
The MediaPipe Hand Landmarker task lets you detect the landmarks of the hands in an image. These instructions show you how to use the Hand Landmarker for web and JavaScript apps.
For more information about the capabilities, models, and configuration options of this task, see the Overview.
Code example
The example code for Hand Landmarker provides a complete implementation of this task in JavaScript for your reference. This code helps you test this task and get started on building your own hand landmark detection app. You can view, run, and edit the Hand Landmarker example using just your web browser.
Setup
This section describes key steps for setting up your development environment specifically to use Hand Landmarker. For general information on setting up your web and JavaScript development environment, including platform version requirements, see the Setup guide for web.
JavaScript packages
Hand Landmarker code is available through the MediaPipe @mediapipe/tasks-vision
NPM package. You can
find and download these libraries by following the instructions in the platform
Setup guide.
You can install the required packages through NPM using the following command:
npm install @mediapipe/tasks-vision
If you want to import the task code via a content delivery network (CDN) service, add the following code in the <head> tag in your HTML file:
<!-- You can replace JSDeliver with another CDN if you prefer to -->
<head>
<script src="https://cdn.jsdelivr.net/npm/@mediapipe/tasks-vision/vision_bundle.mjs"
crossorigin="anonymous"></script>
</head>
Model
The MediaPipe Hand Landmarker task requires a trained model that is compatible with this task. For more information on available trained models for Hand Landmarker, see the task overview Models section.
Select and download a model, and then store it within your project directory:
<dev-project-root>/app/shared/models/
Create the task
Use one of the Hand Landmarker createFrom...() functions to
prepare the task for running inferences. Use the createFromModelPath()
function with a relative or absolute path to the trained model file.
If your model is already loaded into memory, you can use the
createFromModelBuffer() method.
The code example below demonstrates using the createFromOptions() function to
set up the task. The createFromOptions function allows you to customize the
Hand Landmarker with configuration options. For more information on configuration
options, see Configuration options.
The following code demonstrates how to build and configure the task with custom options:
const vision = await FilesetResolver.forVisionTasks(
// path/to/wasm/root
"https://cdn.jsdelivr.net/npm/@mediapipe/tasks-vision@latest/wasm"
);
const handLandmarker = await HandLandmarker.createFromOptions(
vision,
{
baseOptions: {
modelAssetPath: "hand_landmarker.task"
},
numHands: 2
});
Configuration options
This task has the following configuration options for Web and JavaScript applications:
| Option Name | Description | Value Range | Default Value |
|---|---|---|---|
runningMode |
Sets the running mode for the task. There are two
modes: IMAGE: The mode for single image inputs. VIDEO: The mode for decoded frames of a video or on a livestream of input data, such as from a camera. |
{IMAGE, VIDEO} |
IMAGE |
numHands |
The maximum number of hands detected by the Hand landmark detector. | Any integer > 0 |
1 |
minHandDetectionConfidence |
The minimum confidence score for the hand detection to be considered successful in palm detection model. | 0.0 - 1.0 |
0.5 |
minHandPresenceConfidence |
The minimum confidence score for the hand presence score in the hand landmark detection model. In Video mode and Live stream mode, if the hand presence confidence score from the hand landmark model is below this threshold, Hand Landmarker triggers the palm detection model. Otherwise, a lightweight hand tracking algorithm determines the location of the hand(s) for subsequent landmark detections. | 0.0 - 1.0 |
0.5 |
minTrackingConfidence |
The minimum confidence score for the hand tracking to be considered successful. This is the bounding box IoU threshold between hands in the current frame and the last frame. In Video mode and Stream mode of Hand Landmarker, if the tracking fails, Hand Landmarker triggers hand detection. Otherwise, it skips the hand detection. | 0.0 - 1.0 |
0.5 |
Prepare data
Hand Landmarker can detect hand landmarks in images in any format supported by the host browser. The task also handles data input preprocessing, including resizing, rotation and value normalization. To detect hand landmarks in videos, you can use the API to quickly process one frame at a time, using the timestamp of the frame to determine when the hand landmarks occur within the video.
Run the task
The Hand Landmarker uses the detect() (with running mode image) and
detectForVideo() (with running mode video) methods to trigger
inferences. The task processes the data, attempts to detect hand landmarks, and
then reports the results.
Calls to the Hand Landmarker detect() and detectForVideo() methods run
synchronously and block the user interface thread. If you detect hand landmarks
in video frames from a device's camera, each detection blocks the main
thread. You can prevent this by implementing web workers to run the detect()
and detectForVideo() methods on another thread.
The following code demonstrates how execute the processing with the task model:
Image
const image = document.getElementById("image") as HTMLImageElement; const handLandmarkerResult = handLandmarker.detect(image);
Video
await handLandmarker.setOptions({ runningMode: "video" }); let lastVideoTime = -1; function renderLoop(): void { const video = document.getElementById("video"); if (video.currentTime !== lastVideoTime) { const detections = handLandmarker.detectForVideo(video); processResults(detections); lastVideoTime = video.currentTime; } requestAnimationFrame(() => { renderLoop(); }); }
For a more complete implementation of running an Hand Landmarker task, see the example.
Handle and display results
The Hand Landmarker generates a hand landmarker result object for each detection run. The result object contains hand landmarks in image coordinates, hand landmarks in world coordinates and handedness(left/right hand) of the detected hands.
The following shows an example of the output data from this task:
The HandLandmarkerResult output contains three components. Each component is an array, where each element contains the following results for a single detected hand:
Handedness
Handedness represents whether the detected hands are left or right hands.
Landmarks
There are 21 hand landmarks, each composed of
x,yandzcoordinates. Thexandycoordinates are normalized to [0.0, 1.0] by the image width and height, respectively. Thezcoordinate represents the landmark depth, with the depth at the wrist being the origin. The smaller the value, the closer the landmark is to the camera. The magnitude ofzuses roughly the same scale asx.World Landmarks
The 21 hand landmarks are also presented in world coordinates. Each landmark is composed of
x,y, andz, representing real-world 3D coordinates in meters with the origin at the hand’s geometric center.
HandLandmarkerResult:
Handedness:
Categories #0:
index : 0
score : 0.98396
categoryName : Left
Landmarks:
Landmark #0:
x : 0.638852
y : 0.671197
z : -3.41E-7
Landmark #1:
x : 0.634599
y : 0.536441
z : -0.06984
... (21 landmarks for a hand)
WorldLandmarks:
Landmark #0:
x : 0.067485
y : 0.031084
z : 0.055223
Landmark #1:
x : 0.063209
y : -0.00382
z : 0.020920
... (21 world landmarks for a hand)
The following image shows a visualization of the task output:
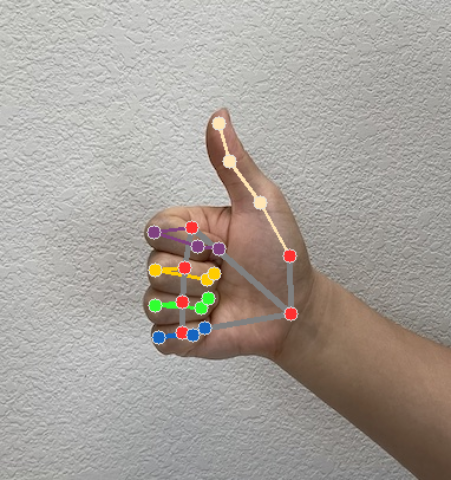
The Hand Landmarker example code demonstrates how to display the results returned from the task, see the example