
| | |  Посмотреть исходный код на GitHub Посмотреть исходный код на GitHub |
Обзор
В этом руководстве показано, как визуализировать и выполнять кластеризацию с помощью вложений из Gemini API. Вы визуализируете подмножество набора данных 20 групп новостей с помощью t-SNE и кластеризуете это подмножество с помощью алгоритма KMeans.
Для получения дополнительной информации о начале работы с встраиваниями, созданными с помощью API Gemini, ознакомьтесь с кратким руководством по Python .
Предварительные условия
Вы можете запустить это краткое руководство в Google Colab.
Чтобы выполнить это краткое руководство по созданию собственной среды разработки, убедитесь, что ваша среда соответствует следующим требованиям:
- Питон 3.9+
- Установка
jupyterдля запуска ноутбука.
Настраивать
Сначала загрузите и установите библиотеку Python Gemini API.
pip install -U -q google.generativeai
import re
import tqdm
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import google.generativeai as genai
import google.ai.generativelanguage as glm
# Used to securely store your API key
from google.colab import userdata
from sklearn.datasets import fetch_20newsgroups
from sklearn.manifold import TSNE
from sklearn.cluster import KMeans
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
Получите ключ API
Прежде чем вы сможете использовать API Gemini, вам необходимо сначала получить ключ API. Если у вас его еще нет, создайте ключ одним щелчком мыши в Google AI Studio.
В Colab добавьте ключ к менеджеру секретов под знаком «🔑» на левой панели. Дайте ему имя API_KEY .
Получив ключ API, передайте его в SDK. Вы можете сделать это двумя способами:
- Поместите ключ в переменную среды
GOOGLE_API_KEY(SDK автоматически подберет его оттуда). - Передайте ключ в
genai.configure(api_key=...)
# Or use `os.getenv('API_KEY')` to fetch an environment variable.
API_KEY=userdata.get('API_KEY')
genai.configure(api_key=API_KEY)
for m in genai.list_models():
if 'embedContent' in m.supported_generation_methods:
print(m.name)
models/embedding-001 models/embedding-001
Набор данных
Набор текстовых данных 20 групп новостей содержит 18 000 сообщений групп новостей по 20 темам, разделенным на обучающие и тестовые наборы. Разделение наборов обучающих и тестовых данных основано на сообщениях, опубликованных до и после определенной даты. В этом уроке вы будете использовать обучающую подгруппу.
newsgroups_train = fetch_20newsgroups(subset='train')
# View list of class names for dataset
newsgroups_train.target_names
['alt.atheism', 'comp.graphics', 'comp.os.ms-windows.misc', 'comp.sys.ibm.pc.hardware', 'comp.sys.mac.hardware', 'comp.windows.x', 'misc.forsale', 'rec.autos', 'rec.motorcycles', 'rec.sport.baseball', 'rec.sport.hockey', 'sci.crypt', 'sci.electronics', 'sci.med', 'sci.space', 'soc.religion.christian', 'talk.politics.guns', 'talk.politics.mideast', 'talk.politics.misc', 'talk.religion.misc']
Вот первый пример в обучающем наборе.
idx = newsgroups_train.data[0].index('Lines')
print(newsgroups_train.data[0][idx:])
Lines: 15 I was wondering if anyone out there could enlighten me on this car I saw the other day. It was a 2-door sports car, looked to be from the late 60s/ early 70s. It was called a Bricklin. The doors were really small. In addition, the front bumper was separate from the rest of the body. This is all I know. If anyone can tellme a model name, engine specs, years of production, where this car is made, history, or whatever info you have on this funky looking car, please e-mail. Thanks, - IL ---- brought to you by your neighborhood Lerxst ----
# Apply functions to remove names, emails, and extraneous words from data points in newsgroups.data
newsgroups_train.data = [re.sub(r'[\w\.-]+@[\w\.-]+', '', d) for d in newsgroups_train.data] # Remove email
newsgroups_train.data = [re.sub(r"\([^()]*\)", "", d) for d in newsgroups_train.data] # Remove names
newsgroups_train.data = [d.replace("From: ", "") for d in newsgroups_train.data] # Remove "From: "
newsgroups_train.data = [d.replace("\nSubject: ", "") for d in newsgroups_train.data] # Remove "\nSubject: "
# Put training points into a dataframe
df_train = pd.DataFrame(newsgroups_train.data, columns=['Text'])
df_train['Label'] = newsgroups_train.target
# Match label to target name index
df_train['Class Name'] = df_train['Label'].map(newsgroups_train.target_names.__getitem__)
# Retain text samples that can be used in the gecko model.
df_train = df_train[df_train['Text'].str.len() < 10000]
df_train
Затем вы выберете некоторые данные, взяв 100 точек данных из набора обучающих данных и удалив несколько категорий, чтобы пройти через это руководство. Выберите научные категории для сравнения.
# Take a sample of each label category from df_train
SAMPLE_SIZE = 150
df_train = (df_train.groupby('Label', as_index = False)
.apply(lambda x: x.sample(SAMPLE_SIZE))
.reset_index(drop=True))
# Choose categories about science
df_train = df_train[df_train['Class Name'].str.contains('sci')]
# Reset the index
df_train = df_train.reset_index()
df_train
df_train['Class Name'].value_counts()
sci.crypt 150 sci.electronics 150 sci.med 150 sci.space 150 Name: Class Name, dtype: int64
Создайте вложения
В этом разделе вы увидите, как создавать внедрения для различных текстов в кадре данных, используя внедрения из API Gemini.
Изменения API для внедрения с использованием модели-001
Для новой модели внедрения, embedding-001, имеется новый параметр типа задачи и необязательный заголовок (действителен только с Task_type= RETRIEVAL_DOCUMENT ).
Эти новые параметры применяются только к новейшим моделям внедрения. Типы задач:
| Тип задачи | Описание |
|---|---|
| RETRIEVAL_QUERY | Указывает, что данный текст является запросом в настройках поиска/извлечения. |
| RETRIEVAL_DOCUMENT | Указывает, что данный текст является документом в настройках поиска/извлечения. |
| СЕМАНТИЧЕСКОЕ_ПОХОЖИЕ | Указывает, что данный текст будет использоваться для семантического текстового сходства (STS). |
| КЛАССИФИКАЦИЯ | Указывает, что внедрения будут использоваться для классификации. |
| КЛАСТЕРИЗАЦИЯ | Указывает, что внедрения будут использоваться для кластеризации. |
from tqdm.auto import tqdm
tqdm.pandas()
from google.api_core import retry
def make_embed_text_fn(model):
@retry.Retry(timeout=300.0)
def embed_fn(text: str) -> list[float]:
# Set the task_type to CLUSTERING.
embedding = genai.embed_content(model=model,
content=text,
task_type="clustering")
return embedding["embedding"]
return embed_fn
def create_embeddings(df):
model = 'models/embedding-001'
df['Embeddings'] = df['Text'].progress_apply(make_embed_text_fn(model))
return df
df_train = create_embeddings(df_train)
0%| | 0/600 [00:00<?, ?it/s]
Уменьшение размерности
Длина вектора внедрения документа составляет 768. Чтобы визуализировать, как внедренные документы сгруппированы вместе, вам необходимо применить уменьшение размерности, поскольку вы можете визуализировать внедрения только в 2D или 3D пространстве. Контекстуально схожие документы должны располагаться ближе друг к другу в пространстве, в отличие от документов, которые не так похожи.
len(df_train['Embeddings'][0])
768
# Convert df_train['Embeddings'] Pandas series to a np.array of float32
X = np.array(df_train['Embeddings'].to_list(), dtype=np.float32)
X.shape
(600, 768)
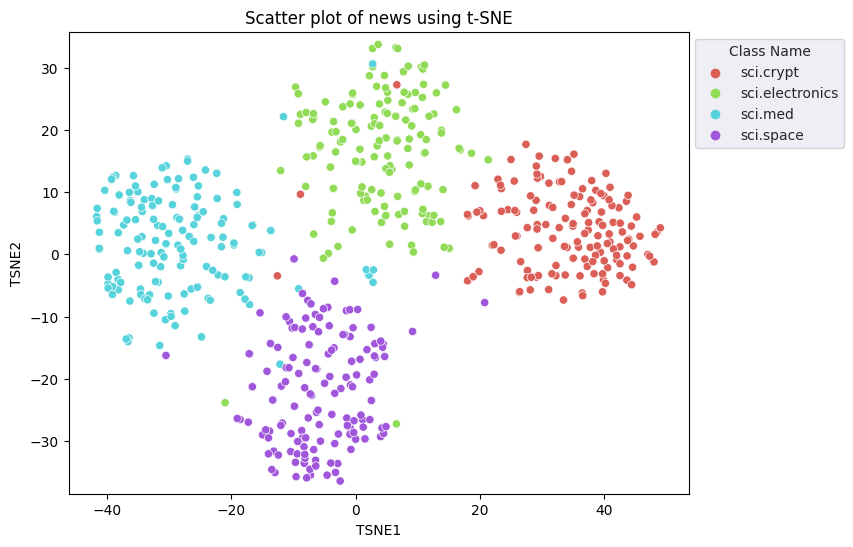
Вы примените подход t-Distributed Stochastic Neighbor Embedding (t-SNE) для уменьшения размерности. Этот метод уменьшает количество измерений, сохраняя при этом кластеры (точки, расположенные близко друг к другу, остаются близко друг к другу). Для исходных данных модель пытается построить распределение, в котором другие точки данных являются «соседями» (например, имеют схожее значение). Затем он оптимизирует целевую функцию, чтобы сохранить аналогичное распределение в визуализации.
tsne = TSNE(random_state=0, n_iter=1000)
tsne_results = tsne.fit_transform(X)
df_tsne = pd.DataFrame(tsne_results, columns=['TSNE1', 'TSNE2'])
df_tsne['Class Name'] = df_train['Class Name'] # Add labels column from df_train to df_tsne
df_tsne
fig, ax = plt.subplots(figsize=(8,6)) # Set figsize
sns.set_style('darkgrid', {"grid.color": ".6", "grid.linestyle": ":"})
sns.scatterplot(data=df_tsne, x='TSNE1', y='TSNE2', hue='Class Name', palette='hls')
sns.move_legend(ax, "upper left", bbox_to_anchor=(1, 1))
plt.title('Scatter plot of news using t-SNE');
plt.xlabel('TSNE1');
plt.ylabel('TSNE2');
plt.axis('equal')
(-46.191162300109866, 53.521015357971194, -39.96646995544434, 37.282975387573245)
Сравните результаты с KMeans
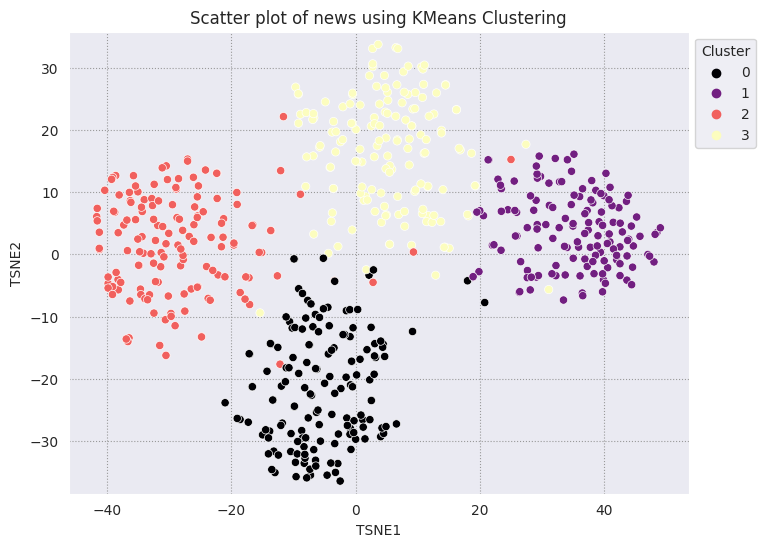
Кластеризация KMeans — популярный алгоритм кластеризации, который часто используется для обучения без учителя. Он итеративно определяет k лучших центральных точек и присваивает каждому примеру ближайший центроид. Введите вложения непосредственно в алгоритм KMeans, чтобы сравнить визуализацию вложений с производительностью алгоритма машинного обучения.
# Apply KMeans
kmeans_model = KMeans(n_clusters=4, random_state=1, n_init='auto').fit(X)
labels = kmeans_model.fit_predict(X)
df_tsne['Cluster'] = labels
df_tsne
fig, ax = plt.subplots(figsize=(8,6)) # Set figsize
sns.set_style('darkgrid', {"grid.color": ".6", "grid.linestyle": ":"})
sns.scatterplot(data=df_tsne, x='TSNE1', y='TSNE2', hue='Cluster', palette='magma')
sns.move_legend(ax, "upper left", bbox_to_anchor=(1, 1))
plt.title('Scatter plot of news using KMeans Clustering');
plt.xlabel('TSNE1');
plt.ylabel('TSNE2');
plt.axis('equal')
(-46.191162300109866, 53.521015357971194, -39.96646995544434, 37.282975387573245)
def get_majority_cluster_per_group(df_tsne_cluster, class_names):
class_clusters = dict()
for c in class_names:
# Get rows of dataframe that are equal to c
rows = df_tsne_cluster.loc[df_tsne_cluster['Class Name'] == c]
# Get majority value in Cluster column of the rows selected
cluster = rows.Cluster.mode().values[0]
# Populate mapping dictionary
class_clusters[c] = cluster
return class_clusters
classes = df_tsne['Class Name'].unique()
class_clusters = get_majority_cluster_per_group(df_tsne, classes)
class_clusters
{'sci.crypt': 1, 'sci.electronics': 3, 'sci.med': 2, 'sci.space': 0}
Получите большинство кластеров в каждой группе и посмотрите, сколько фактических членов этой группы находится в этом кластере.
# Convert the Cluster column to use the class name
class_by_id = {v: k for k, v in class_clusters.items()}
df_tsne['Predicted'] = df_tsne['Cluster'].map(class_by_id.__getitem__)
# Filter to the correctly matched rows
correct = df_tsne[df_tsne['Class Name'] == df_tsne['Predicted']]
# Summarise, as a percentage
acc = correct['Class Name'].value_counts() / SAMPLE_SIZE
acc
sci.space 0.966667 sci.med 0.960000 sci.electronics 0.953333 sci.crypt 0.926667 Name: Class Name, dtype: float64
# Get predicted values by name
df_tsne['Predicted'] = ''
for idx, rows in df_tsne.iterrows():
cluster = rows['Cluster']
# Get key from mapping based on cluster value
key = list(class_clusters.keys())[list(class_clusters.values()).index(cluster)]
df_tsne.at[idx, 'Predicted'] = key
df_tsne
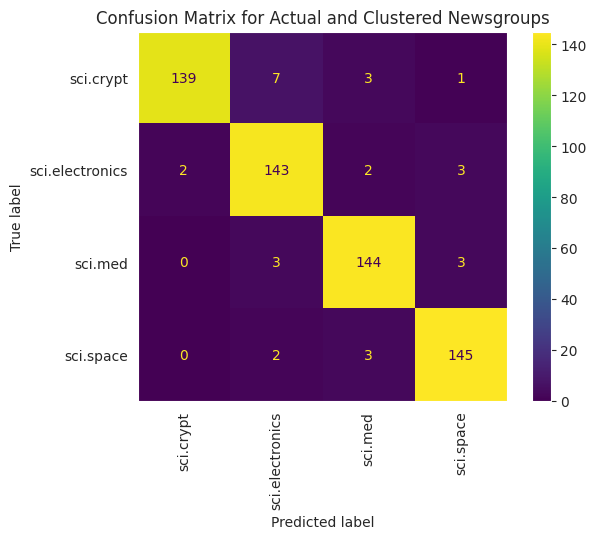
Чтобы лучше визуализировать производительность KMeans, примененного к вашим данным, вы можете использовать матрицу путаницы . Матрица путаницы позволяет оценить эффективность модели классификации за пределами точности. Вы можете увидеть, как классифицируются неправильно классифицированные точки. Вам понадобятся фактические значения и прогнозируемые значения, которые вы собрали в приведенном выше фрейме данных.
cm = confusion_matrix(df_tsne['Class Name'].to_list(), df_tsne['Predicted'].to_list())
disp = ConfusionMatrixDisplay(confusion_matrix=cm,
display_labels=classes)
disp.plot(xticks_rotation='vertical')
plt.title('Confusion Matrix for Actual and Clustered Newsgroups');
plt.grid(False)
Следующие шаги
Теперь вы создали собственную визуализацию вложений с помощью кластеризации! Попробуйте использовать собственные текстовые данные, чтобы визуализировать их как вложения. Вы можете выполнить уменьшение размерности, чтобы завершить этап визуализации. Обратите внимание, что TSNE хорошо справляется с кластеризацией входных данных, но сходимость может занять больше времени или может застрять на локальных минимумах. Если вы столкнулись с этой проблемой, вы можете рассмотреть еще один метод — анализ главных компонентов (PCA) .
Помимо KMeans существуют и другие алгоритмы кластеризации, такие как пространственная кластеризация на основе плотности (DBSCAN) .
Чтобы узнать, как использовать другие сервисы API Gemini, посетите краткое руководство по Python . Чтобы узнать больше о том, как можно использовать вложения, ознакомьтесь с доступными примерами . Чтобы узнать, как создавать их с нуля, см. учебник TensorFlow Word Embeddings .