock();
// Convert the composite embedding_lookup function body to a
// TFLite fused embedding_lookup op.
ConvertEmbeddedLookupFunc convert_embedded_lookup(func);
if (failed(convert_embedded_lookup.VerifySignature())) {
return signalPassFailure();
}
convert_embedded_lookup.RewriteFunc();
} else if (attr.getValue() == mlir::TFL::kKerasLstm) {
func.eraseBody();
func.addEntryBlock();
OpBuilder builder(func.getBody());
if (failed(ConvertKerasLSTMLayer(func, &builder))) {
return signalPassFailure();
}
} else if (.....) /* Other fusions can plug in here */
}
Voici un extrait de code montrant comment mapper cette opération composite à une opération fusionnée dans LiteRT en utilisant la fonction comme interface de conversion.
void RewriteFunc() {
Value lookup = func_.getArgument(1);
Value value = func_.getArgument(0);
auto output_type = func_.getType().getResult(0);
OpBuilder builder(func_.getBody());
auto op = builder.create<mlir::TFL::EmbeddingLookupOp>(
func_.getLoc(), output_type, lookup, value);
builder.create<mlir::ReturnOp>(func_.getLoc(), op.getResult());
}