
Edge devices often have limited memory or computational power. Various optimizations can be applied to models so that they can be run within these constraints. In addition, some optimizations allow the use of specialized hardware for accelerated inference.
LiteRT and the TensorFlow Model Optimization Toolkit provide tools to minimize the complexity of optimizing inference.
It's recommended that you consider model optimization during your application development process. This document outlines some best practices for optimizing TensorFlow models for deployment to edge hardware.
Why models should be optimized
There are several main ways model optimization can help with application development.
Size reduction
Some forms of optimization can be used to reduce the size of a model. Smaller models have the following benefits:
- Smaller storage size: Smaller models occupy less storage space on your users' devices. For example, an Android app using a smaller model will take up less storage space on a user's mobile device.
- Smaller download size: Smaller models require less time and bandwidth to download to users' devices.
- Less memory usage: Smaller models use less RAM when they are run, which frees up memory for other parts of your application to use, and can translate to better performance and stability.
Quantization can reduce the size of a model in all of these cases, potentially at the expense of some accuracy. Pruning and clustering can reduce the size of a model for download by making it more easily compressible.
Latency reduction
Latency is the amount of time it takes to run a single inference with a given model. Some forms of optimization can reduce the amount of computation required to run inference using a model, resulting in lower latency. Latency can also have an impact on power consumption.
Currently, quantization can be used to reduce latency by simplifying the calculations that occur during inference, potentially at the expense of some accuracy.
Accelerator compatibility
Some hardware accelerators, such as the Edge TPU, can run inference extremely fast with models that have been correctly optimized.
Generally, these types of devices require models to be quantized in a specific way. See each hardware accelerator's documentation to learn more about their requirements.
Trade-offs
Optimizations can potentially result in changes in model accuracy, which must be considered during the application development process.
The accuracy changes depend on the individual model being optimized, and are difficult to predict ahead of time. Generally, models that are optimized for size or latency will lose a small amount of accuracy. Depending on your application, this may or may not impact your users' experience. In rare cases, certain models may gain some accuracy as a result of the optimization process.
Types of optimization
LiteRT currently supports optimization via quantization, pruning and clustering.
These are part of the TensorFlow Model Optimization Toolkit, which provides resources for model optimization techniques that are compatible with TensorFlow Lite.
Quantization
Quantization works by reducing the precision of the numbers used to represent a model's parameters, which by default are 32-bit floating point numbers. This results in a smaller model size and faster computation.
The following types of quantization are available in LiteRT:
| Technique | Data requirements | Size reduction | Accuracy | Supported hardware |
|---|---|---|---|---|
| Post-training float16 quantization | No data | Up to 50% | Insignificant accuracy loss | CPU, GPU |
| Post-training dynamic range quantization | No data | Up to 75% | Smallest accuracy loss | CPU, GPU (Android) |
| Post-training integer quantization | Unlabelled representative sample | Up to 75% | Small accuracy loss | CPU, GPU (Android), EdgeTPU |
| Quantization-aware training | Labelled training data | Up to 75% | Smallest accuracy loss | CPU, GPU (Android), EdgeTPU |
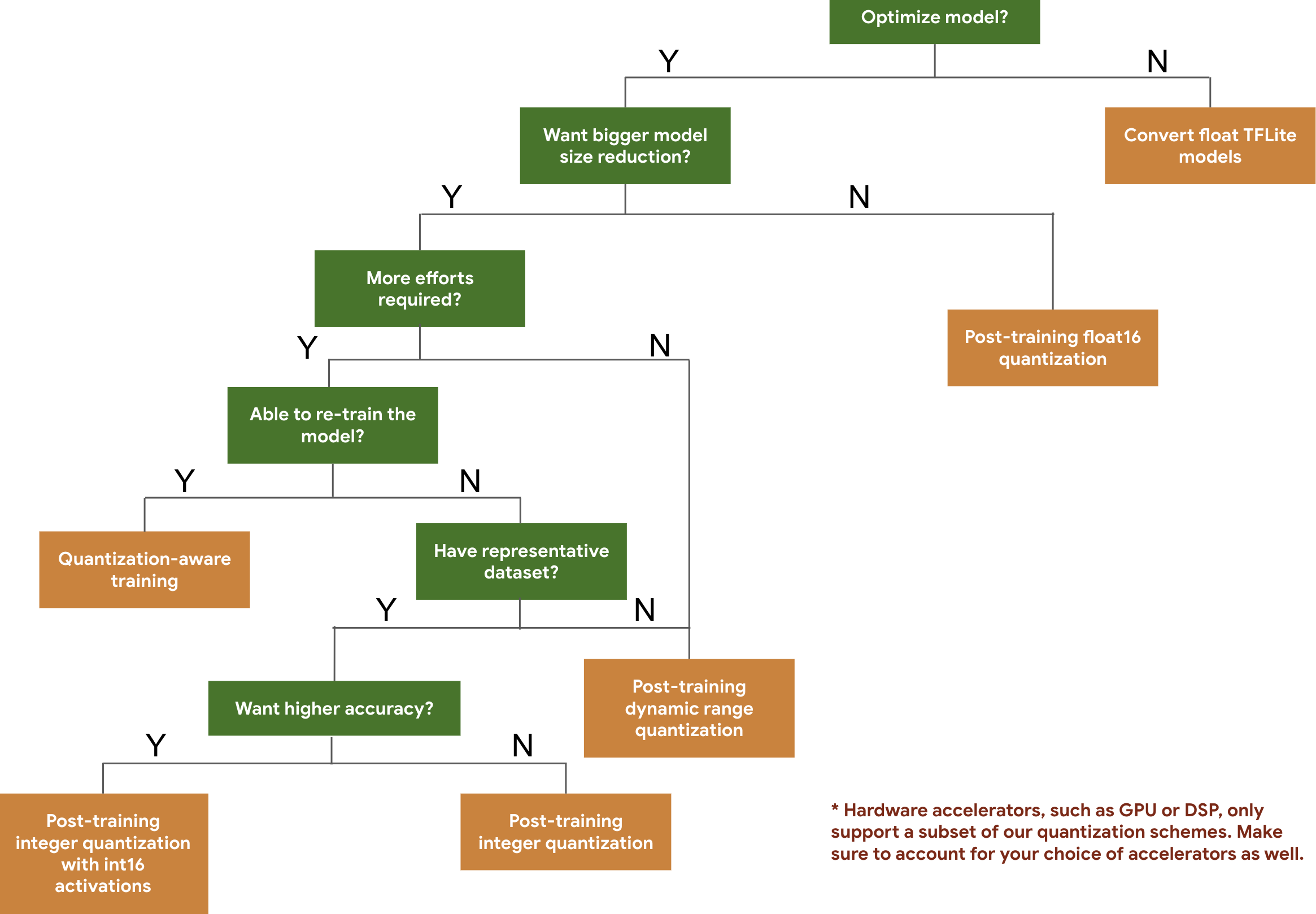
The following decision tree helps you select the quantization schemes you might want to use for your model, simply based on the expected model size and accuracy.
Below are the latency and accuracy results for post-training quantization and quantization-aware training on a few models. All latency numbers are measured on Pixel 2 devices using a single big core CPU. As the toolkit improves, so will the numbers here:
| Model | Top-1 Accuracy (Original) | Top-1 Accuracy (Post Training Quantized) | Top-1 Accuracy (Quantization Aware Training) | Latency (Original) (ms) | Latency (Post Training Quantized) (ms) | Latency (Quantization Aware Training) (ms) | Size (Original) (MB) | Size (Optimized) (MB) |
|---|---|---|---|---|---|---|---|---|
| Mobilenet-v1-1-224 | 0.709 | 0.657 | 0.70 | 124 | 112 | 64 | 16.9 | 4.3 |
| Mobilenet-v2-1-224 | 0.719 | 0.637 | 0.709 | 89 | 98 | 54 | 14 | 3.6 |
| Inception_v3 | 0.78 | 0.772 | 0.775 | 1130 | 845 | 543 | 95.7 | 23.9 |
| Resnet_v2_101 | 0.770 | 0.768 | N/A | 3973 | 2868 | N/A | 178.3 | 44.9 |
Full integer quantization with int16 activations and int8 weights
Quantization with int16 activations is a full integer quantization scheme with activations in int16 and weights in int8. This mode can improve accuracy of the quantized model in comparison to the full integer quantization scheme with both activations and weights in int8 keeping a similar model size. It is recommended when activations are sensitive to the quantization.
NOTE: Currently only non-optimized reference kernel implementations are available in TFLite for this quantization scheme, so by default the performance will be slow compared to int8 kernels. Full advantages of this mode can currently be accessed via specialised hardware, or custom software.
Below are the accuracy results for some models that benefit from this mode.
Model
Accuracy metric type
Accuracy (float32 activations)
Accuracy (int8 activations)
Accuracy (int16 activations)
Wav2letter WER 6.7% 7.7%
7.2% DeepSpeech 0.5.1 (unrolled) CER 6.13% 43.67%
6.52% YoloV3 mAP(IOU=0.5) 0.577 0.563
0.574 MobileNetV1 Top-1 Accuracy 0.7062 0.694
0.6936 MobileNetV2 Top-1 Accuracy 0.718 0.7126
0.7137 MobileBert F1(Exact match) 88.81(81.23) 2.08(0)
88.73(81.15)
Pruning
Pruning works by removing parameters within a model that have only a minor impact on its predictions. Pruned models are the same size on disk, and have the same runtime latency, but can be compressed more effectively. This makes pruning a useful technique for reducing model download size.
In the future, LiteRT will provide latency reduction for pruned models.
Clustering
Clustering works by grouping the weights of each layer in a model into a predefined number of clusters, then sharing the centroid values for the weights belonging to each individual cluster. This reduces the number of unique weight values in a model, thus reducing its complexity.
As a result, clustered models can be compressed more effectively, providing deployment benefits similar to pruning.
Development workflow
As a starting point, check if the models in hosted models can work for your application. If not, we recommend that users start with the post-training quantization tool since this is broadly applicable and does not require training data.
For cases where the accuracy and latency targets are not met, or hardware accelerator support is important, quantization-aware training is the better option. See additional optimization techniques under the TensorFlow Model Optimization Toolkit.
If you want to further reduce your model size, you can try pruning and/or clustering prior to quantizing your models.