
Zadanie MediaPipe Gesture Recognizer umożliwia rozpoznawanie gestów dłoni w czasie rzeczywistym oraz dostarcza wyniki rozpoznanych gestów i punkty orientacyjne wykrytych dłoni. Z tych instrukcji dowiesz się, jak używać narzędzia do rozpoznawania gestów w aplikacjach internetowych i aplikacjach napisanych w JavaScript.
Możesz zobaczyć to zadanie w działaniu, oglądając demo. Więcej informacji o możliwościach, modelach i opcjach konfiguracji tego zadania znajdziesz w Przeglądzie.
Przykładowy kod
Przykładowy kod do rozpoznawania gestów zawiera pełną implementację tego zadania w JavaScript, z której możesz skorzystać. Ten kod pomoże Ci przetestować to zadanie i zacząć tworzyć własną aplikację do rozpoznawania gestów. Możesz wyświetlać, uruchamiać i edytować przykład rozpoznawania gestów w przeglądarce internetowej.
Konfiguracja
W tej sekcji opisujemy najważniejsze kroki konfigurowania środowiska programistycznego, które będzie używane do rozpoznawania gestów. Ogólne informacje o konfigurowaniu środowiska programistycznego dla sieci i JavaScriptu, w tym wymagania dotyczące wersji platformy, znajdziesz w przewodniku konfiguracji dla sieci.
Pakiety JavaScript
Kod rozpoznawania gestów jest dostępny w pakiecie MediaPipe @mediapipe/tasks-vision
NPM. Te biblioteki możesz znaleźć i pobrać, postępując zgodnie z instrukcjami w przewodniku konfiguracji platformy.
Wymagane pakiety możesz zainstalować za pomocą NPM, używając tego polecenia:
npm install @mediapipe/tasks-vision
Jeśli chcesz zaimportować kod zadania za pomocą usługi sieci dostarczania treści (CDN), dodaj ten kod w tagu <head> w pliku HTML:
<!-- You can replace JSDeliver with another CDN if you prefer to -->
<head>
<script src="https://cdn.jsdelivr.net/npm/@mediapipe/tasks-vision/vision_bundle.mjs"
crossorigin="anonymous"></script>
</head>
Model
Zadanie MediaPipe Gesture Recognizer wymaga wytrenowanego modelu, który jest z nim zgodny. Więcej informacji o dostępnych wytrenowanych modelach do rozpoznawania gestów znajdziesz w sekcji Modele w omówieniu zadania.
Wybierz i pobierz model, a następnie zapisz go w katalogu projektu:
<dev-project-root>/app/shared/models/
Tworzenie zadania
Użyj jednej z funkcji createFrom...() rozpoznawania gestów, aby przygotować zadanie do uruchomienia wnioskowania. Użyj funkcji createFromModelPath() ze ścieżką względną lub bezwzględną do wytrenowanego pliku modelu.
Jeśli model jest już załadowany do pamięci, możesz użyć metody createFromModelBuffer().
Poniższy przykładowy kod pokazuje, jak skonfigurować zadanie za pomocą funkcji createFromOptions(). Funkcja createFromOptions umożliwia dostosowanie narzędzia do rozpoznawania gestów za pomocą opcji konfiguracji. Więcej informacji o opcjach konfiguracji znajdziesz w artykule Opcje konfiguracji.
Poniższy kod pokazuje, jak utworzyć i skonfigurować zadanie z opcjami niestandardowymi:
// Create task for image file processing:
const vision = await FilesetResolver.forVisionTasks(
// path/to/wasm/root
"https://cdn.jsdelivr.net/npm/@mediapipe/tasks-vision@latest/wasm "
);
const gestureRecognizer = await GestureRecognizer.createFromOptions(vision, {
baseOptions: {
modelAssetPath: "https://storage.googleapis.com/mediapipe-tasks/gesture_recognizer/gesture_recognizer.task"
},
numHands: 2
});
Opcje konfiguracji
To zadanie ma te opcje konfiguracji aplikacji internetowych:
| Nazwa opcji | Opis | Zakres wartości | Wartość domyślna |
|---|---|---|---|
runningMode |
Ustawia tryb uruchamiania zadania. Dostępne są 2 tryby: OBRAZ: tryb dla pojedynczych obrazów. WIDEO: tryb dla zdekodowanych klatek filmu lub transmisji na żywo danych wejściowych, np. z kamery. |
{IMAGE, VIDEO} |
IMAGE |
num_hands |
Maksymalną liczbę rąk może wykryć GestureRecognizer.
|
Any integer > 0 |
1 |
min_hand_detection_confidence |
Minimalny poziom ufności wykrycia dłoni, który jest uznawany za udany w modelu wykrywania dłoni. | 0.0 - 1.0 |
0.5 |
min_hand_presence_confidence |
Minimalny poziom ufności wyniku obecności dłoni w modelu wykrywania punktów orientacyjnych dłoni. W trybie wideo i transmisji na żywo w usłudze Gesture Recognizer, jeśli wskaźnik ufności obecności dłoni z modelu punktów orientacyjnych dłoni jest niższy od tego progu, uruchamia model wykrywania dłoni. W przeciwnym razie używany jest prosty algorytm śledzenia rąk, który określa położenie dłoni w celu późniejszego wykrywania punktów orientacyjnych. | 0.0 - 1.0 |
0.5 |
min_tracking_confidence |
Minimalny poziom ufności, przy którym śledzenie rąk jest uznawane za udane. Jest to próg współczynnika podobieństwa ramek ograniczających między dłońmi w bieżącej i ostatniej klatce. W trybie wideo i trybie strumieniowania modułu rozpoznawania gestów, jeśli śledzenie się nie powiedzie, moduł rozpoznawania gestów uruchomi wykrywanie dłoni. W przeciwnym razie wykrywanie dłoni zostanie pominięte. | 0.0 - 1.0 |
0.5 |
canned_gestures_classifier_options |
Opcje konfigurowania działania klasyfikatora gotowych gestów. Gotowe gesty to ["None", "Closed_Fist", "Open_Palm", "Pointing_Up", "Thumb_Down", "Thumb_Up", "Victory", "ILoveYou"] |
|
|
custom_gestures_classifier_options |
Opcje konfigurowania działania klasyfikatora gestów niestandardowych. |
|
|
Przygotuj dane
Interfejs Gesture Recognizer może rozpoznawać gesty na obrazach w dowolnym formacie obsługiwanym przez przeglądarkę hosta. Zadanie to obejmuje też wstępne przetwarzanie danych wejściowych, w tym zmianę rozmiaru, obracanie i normalizację wartości. Aby rozpoznawać gesty w filmach, możesz użyć interfejsu API do szybkiego przetwarzania pojedynczych klatek. Sygnatura czasowa klatki pozwala określić, kiedy gesty występują w filmie.
Uruchamianie zadania
Rozpoznawanie gestów używa metod recognize() (w trybie 'image') i recognizeForVideo() (w trybie 'video') do wywoływania wnioskowania. Zadanie przetwarza dane, próbuje rozpoznać gesty dłoni, a następnie raportuje wyniki.
Poniższy kod pokazuje, jak wykonać przetwarzanie za pomocą modelu zadań:
Obraz
const image = document.getElementById("image") as HTMLImageElement; const gestureRecognitionResult = gestureRecognizer.recognize(image);
Wideo
await gestureRecognizer.setOptions({ runningMode: "video" }); let lastVideoTime = -1; function renderLoop(): void { const video = document.getElementById("video"); if (video.currentTime !== lastVideoTime) { const gestureRecognitionResult = gestureRecognizer.recognizeForVideo(video); processResult(gestureRecognitionResult); lastVideoTime = video.currentTime; } requestAnimationFrame(() => { renderLoop(); }); }
Wywołania metod recognize() i recognizeForVideo() narzędzia Gesture Recognizer działają synchronicznie i blokują wątek interfejsu użytkownika. Jeśli rozpoznajesz gesty w klatkach wideo z kamery urządzenia, każde rozpoznanie zablokuje główny wątek. Możesz temu zapobiec, wdrażając procesy robocze, które będą uruchamiać metody recognize() i recognizeForVideo() w innym wątku.
Bardziej szczegółowe informacje o wdrażaniu zadania rozpoznawania gestów znajdziesz w przykładzie.
Obsługa i wyświetlanie wyników
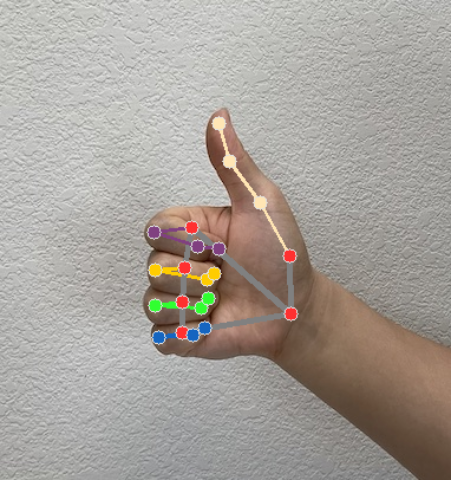
Moduł rozpoznawania gestów generuje obiekt wyniku wykrywania gestów dla każdego uruchomienia rozpoznawania. Obiekt wyniku zawiera punkty charakterystyczne dłoni we współrzędnych obrazu, punkty charakterystyczne dłoni we współrzędnych świata, informację o tym, czy dłoń jest lewa czy prawa, oraz kategorie gestów dłoni wykrytych dłoni.
Poniżej znajdziesz przykład danych wyjściowych tego zadania:
Wynikowy element GestureRecognizerResult zawiera 4 komponenty, a każdy z nich jest tablicą, której poszczególne elementy zawierają wykryte wyniki pojedynczej wykrytej dłoni.
Ręka dominująca
Ręka dominująca określa, czy wykryte dłonie to lewa czy prawa ręka.
Gesty
Rozpoznane kategorie gestów wykrytych dłoni.
Punkty orientacyjne
Wyróżniamy 21 punktów orientacyjnych dłoni, z których każdy składa się ze współrzędnych
x,yiz. Współrzędnexiysą normalizowane do zakresu [0.0, 1.0] odpowiednio przez szerokość i wysokość obrazu. Współrzędnazreprezentuje głębokość punktu orientacyjnego, a punktem początkowym jest głębokość na nadgarstku. Im mniejsza wartość, tym bliżej aparatu znajduje się punkt orientacyjny. Wartośćzjest w przybliżeniu w tej samej skali cox.Punkty orientacyjne na świecie
21 punktów orientacyjnych dłoni jest też przedstawionych we współrzędnych świata. Każdy punkt orientacyjny składa się z wartości
x,yiz, które reprezentują rzeczywiste współrzędne 3D w metrach, a punktem początkowym jest geometryczny środek dłoni.
GestureRecognizerResult:
Handedness:
Categories #0:
index : 0
score : 0.98396
categoryName : Left
Gestures:
Categories #0:
score : 0.76893
categoryName : Thumb_Up
Landmarks:
Landmark #0:
x : 0.638852
y : 0.671197
z : -3.41E-7
Landmark #1:
x : 0.634599
y : 0.536441
z : -0.06984
... (21 landmarks for a hand)
WorldLandmarks:
Landmark #0:
x : 0.067485
y : 0.031084
z : 0.055223
Landmark #1:
x : 0.063209
y : -0.00382
z : 0.020920
... (21 world landmarks for a hand)
Na ilustracjach poniżej widać wizualizację wyników zadania:
Bardziej szczegółową implementację tworzenia zadania rozpoznawania gestów znajdziesz w przykładzie.