
|
|
|
 الاطّلاع على المصدر على GitHub الاطّلاع على المصدر على GitHub
|
نظرة عامة
يوضّح هذا البرنامج التعليمي كيفية إجراء عرض مرئي للتجميع العنقودي وتنفيذه باستخدام عمليات التضمين من واجهة برمجة تطبيقات Gemini. ستتمكّن من إنشاء تمثيل مرئي لمجموعة فرعية من مجموعة البيانات التي تضم 20 مجموعة أخبار باستخدام t-SNE وتجميع هذه المجموعة الفرعية باستخدام خوارزمية KMeans.
للحصول على مزيد من المعلومات حول بدء استخدام التضمينات التي تمّ إنشاؤها من Gemini API، يُرجى الاطّلاع على صفحة Python quickstart (البدء السريع) في Python.
المتطلبات الأساسية
يمكنك تشغيل دليل البدء السريع هذا في Google Colab.
لإكمال هذه البدء السريع في بيئة التطوير الخاصة بك، تأكد من أن بيئتك تفي بالمتطلبات التالية:
- Python 3.9 أو إصدار أحدث
- تثبيت
jupyterلتشغيل دفتر الملاحظات.
ضبط إعدادات الجهاز
أولاً، عليك تنزيل مكتبة Gemini API Python وتثبيتها.
pip install -U -q google.generativeai
import re
import tqdm
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import google.generativeai as genai
import google.ai.generativelanguage as glm
# Used to securely store your API key
from google.colab import userdata
from sklearn.datasets import fetch_20newsgroups
from sklearn.manifold import TSNE
from sklearn.cluster import KMeans
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
الحصول على مفتاح واجهة برمجة التطبيقات
قبل أن تتمكّن من استخدام واجهة برمجة تطبيقات Gemini، يجب أولاً الحصول على مفتاح واجهة برمجة التطبيقات. أنشِئ مفتاحًا بنقرة واحدة في "استوديو Google AI" إذا لم يكن لديك مفتاح.
الحصول على مفتاح واجهة برمجة التطبيقات
في Colab، أضِف المفتاح إلى أداة إدارة الأسرار ضمن "🔑" في اللوحة اليمنى. أدخِل الاسم "API_KEY".
بعد حصولك على مفتاح واجهة برمجة التطبيقات، أرسِله إلى حزمة تطوير البرامج (SDK). هناك طريقتان لإجراء ذلك:
- ضَع المفتاح في متغيّر بيئة
GOOGLE_API_KEY(ستحصل عليه حزمة تطوير البرامج (SDK) تلقائيًا من هناك). - تمرير المفتاح إلى "
genai.configure(api_key=...)"
# Or use `os.getenv('API_KEY')` to fetch an environment variable.
API_KEY=userdata.get('API_KEY')
genai.configure(api_key=API_KEY)
for m in genai.list_models():
if 'embedContent' in m.supported_generation_methods:
print(m.name)
models/embedding-001 models/embedding-001
مجموعة البيانات
تضم مجموعة البيانات النصية الخاصة بـ 20 مجموعة إخبارية 18,000 مشاركة في المجموعات الإخبارية حول 20 موضوعًا يتم تقسيمها إلى مجموعات تدريب واختبار. يستند التقسيم بين مجموعات بيانات التدريب والاختبار على الرسائل المنشورة قبل تاريخ محدّد وبعده. في هذا البرنامج التعليمي، ستستخدم المجموعة الفرعية للتدريب.
newsgroups_train = fetch_20newsgroups(subset='train')
# View list of class names for dataset
newsgroups_train.target_names
['alt.atheism', 'comp.graphics', 'comp.os.ms-windows.misc', 'comp.sys.ibm.pc.hardware', 'comp.sys.mac.hardware', 'comp.windows.x', 'misc.forsale', 'rec.autos', 'rec.motorcycles', 'rec.sport.baseball', 'rec.sport.hockey', 'sci.crypt', 'sci.electronics', 'sci.med', 'sci.space', 'soc.religion.christian', 'talk.politics.guns', 'talk.politics.mideast', 'talk.politics.misc', 'talk.religion.misc']
إليك المثال الأول في مجموعة التطبيق.
idx = newsgroups_train.data[0].index('Lines')
print(newsgroups_train.data[0][idx:])
Lines: 15 I was wondering if anyone out there could enlighten me on this car I saw the other day. It was a 2-door sports car, looked to be from the late 60s/ early 70s. It was called a Bricklin. The doors were really small. In addition, the front bumper was separate from the rest of the body. This is all I know. If anyone can tellme a model name, engine specs, years of production, where this car is made, history, or whatever info you have on this funky looking car, please e-mail. Thanks, - IL ---- brought to you by your neighborhood Lerxst ----
# Apply functions to remove names, emails, and extraneous words from data points in newsgroups.data
newsgroups_train.data = [re.sub(r'[\w\.-]+@[\w\.-]+', '', d) for d in newsgroups_train.data] # Remove email
newsgroups_train.data = [re.sub(r"\([^()]*\)", "", d) for d in newsgroups_train.data] # Remove names
newsgroups_train.data = [d.replace("From: ", "") for d in newsgroups_train.data] # Remove "From: "
newsgroups_train.data = [d.replace("\nSubject: ", "") for d in newsgroups_train.data] # Remove "\nSubject: "
# Put training points into a dataframe
df_train = pd.DataFrame(newsgroups_train.data, columns=['Text'])
df_train['Label'] = newsgroups_train.target
# Match label to target name index
df_train['Class Name'] = df_train['Label'].map(newsgroups_train.target_names.__getitem__)
# Retain text samples that can be used in the gecko model.
df_train = df_train[df_train['Text'].str.len() < 10000]
df_train
بعد ذلك، ستقوم بأخذ عينة من بعض البيانات عن طريق أخذ 100 نقطة بيانات في مجموعة بيانات التدريب، وإسقاط بعض الفئات لتشغيلها من خلال هذا البرنامج التعليمي. اختيار الفئات العلمية لمقارنتها
# Take a sample of each label category from df_train
SAMPLE_SIZE = 150
df_train = (df_train.groupby('Label', as_index = False)
.apply(lambda x: x.sample(SAMPLE_SIZE))
.reset_index(drop=True))
# Choose categories about science
df_train = df_train[df_train['Class Name'].str.contains('sci')]
# Reset the index
df_train = df_train.reset_index()
df_train
df_train['Class Name'].value_counts()
sci.crypt 150 sci.electronics 150 sci.med 150 sci.space 150 Name: Class Name, dtype: int64
إنشاء التضمينات
في هذا القسم، ستطّلع على كيفية إنشاء تضمينات للنصوص المختلفة في إطار البيانات باستخدام التضمينات من واجهة برمجة تطبيقات Gemini.
تغييرات في واجهة برمجة التطبيقات على عمليات التضمين باستخدام نموذج التضمين-001
بالنسبة إلى نموذج التضمين الجديد، تضمين-001، تتوفّر مَعلمة جديدة لنوع المهمة وعنوان اختياري (صالح فقط مع task_type=RETRIEVAL_DOCUMENT).
لا تنطبق هذه المَعلمات الجديدة إلّا على أحدث نماذج التضمينات.وفي ما يلي أنواع المهام:
| نوع المهمة | الوصف |
|---|---|
| RETRIEVAL_QUERY | لتحديد النص المحدد عبارة عن طلب بحث في إعداد بحث/استرداد. |
| RETRIEVAL_DOCUMENT | لتحديد النص المحدد هو مستند في إعداد البحث/الاسترجاع. |
| SEMANTIC_SIMILARITY | لتحديد هذا الخيار، سيتم استخدام النص المحدَّد في التشابه الدلالي (STS). |
| التصنيف | تُحدِّد أنه سيتم استخدام التضمينات للتصنيف. |
| التجميع | تحدّد هذه السمة أنّه سيتم استخدام التضمينات للتجميع العنقودي. |
from tqdm.auto import tqdm
tqdm.pandas()
from google.api_core import retry
def make_embed_text_fn(model):
@retry.Retry(timeout=300.0)
def embed_fn(text: str) -> list[float]:
# Set the task_type to CLUSTERING.
embedding = genai.embed_content(model=model,
content=text,
task_type="clustering")
return embedding["embedding"]
return embed_fn
def create_embeddings(df):
model = 'models/embedding-001'
df['Embeddings'] = df['Text'].progress_apply(make_embed_text_fn(model))
return df
df_train = create_embeddings(df_train)
0%| | 0/600 [00:00<?, ?it/s]
خفض الأبعاد
طول الخط المتجه لتضمين المستند هو 768. لعرض كيفية تجميع المستندات المضمّنة معًا، ستحتاج إلى تطبيق خيار تقليل الأبعاد، حيث يمكنك عرض المحتوى المضمّن فقط في مساحة ثنائية أو ثلاثية الأبعاد. يجب أن تكون المستندات المتشابهة من حيث السياق قريبة من بعضها البعض في المساحة بدلاً من المستندات غير المتشابهة.
len(df_train['Embeddings'][0])
768
# Convert df_train['Embeddings'] Pandas series to a np.array of float32
X = np.array(df_train['Embeddings'].to_list(), dtype=np.float32)
X.shape
(600, 768)
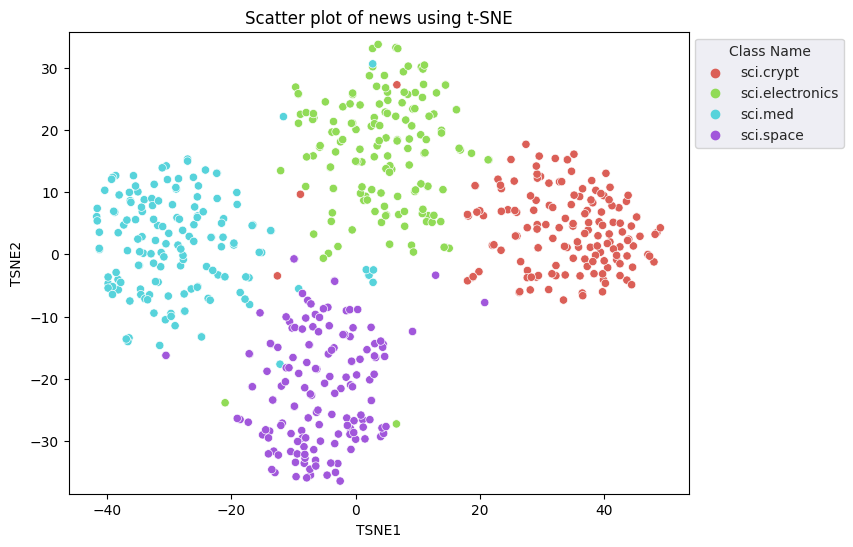
وستطبق منهج تضمين الجار الأقرب (t-SNE) الموزع على الموزع (t-SNE) لخفض الأبعاد. ويقلل هذا الأسلوب من عدد الأبعاد، مع الحفاظ على المجموعات العنقودية (تبقى النقاط القريبة من بعضها قريبة من بعضها البعض). بالنسبة للبيانات الأصلية، يحاول النموذج إنشاء توزيع تكون فيه نقاط البيانات الأخرى "جيران" (على سبيل المثال، تشترك في نفس المعنى). ثم تقوم بتحسين دالة موضوعية للحفاظ على توزيع مماثل في التصور.
tsne = TSNE(random_state=0, n_iter=1000)
tsne_results = tsne.fit_transform(X)
df_tsne = pd.DataFrame(tsne_results, columns=['TSNE1', 'TSNE2'])
df_tsne['Class Name'] = df_train['Class Name'] # Add labels column from df_train to df_tsne
df_tsne
fig, ax = plt.subplots(figsize=(8,6)) # Set figsize
sns.set_style('darkgrid', {"grid.color": ".6", "grid.linestyle": ":"})
sns.scatterplot(data=df_tsne, x='TSNE1', y='TSNE2', hue='Class Name', palette='hls')
sns.move_legend(ax, "upper left", bbox_to_anchor=(1, 1))
plt.title('Scatter plot of news using t-SNE');
plt.xlabel('TSNE1');
plt.ylabel('TSNE2');
plt.axis('equal')
(-46.191162300109866, 53.521015357971194, -39.96646995544434, 37.282975387573245)
مقارنة النتائج بـ KMeans
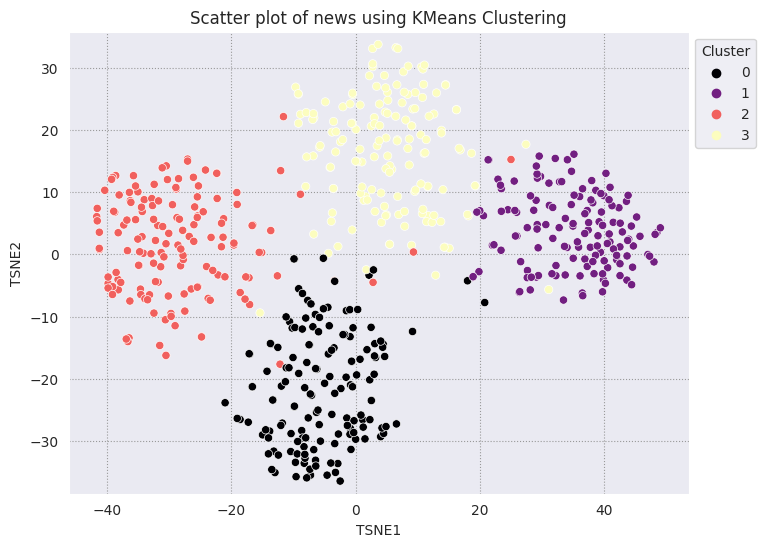
يُعد التجميع العنقودي لآلية KMe خوارزمية تجميع شائعة وتُستخدم غالبًا للتعلم غير الخاضع للإشراف. ويحدد التكرار التحسيني أفضل نقاط مركزية لكل نقطة، ويعيِّن كل مثال إلى أقرب نقطة مركزية. أدخل التضمينات مباشرةً في خوارزمية KMeans لمقارنة تصور تضمينات أداء خوارزمية التعلم الآلي.
# Apply KMeans
kmeans_model = KMeans(n_clusters=4, random_state=1, n_init='auto').fit(X)
labels = kmeans_model.fit_predict(X)
df_tsne['Cluster'] = labels
df_tsne
fig, ax = plt.subplots(figsize=(8,6)) # Set figsize
sns.set_style('darkgrid', {"grid.color": ".6", "grid.linestyle": ":"})
sns.scatterplot(data=df_tsne, x='TSNE1', y='TSNE2', hue='Cluster', palette='magma')
sns.move_legend(ax, "upper left", bbox_to_anchor=(1, 1))
plt.title('Scatter plot of news using KMeans Clustering');
plt.xlabel('TSNE1');
plt.ylabel('TSNE2');
plt.axis('equal')
(-46.191162300109866, 53.521015357971194, -39.96646995544434, 37.282975387573245)
def get_majority_cluster_per_group(df_tsne_cluster, class_names):
class_clusters = dict()
for c in class_names:
# Get rows of dataframe that are equal to c
rows = df_tsne_cluster.loc[df_tsne_cluster['Class Name'] == c]
# Get majority value in Cluster column of the rows selected
cluster = rows.Cluster.mode().values[0]
# Populate mapping dictionary
class_clusters[c] = cluster
return class_clusters
classes = df_tsne['Class Name'].unique()
class_clusters = get_majority_cluster_per_group(df_tsne, classes)
class_clusters
{'sci.crypt': 1, 'sci.electronics': 3, 'sci.med': 2, 'sci.space': 0}
احصل على غالبية المجموعات لكل مجموعة، وشاهد عدد الأعضاء الفعليين في تلك المجموعة في تلك المجموعة.
# Convert the Cluster column to use the class name
class_by_id = {v: k for k, v in class_clusters.items()}
df_tsne['Predicted'] = df_tsne['Cluster'].map(class_by_id.__getitem__)
# Filter to the correctly matched rows
correct = df_tsne[df_tsne['Class Name'] == df_tsne['Predicted']]
# Summarise, as a percentage
acc = correct['Class Name'].value_counts() / SAMPLE_SIZE
acc
sci.space 0.966667 sci.med 0.960000 sci.electronics 0.953333 sci.crypt 0.926667 Name: Class Name, dtype: float64
# Get predicted values by name
df_tsne['Predicted'] = ''
for idx, rows in df_tsne.iterrows():
cluster = rows['Cluster']
# Get key from mapping based on cluster value
key = list(class_clusters.keys())[list(class_clusters.values()).index(cluster)]
df_tsne.at[idx, 'Predicted'] = key
df_tsne
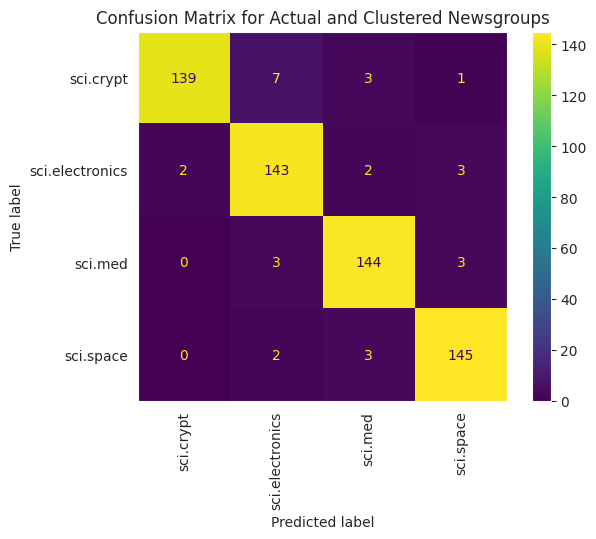
للحصول على تمثيل بصري أفضل لأداء وحدات KMe المطبَّقة على بياناتك، يمكنك استخدام مصفوفة التشويش. وتتيح لك مصفوفة التشويش تقييم أداء نموذج التصنيف بطريقة تتجاوز الدقة. ستظهر لك النقاط التي تم تصنيفها بشكل خاطئ. ستحتاج إلى القيم الفعلية والقيم المتوقعة، التي جمعتها في إطار البيانات أعلاه.
cm = confusion_matrix(df_tsne['Class Name'].to_list(), df_tsne['Predicted'].to_list())
disp = ConfusionMatrixDisplay(confusion_matrix=cm,
display_labels=classes)
disp.plot(xticks_rotation='vertical')
plt.title('Confusion Matrix for Actual and Clustered Newsgroups');
plt.grid(False)
الخطوات التالية
لقد قمت الآن بإنشاء تصور خاص بك للتضمينات باستخدام التجميع العنقودي! جرِّب استخدام بياناتك النصية الخاصة بك لعرضها كتضمينات. يمكنك إجراء خفض الأبعاد من أجل إكمال خطوة التمثيل المرئي. لاحظ أن TSNE جيدة في تجميع المدخلات، ولكنها قد تستغرق وقتًا أطول للتقارب أو قد تتعثر عند الحد الأدنى المحلي. إذا واجهت هذه المشكلة، يمكنك أيضًا استخدام تحليل المكوّنات الرئيسية (PCA).
هناك أيضًا خوارزميات تجميع أخرى خارج نطاق KMe، مثل التجميع العنقودي المكاني القائم على الكثافة (DBSCAN).
لمعرفة كيفية استخدام الخدمات الأخرى في Gemini API، يُرجى الانتقال إلى Python quickstart (البدء السريع) في Python. للمزيد من المعلومات حول كيفية استخدام التضمينات، يمكنك الاطّلاع على الأمثلة المتاحة. للتعرّف على كيفية إنشائها من البداية، اطّلِع على دليل عمليات تضمين الكلمات في TensorFlow.