
Les métadonnées LiteRT fournissent une norme pour les descriptions de modèles. Les métadonnées sont une source importante d'informations sur ce que fait le modèle et sur ses informations d'entrée / sortie. Les métadonnées se composent à la fois
- des parties lisibles par l'homme qui présentent les bonnes pratiques à suivre lors de l'utilisation du modèle ;
- des parties lisibles par machine qui peuvent être exploitées par des générateurs de code, tels que le générateur de code Android LiteRT et la fonctionnalité de liaison ML Android Studio.
Tous les modèles d'images publiés sur Kaggle Models ont été renseignés avec des métadonnées.
Format de modèle avec métadonnées
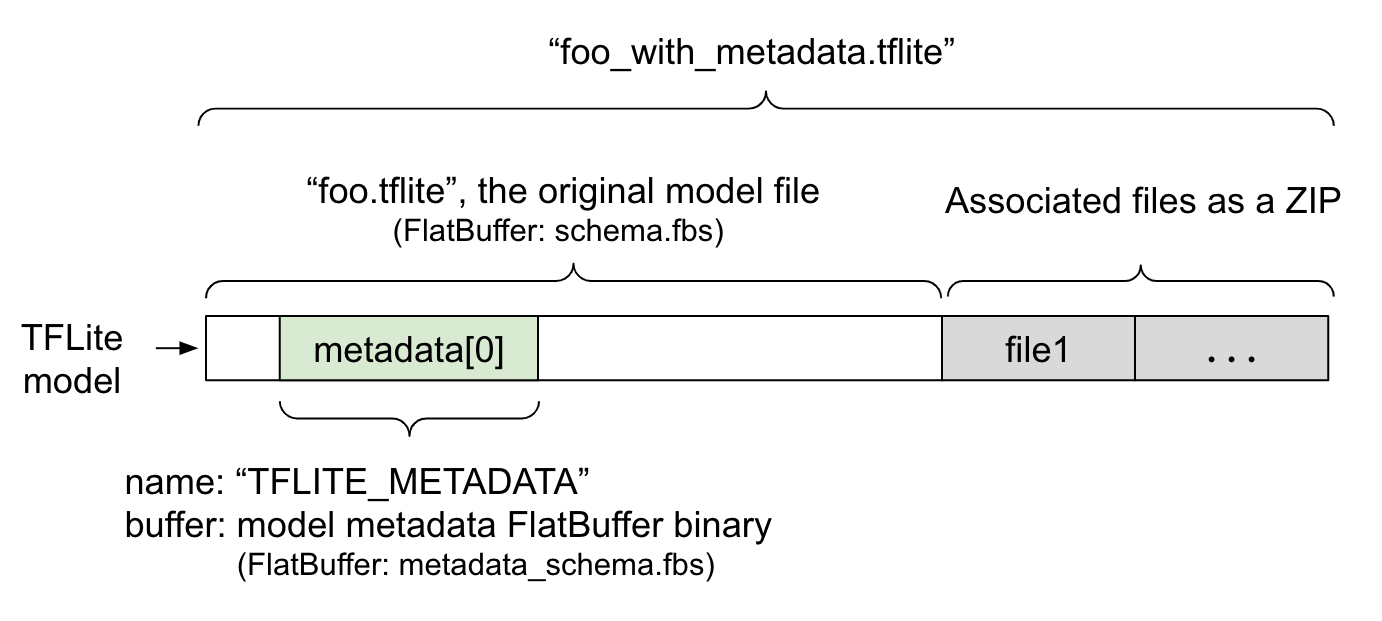
Les métadonnées du modèle sont définies dans metadata_schema.fbs, un fichier FlatBuffer. Comme le montre la figure 1, il est stocké dans le champ metadata du schéma de modèle TFLite, sous le nom "TFLITE_METADATA". Certains modèles peuvent être associés à des fichiers, tels que des fichiers de libellés de classification.
Ces fichiers sont concaténés à la fin du fichier de modèle d'origine en tant que ZIP à l'aide du mode "append" de ZipFile (mode 'a'). L'interpréteur TFLite peut consommer le nouveau format de fichier de la même manière qu'auparavant. Pour en savoir plus, consultez Empaqueter les fichiers associés.
Consultez les instructions ci-dessous pour savoir comment remplir, visualiser et lire les métadonnées.
Configurer les outils de métadonnées
Avant d'ajouter des métadonnées à votre modèle, vous devez configurer un environnement de programmation Python pour exécuter TensorFlow. Pour obtenir un guide détaillé sur la configuration, cliquez ici.
Après avoir configuré l'environnement de programmation Python, vous devrez installer des outils supplémentaires :
pip install tflite-support
L'outil de métadonnées LiteRT est compatible avec Python 3.
Ajouter des métadonnées à l'aide de l'API Python Flatbuffers
Les métadonnées du modèle dans le schéma se composent de trois parties :
- Informations sur le modèle : description générale du modèle et éléments tels que les conditions de licence. Consultez ModelMetadata. 2. Informations d'entrée : description des entrées et du prétraitement requis, comme la normalisation. Consultez SubGraphMetadata.input_tensor_metadata. 3. Informations sur la sortie : description de la sortie et du post-traitement requis, comme le mappage aux libellés. Consultez SubGraphMetadata.output_tensor_metadata.
Étant donné que LiteRT ne prend en charge qu'un seul sous-graphe pour le moment, le générateur de code LiteRT et la fonctionnalité de liaison ML Android Studio utiliseront ModelMetadata.name et ModelMetadata.description au lieu de SubGraphMetadata.name et SubGraphMetadata.description lors de l'affichage des métadonnées et de la génération de code.
Types d'entrée / sortie acceptés
Les métadonnées LiteRT pour les entrées et les sorties ne sont pas conçues pour des types de modèles spécifiques, mais plutôt pour des types d'entrées et de sorties. La fonction du modèle n'a pas d'importance. Tant que les types d'entrée et de sortie sont les suivants ou une combinaison des suivants, ils sont compatibles avec les métadonnées TensorFlow Lite :
- Caractéristique : nombres entiers non signés ou float32.
- Image : les métadonnées sont actuellement compatibles avec les images RVB et en niveaux de gris.
- Cadre de délimitation : cadres de délimitation de forme rectangulaire. Le schéma est compatible avec différents systèmes de numérotation.
Empaqueter les fichiers associés
Les modèles LiteRT peuvent être associés à différents fichiers. Par exemple, les modèles de langage naturel disposent généralement de fichiers de vocabulaire qui mappent les fragments de mots aux ID de mots. Les modèles de classification peuvent avoir des fichiers de libellés qui indiquent les catégories d'objets. Sans les fichiers associés (le cas échéant), un modèle ne fonctionnera pas correctement.
Les fichiers associés peuvent désormais être regroupés avec le modèle à l'aide de la bibliothèque Python de métadonnées. Le nouveau modèle LiteRT devient un fichier ZIP contenant à la fois le modèle et les fichiers associés. Il peut être décompressé avec des outils de compression courants. Ce nouveau format de modèle continue d'utiliser la même extension de fichier, .tflite. Il est compatible avec le framework et l'interpréteur TFLite existants. Pour en savoir plus, consultez Empaqueter les métadonnées et les fichiers associés dans le modèle.
Les informations sur les fichiers associés peuvent être enregistrées dans les métadonnées. Selon le type de fichier et l'emplacement auquel il est associé (ModelMetadata, SubGraphMetadata et TensorMetadata, par exemple), le générateur de code LiteRT pour Android peut appliquer automatiquement le pré-traitement et le post-traitement correspondants à l'objet. Pour en savoir plus, consultez la section <Codegen usage> (Utilisation de Codegen) de chaque type de fichier associé dans le schéma.
Paramètres de normalisation et de quantification
La normalisation est une technique courante de prétraitement des données dans le machine learning. L'objectif de la normalisation est de modifier les valeurs pour les ramener à une échelle commune, sans déformer les différences dans les plages de valeurs.
La quantification de modèle est une technique qui permet de réduire la précision des représentations des pondérations et, éventuellement, des activations pour le stockage et le calcul.
En termes de prétraitement et de post-traitement, la normalisation et la quantification sont deux étapes indépendantes. Voici les informations détaillées relatives à cet incident.
| Normalization | Quantification | |
|---|---|---|
Exemple de valeurs de paramètres de l'image d'entrée dans MobileNet pour les modèles float et quant, respectivement. |
Modèle float : - mean: 127.5 - std: 127.5 Modèle quant : - mean: 127.5 - std: 127.5 |
Modèle float : - zeroPoint: 0 - scale: 1.0 Modèle quant : - zeroPoint: 128.0 - scale:0.0078125f |
Quand l'invoquer ? |
Entrées : si les données d'entrée sont normalisées lors de l'entraînement, les données d'entrée de l'inférence doivent être normalisées en conséquence. Sorties : les données de sortie ne seront généralement pas normalisées. |
Les modèles flottants n'ont pas besoin de quantification. Un modèle quantifié peut avoir besoin ou non d'une quantification lors du prétraitement ou du post-traitement. Cela dépend du type de données des Tensors d'entrée/sortie. - Tensors float : aucune quantification n'est nécessaire lors du prétraitement/post-traitement. Les opérations de quantification et de déquantification sont intégrées au graphique du modèle. - Les Tensors int8/uint8 : nécessitent une quantification dans le pré/post-traitement. |
Formule |
normalized_input = (input - mean) / std |
Quantifier pour les entrées :
q = f / scale + zeroPoint Déquantifier pour les sorties : f = (q - zeroPoint) * scale |
Où se trouvent les paramètres ? |
Rempli par le créateur du modèle et stocké dans les métadonnées du modèle, sous la forme NormalizationOptions |
Rempli automatiquement par le convertisseur TFLite et stocké dans le fichier du modèle TFLite. |
| Comment obtenir les paramètres ? | Via l'API MetadataExtractor [2]
|
Via l'API TFLite Tensor [1] ou l'API MetadataExtractor [2] |
| Les modèles float et quant partagent-ils la même valeur ? | Oui, les modèles float et quant ont les mêmes paramètres de normalisation. | Non, le modèle float n'a pas besoin de quantification. |
| Le générateur de code TFLite ou la liaison ML Android Studio le génèrent-ils automatiquement lors du traitement des données ? | Oui |
Oui |
[1] L'API LiteRT Java et l'API LiteRT C++.
[2] La bibliothèque d'extraction des métadonnées
Lors du traitement des données d'image pour les modèles uint8, la normalisation et la quantification sont parfois ignorées. Vous pouvez le faire lorsque les valeurs de pixels sont comprises dans la plage [0, 255]. Toutefois, en général, vous devez toujours traiter les données en fonction des paramètres de normalisation et de quantification, le cas échéant.
Exemples
Vous trouverez des exemples de la façon dont les métadonnées doivent être renseignées pour différents types de modèles ici :
Classification d'images
Téléchargez le script qui remplit les métadonnées de mobilenet_v1_0.75_160_quantized.tflite. Exécutez le script comme suit :
python ./metadata_writer_for_image_classifier.py \
--model_file=./model_without_metadata/mobilenet_v1_0.75_160_quantized.tflite \
--label_file=./model_without_metadata/labels.txt \
--export_directory=model_with_metadata
Pour remplir les métadonnées d'autres modèles de classification d'images, ajoutez les spécifications du modèle, comme celles-ci, au script. Le reste de ce guide mettra en évidence certaines des sections clés de l'exemple de classification d'images pour illustrer les éléments clés.
Présentation détaillée de l'exemple de classification d'images
Informations relatives au modèle
Les métadonnées commencent par la création d'informations sur le modèle :
from tflite_support import flatbuffers
from tflite_support import metadata as _metadata
from tflite_support import metadata_schema_py_generated as _metadata_fb
""" ... """
"""Creates the metadata for an image classifier."""
# Creates model info.
model_meta = _metadata_fb.ModelMetadataT()
model_meta.name = "MobileNetV1 image classifier"
model_meta.description = ("Identify the most prominent object in the "
"image from a set of 1,001 categories such as "
"trees, animals, food, vehicles, person etc.")
model_meta.version = "v1"
model_meta.author = "TensorFlow"
model_meta.license = ("Apache License. Version 2.0 "
"http://www.apache.org/licenses/LICENSE-2.0.")
Informations sur les entrées / sorties
Cette section vous explique comment décrire la signature d'entrée et de sortie de votre modèle. Ces métadonnées peuvent être utilisées par des générateurs de code automatiques pour créer du code de pré-traitement et de post-traitement. Pour créer des informations d'entrée ou de sortie sur un Tensor :
# Creates input info.
input_meta = _metadata_fb.TensorMetadataT()
# Creates output info.
output_meta = _metadata_fb.TensorMetadataT()
Image d'entrée
Les images sont un type d'entrée courant pour le machine learning. Les métadonnées LiteRT sont compatibles avec des informations telles que l'espace colorimétrique et les informations de prétraitement telles que la normalisation. La dimension de l'image ne nécessite pas de spécification manuelle, car elle est déjà fournie par la forme du Tensor d'entrée et peut être déduite automatiquement.
input_meta.name = "image"
input_meta.description = (
"Input image to be classified. The expected image is {0} x {1}, with "
"three channels (red, blue, and green) per pixel. Each value in the "
"tensor is a single byte between 0 and 255.".format(160, 160))
input_meta.content = _metadata_fb.ContentT()
input_meta.content.contentProperties = _metadata_fb.ImagePropertiesT()
input_meta.content.contentProperties.colorSpace = (
_metadata_fb.ColorSpaceType.RGB)
input_meta.content.contentPropertiesType = (
_metadata_fb.ContentProperties.ImageProperties)
input_normalization = _metadata_fb.ProcessUnitT()
input_normalization.optionsType = (
_metadata_fb.ProcessUnitOptions.NormalizationOptions)
input_normalization.options = _metadata_fb.NormalizationOptionsT()
input_normalization.options.mean = [127.5]
input_normalization.options.std = [127.5]
input_meta.processUnits = [input_normalization]
input_stats = _metadata_fb.StatsT()
input_stats.max = [255]
input_stats.min = [0]
input_meta.stats = input_stats
Sortie des libellés
Le libellé peut être mappé à un Tensor de sortie via un fichier associé à l'aide de TENSOR_AXIS_LABELS.
# Creates output info.
output_meta = _metadata_fb.TensorMetadataT()
output_meta.name = "probability"
output_meta.description = "Probabilities of the 1001 labels respectively."
output_meta.content = _metadata_fb.ContentT()
output_meta.content.content_properties = _metadata_fb.FeaturePropertiesT()
output_meta.content.contentPropertiesType = (
_metadata_fb.ContentProperties.FeatureProperties)
output_stats = _metadata_fb.StatsT()
output_stats.max = [1.0]
output_stats.min = [0.0]
output_meta.stats = output_stats
label_file = _metadata_fb.AssociatedFileT()
label_file.name = os.path.basename("your_path_to_label_file")
label_file.description = "Labels for objects that the model can recognize."
label_file.type = _metadata_fb.AssociatedFileType.TENSOR_AXIS_LABELS
output_meta.associatedFiles = [label_file]
Créer les Flatbuffers de métadonnées
Le code suivant combine les informations sur le modèle avec les informations d'entrée et de sortie :
# Creates subgraph info.
subgraph = _metadata_fb.SubGraphMetadataT()
subgraph.inputTensorMetadata = [input_meta]
subgraph.outputTensorMetadata = [output_meta]
model_meta.subgraphMetadata = [subgraph]
b = flatbuffers.Builder(0)
b.Finish(
model_meta.Pack(b),
_metadata.MetadataPopulator.METADATA_FILE_IDENTIFIER)
metadata_buf = b.Output()
Empaqueter les métadonnées et les fichiers associés dans le modèle
Une fois les Flatbuffers de métadonnées créés, les métadonnées et le fichier de libellés sont écrits dans le fichier TFLite via la méthode populate :
populator = _metadata.MetadataPopulator.with_model_file(model_file)
populator.load_metadata_buffer(metadata_buf)
populator.load_associated_files(["your_path_to_label_file"])
populator.populate()
Vous pouvez inclure autant de fichiers associés que vous le souhaitez dans le modèle via load_associated_files. Toutefois, vous devez inclure au moins les fichiers documentés dans les métadonnées. Dans cet exemple, l'empaquetage du fichier de libellés est obligatoire.
Visualiser les métadonnées
Vous pouvez utiliser Netron pour visualiser vos métadonnées, ou lire les métadonnées d'un modèle LiteRT au format JSON à l'aide de MetadataDisplayer :
displayer = _metadata.MetadataDisplayer.with_model_file(export_model_path)
export_json_file = os.path.join(FLAGS.export_directory,
os.path.splitext(model_basename)[0] + ".json")
json_file = displayer.get_metadata_json()
# Optional: write out the metadata as a json file
with open(export_json_file, "w") as f:
f.write(json_file)
Android Studio permet également d'afficher les métadonnées grâce à la fonctionnalité de liaison ML Android Studio.
Gestion des versions des métadonnées
Le schéma de métadonnées est versionné à la fois par le numéro de gestion sémantique des versions, qui suit les modifications du fichier de schéma, et par l'identification du fichier Flatbuffers, qui indique la véritable compatibilité des versions.
Numéro de version sémantique
Le schéma de métadonnées est versionné par le numéro de version sémantique, tel que MAJEURE.MINEURE.CORRECTIF. Il suit les modifications du schéma conformément aux règles ici.
Consultez l'historique des champs ajoutés après la version 1.0.0.
Identification du fichier Flatbuffers
La gestion sémantique des versions garantit la compatibilité si les règles sont respectées, mais n'implique pas une véritable incompatibilité. Lorsque vous augmentez le numéro MAJEUR, cela ne signifie pas nécessairement que la compatibilité avec les versions antérieures est rompue. Par conséquent, nous utilisons l'identification du fichier Flatbuffers, file_identifier, pour indiquer la véritable compatibilité du schéma de métadonnées. L'identifiant de fichier comporte exactement quatre caractères. Il est associé à un schéma de métadonnées spécifique et les utilisateurs ne peuvent pas le modifier. Si la rétrocompatibilité du schéma de métadonnées doit être rompue pour une raison quelconque, le file_identifier sera incrémenté (par exemple, de "M001" à "M002"). Le file_identifier devrait être modifié beaucoup moins souvent que metadata_version.
Version minimale requise de l'analyseur de métadonnées
La version minimale requise de l'analyseur de métadonnées correspond à la version minimale de l'analyseur de métadonnées (code généré par Flatbuffers) qui peut lire entièrement les métadonnées Flatbuffers. La version correspond en fait au plus grand numéro de version parmi les versions de tous les champs renseignés et à la plus petite version compatible indiquée par l'identifiant de fichier. La version minimale requise de l'analyseur de métadonnées est automatiquement renseignée par MetadataPopulator lorsque les métadonnées sont renseignées dans un modèle TFLite. Pour en savoir plus sur l'utilisation de la version minimale requise de l'analyseur de métadonnées, consultez l'extracteur de métadonnées.
Lire les métadonnées des modèles
La bibliothèque Metadata Extractor est un outil pratique pour lire les métadonnées et les fichiers associés à partir de modèles sur différentes plates-formes (voir la version Java et la version C++). Vous pouvez créer votre propre outil d'extraction de métadonnées dans d'autres langues à l'aide de la bibliothèque Flatbuffers.
Lire les métadonnées en Java
Pour utiliser la bibliothèque Metadata Extractor dans votre application Android, nous vous recommandons d'utiliser le fichier AAR LiteRT Metadata hébergé sur MavenCentral.
Il contient la classe MetadataExtractor, ainsi que les liaisons Java FlatBuffers pour le schéma de métadonnées et le schéma de modèle.
Vous pouvez le spécifier dans vos dépendances build.gradle comme suit :
dependencies {
implementation 'org.tensorflow:tensorflow-lite-metadata:0.1.0'
}
Pour utiliser les instantanés nocturnes, assurez-vous d'avoir ajouté le dépôt d'instantanés Sonatype.
Vous pouvez initialiser un objet MetadataExtractor avec un ByteBuffer qui pointe vers le modèle :
public MetadataExtractor(ByteBuffer buffer);
Le ByteBuffer doit rester inchangé pendant toute la durée de vie de l'objet MetadataExtractor. L'initialisation peut échouer si l'identifiant du fichier Flatbuffers des métadonnées du modèle ne correspond pas à celui de l'analyseur de métadonnées. Pour en savoir plus, consultez la section Gestion des versions des métadonnées.
Grâce aux identifiants de fichier correspondants, l'extracteur de métadonnées pourra lire les métadonnées générées à partir de tous les schémas passés et futurs grâce au mécanisme de compatibilité ascendante et descendante de Flatbuffers. Toutefois, les champs des futurs schémas ne peuvent pas être extraits par les anciens extracteurs de métadonnées. La version minimale requise de l'analyseur des métadonnées indique la version minimale de l'analyseur de métadonnées qui peut lire l'intégralité des Flatbuffers de métadonnées. Vous pouvez utiliser la méthode suivante pour vérifier si la condition de version minimale requise de l'analyseur est remplie :
public final boolean isMinimumParserVersionSatisfied();
Il est possible de transmettre un modèle sans métadonnées. Toutefois, l'appel de méthodes qui lisent les métadonnées entraînera des erreurs d'exécution. Vous pouvez vérifier si un modèle comporte des métadonnées en appelant la méthode hasMetadata :
public boolean hasMetadata();
MetadataExtractor fournit des fonctions pratiques pour obtenir les métadonnées des Tensors d'entrée/sortie. Par exemple,
public int getInputTensorCount();
public TensorMetadata getInputTensorMetadata(int inputIndex);
public QuantizationParams getInputTensorQuantizationParams(int inputIndex);
public int[] getInputTensorShape(int inputIndex);
public int getoutputTensorCount();
public TensorMetadata getoutputTensorMetadata(int inputIndex);
public QuantizationParams getoutputTensorQuantizationParams(int inputIndex);
public int[] getoutputTensorShape(int inputIndex);
Bien que le schéma du modèle LiteRT soit compatible avec plusieurs sous-graphiques, l'interpréteur TFLite n'en accepte actuellement qu'un seul. Par conséquent, MetadataExtractor omet l'index du sous-graphe en tant qu'argument d'entrée dans ses méthodes.
Lire les fichiers associés à partir des modèles
Le modèle LiteRT avec métadonnées et fichiers associés est essentiellement un fichier ZIP qui peut être décompressé avec des outils ZIP courants pour obtenir les fichiers associés. Par exemple, vous pouvez décompresser mobilenet_v1_0.75_160_quantized et extraire le fichier de libellé dans le modèle comme suit :
$ unzip mobilenet_v1_0.75_160_quantized_1_metadata_1.tflite
Archive: mobilenet_v1_0.75_160_quantized_1_metadata_1.tflite
extracting: labels.txt
Vous pouvez également lire les fichiers associés à l'aide de la bibliothèque Metadata Extractor.
En Java, transmettez le nom du fichier à la méthode MetadataExtractor.getAssociatedFile :
public InputStream getAssociatedFile(String fileName);
De même, en C++, cela peut être fait avec la méthode ModelMetadataExtractor::GetAssociatedFile :
tflite::support::StatusOr<absl::string_view> GetAssociatedFile(
const std::string& filename) const;