
模型中使用的機器學習 (ML) 運算子可能會影響將 TensorFlow 模型轉換為 LiteRT 格式的程序。LiteRT 轉換工具支援常見推論模型中使用的有限 TensorFlow 作業,因此並非所有模型都能直接轉換。轉換器工具可讓您加入其他運算子,但以這種方式轉換模型時,您也必須修改用於執行模型的 LiteRT 執行階段環境,這可能會限制您使用標準執行階段部署選項 (例如 Google Play 服務) 的能力。
LiteRT 轉換工具會分析模型結構並套用最佳化設定,使其與直接支援的運算子相容。舉例來說,視模型中的機器學習運算子而定,轉換器可能會省略或合併這些運算子,以便對應至 LiteRT 對應項目。
即使是支援的作業,有時也會基於效能考量,要求使用特定模式。如要瞭解如何建構可搭配 LiteRT 使用的 TensorFlow 模型,最好的方法是仔細考量運算作業的轉換和最佳化方式,以及這個程序帶來的限制。
支援的運算子
LiteRT 內建運算子是 TensorFlow 核心程式庫運算子的子集。TensorFlow 模型也可能包含自訂運算子,例如複合運算子或您定義的新運算子。下圖顯示這些運算子之間的關係。
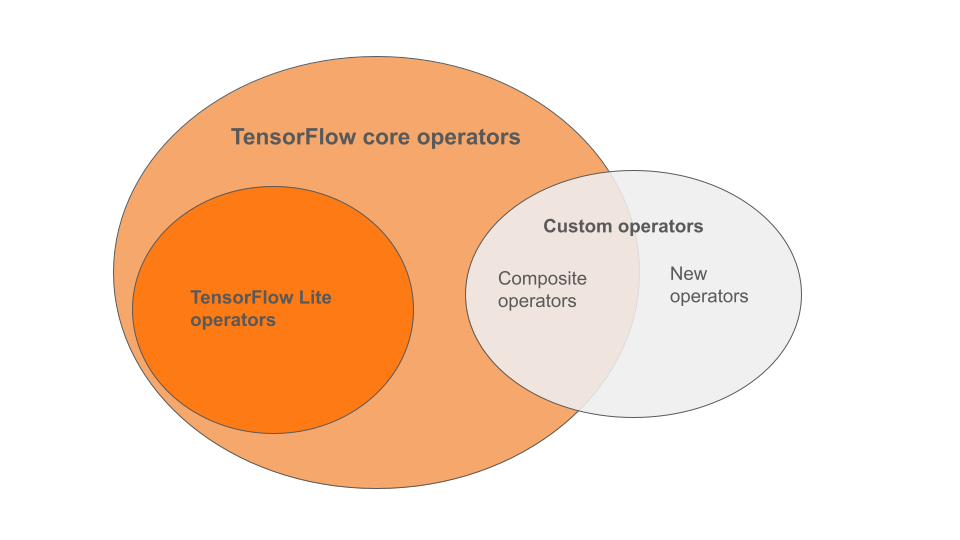
在這個機器學習模型運算子範圍中,轉換程序支援 3 種模型:
- 模型僅包含 LiteRT 內建運算子。(建議)
- 模型包含內建運算子和選取的 TensorFlow 核心運算子。
- 模型包含內建運算子、TensorFlow 核心運算子和/或自訂運算子。
如果模型只包含 LiteRT 原生支援的作業,您不需要任何額外標記即可轉換模型。建議採用這種做法,因為這類模型可順利轉換,而且使用預設的 LiteRT 執行階段,即可輕鬆進行最佳化及執行。此外,您也可以選擇更多模型部署選項,例如 Google Play 服務。您可以參閱 LiteRT 轉換器指南,瞭解如何開始使用。如需內建運算子清單,請參閱 LiteRT Ops 頁面。
如需納入核心程式庫中的特定 TensorFlow 運算,您必須在轉換時指定,並確保執行階段包含這些運算。如需詳細步驟,請參閱「選取 TensorFlow 運算子」主題。
盡可能避免在轉換後的模型中加入自訂運算子。自訂運算子:可透過合併多個原始 TensorFlow 核心運算子建立,或完全重新定義。轉換自訂運算子時,可能會產生內建 LiteRT 程式庫以外的依附元件,進而增加整體模型的大小。如果自訂作業並非專為行動裝置或裝置部署作業建立,與伺服器環境相比,部署至資源受限的裝置時,效能可能會較差。最後,與納入特定 TensorFlow 核心運算子相同,自訂運算子也需要修改模型執行階段環境,因此您無法使用標準執行階段服務,例如 Google Play 服務。
支援的類型
大多數 LiteRT 作業的目標都是浮點 (float32) 和量化 (uint8、int8) 推論,但許多作業尚未支援其他類型,例如 tf.float16 和字串。
除了使用不同版本的作業外,浮點模型和量化模型之間的另一個差異在於轉換方式。量化轉換需要張量的動態範圍資訊。這需要在模型訓練期間進行「偽量化」、透過校正資料集取得範圍資訊,或進行「即時」範圍估算。詳情請參閱量化。
直接轉換、常數摺疊和融合
即使沒有直接對應的作業,LiteRT 仍可處理許多 TensorFlow 作業。如果作業可從圖表中簡單移除 (tf.identity)、由張量取代 (tf.placeholder),或合併為更複雜的作業 (tf.nn.bias_add),就會發生這種情況。即使是支援的作業,有時也可能會透過其中一個程序移除。
以下列舉一些通常會從圖表中移除的 TensorFlow 運算:
tf.addtf.debugging.check_numericstf.constanttf.divtf.dividetf.fake_quant_with_min_max_argstf.fake_quant_with_min_max_varstf.identitytf.maximumtf.minimumtf.multiplytf.no_optf.placeholdertf.placeholder_with_defaulttf.realdivtf.reduce_maxtf.reduce_mintf.reduce_sumtf.rsqrttf.shapetf.sqrttf.squaretf.subtracttf.tiletf.nn.batch_norm_with_global_normalizationtf.nn.bias_addtf.nn.fused_batch_normtf.nn.relutf.nn.relu6
實驗作業
下列 LiteRT 作業存在,但尚未準備好用於自訂模型:
CALLCONCAT_EMBEDDINGSCUSTOMEMBEDDING_LOOKUP_SPARSEHASHTABLE_LOOKUPLSH_PROJECTIONSKIP_GRAMSVDF