
LiteRT adalah framework di perangkat Google untuk deployment ML & AI generatif berperforma tinggi di platform edge.
Konversi, runtime, dan pengoptimalan yang efisien untuk machine learning di perangkat.
Dibuat berdasarkan fondasi TensorFlow Lite yang telah teruji
LiteRT bukan hanya baru, tetapi juga merupakan runtime machine learning generasi berikutnya yang paling banyak di-deploy di dunia. Layanan ini mendukung aplikasi yang Anda gunakan setiap hari, memberikan latensi rendah dan privasi tinggi di miliaran perangkat.
Dipercaya oleh aplikasi Google yang paling penting
Lebih dari 100 ribu aplikasi, miliaran pengguna global
Sorotan LiteRT

Siap Lintas Platform

Mengoptimalkan AI Generatif
Akselerasi hardware yang disederhanakan

Dukungan multi-framework
Men-deploy melalui LiteRT
Sederhanakan alur kerja deep learning Anda dari pelatihan hingga deployment di perangkat.

1.Mendapatkan model
Gunakan model terlatih .tflite atau konversi model PyTorch, JAX, atau TensorFlow ke .tflite.

2.Optimalkan
Gunakan toolkit pengoptimalan LiteRT untuk menguantisasi model Anda setelah pelatihan.

3.Jalankan
Deploy model Anda dengan LiteRT dan pilih akselerator yang optimal untuk aplikasi Anda.
Memilih Jalur Pengembangan Anda
Gunakan LiteRT untuk men-deploy AI di mana saja—mulai dari aplikasi seluler berperforma tinggi hingga perangkat IoT dengan keterbatasan resource.
Pengguna TFLite Lama
Beralih ke LiteRT untuk memanfaatkan peningkatan performa dan API terpadu di seluruh platform (Android, Desktop, Web).
BYOM : Bawa Model Anda sendiri
Memiliki model PyTorch dan ingin menerapkan pengalaman audio atau visi di perangkat.
Men-deploy Model AI Generatif
Membuat chatbot canggih di perangkat menggunakan model AI generatif dengan bobot terbuka yang dioptimalkan seperti Gemma atau model dengan bobot terbuka lainnya.
[Lanjutan] Pakar Model
Membuat model kustom atau melakukan pengoptimalan CPU/GPU/NPU khusus hardware yang mendalam untuk performa puncak.
Contoh, model, dan demo

Lihat aplikasi contoh LiteRT di GitHub
Aplikasi contoh end-to-end yang lengkap.

Lihat model genAI
Model AI Generatif siap pakai yang telah dilatih.

Lihat demo - Aplikasi Google AI Edge Gallery
Galeri yang menampilkan kasus penggunaan ML/AI Generatif di perangkat menggunakan LiteRT.
Blog dan Pengumuman
Dapatkan info terbaru tentang pengumuman, analisis teknis mendalam, dan tolok ukur performa dari tim LiteRT.

Membangun AI di perangkat dunia nyata dengan LiteRT dan NPU
Pelajari cara para pemimpin industri membangun aplikasi AI berperforma tinggi di perangkat yang siap digunakan di dunia nyata menggunakan LiteRT dan NPU.
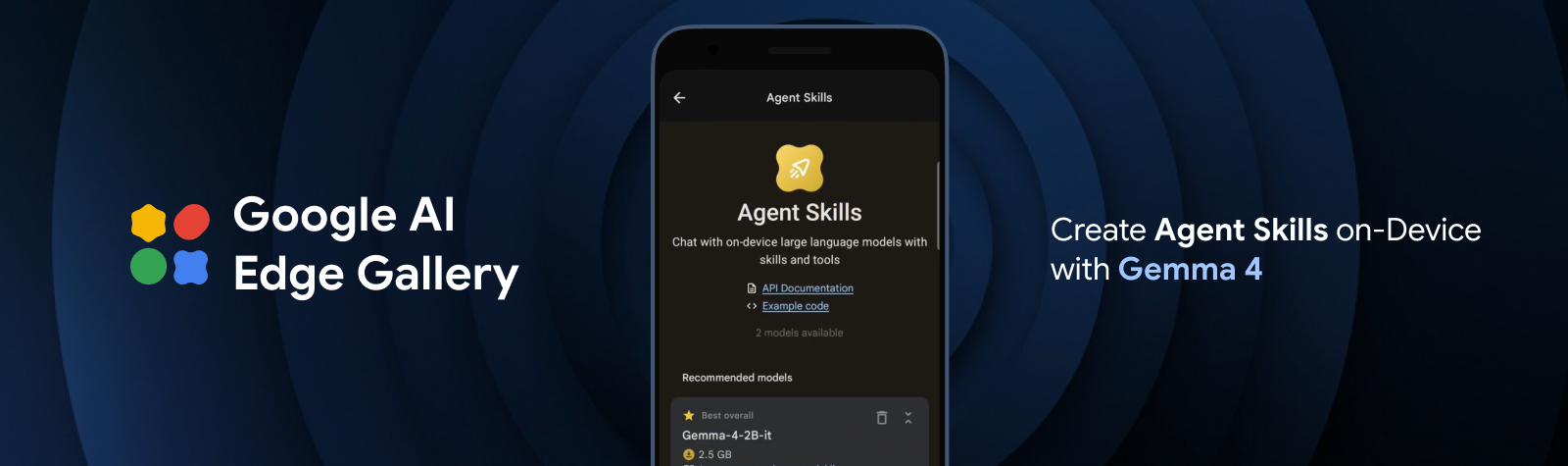
Menghadirkan kemampuan agentik canggih ke edge dengan Gemma 4
Deploy kemampuan perencanaan multi-langkah dan agentic sepenuhnya di perangkat dengan keluarga Gemma 4 dan LiteRT yang baru.

LiteRT: Framework universal untuk AI di perangkat
Framework ML di perangkat terpadu Google, yang berkembang dari TFLite untuk deployment berperforma tinggi.
NPU MediaTek dan LiteRT: Mendukung AI di perangkat generasi berikutnya
Memperluas dukungan akselerasi NPU ke chipset MediaTek untuk AI berefisiensi tinggi.
Mewujudkan Performa Puncak di NPU Qualcomm dengan LiteRT
Mendapatkan performa terobosan untuk AI generatif di Unit Pemrosesan Neural Qualcomm.

LiteRT: Performa Maksimal, Lebih Sederhana
Memperkenalkan CompiledModel API untuk pemilihan hardware otomatis dan eksekusi asinkron.
GenAI di perangkat di Chrome, Chromebook Plus, dan Pixel Watch dengan LiteRT-LM
Men-deploy model bahasa di platform berbasis browser dan perangkat wearable menggunakan LiteRT-LM.

Model bahasa kecil, multi-modalitas, dan pemanggilan fungsi Google AI Edge
Insight terbaru tentang RAG, multimodalitas, dan panggilan fungsi untuk model bahasa edge
Bergabung dengan Komunitas
Komunitas GitHub LiteRT
Berkontribusi langsung pada project dan berkolaborasi dengan developer inti.

Hub Hugging Face
Akses model open-weight yang dioptimalkan di Hugging Face Hub.