
Model Terbuka Gemma
Serangkaian model open source yang ringan dan canggih, yang dibuat dari riset dan teknologi yang sama dengan yang digunakan untuk membuat model Gemini
Bertanggung jawab dari desain
Dengan menerapkan langkah-langkah keamanan yang komprehensif, model ini membantu memastikan solusi AI yang bertanggung jawab dan tepercaya melalui set data yang diseleksi dan penyesuaian yang ketat.
Performa yang tidak tertandingi dalam ukuran
Model Gemma mencapai hasil benchmark yang luar biasa pada ukuran 2 M, 7 M, 9 M, dan 27 M, bahkan mengungguli beberapa model terbuka yang lebih besar.
Deployment fleksibel
Men-deploy dengan lancar ke perangkat seluler, web, dan cloud menggunakan Keras, JAX, MediaPipe, PyTorch, Hugging Face, dan lainnya.
Coba Gemma 2
Gemma 2 didesain ulang untuk performa yang luar biasa dan efisiensi yang tak tertandingi, serta mengoptimalkan inferensi yang sangat cepat di berbagai hardware.
5 tembakan
MMLU
Tolok ukur MMLU adalah pengujian yang mengukur cakupan pengetahuan dan kemampuan pemecahan masalah yang diperoleh oleh model bahasa besar selama prapelatihan.
25 shot
ARC-C
Benchmark ARC-c adalah subset yang lebih terfokus dari set data ARC-e, yang hanya berisi pertanyaan yang salah dijawab oleh algoritma umum (ko-kejadian kata dan berbasis pengambilan).
5-shot
GSM8K
Benchmark GSM8K menguji kemampuan model bahasa untuk memecahkan masalah matematika tingkat sekolah dasar yang sering kali memerlukan beberapa langkah penalaran.
3-5-shot
AGIEval
Benchmark AGIEval menguji kecerdasan umum model bahasa menggunakan pertanyaan yang berasal dari ujian dunia nyata yang dirancang untuk menilai kemampuan intelektual manusia.
3-shot, CoT
BBH
Benchmark BBH (BIG-Bench Hard) berfokus pada tugas yang dianggap melampaui kemampuan model bahasa saat ini, yang menguji batasnya di berbagai domain penalaran dan pemahaman.
3-shot, F1
LEPASKAN
DROP adalah benchmark pemahaman membaca yang memerlukan penalaran terpisah atas paragraf.
5 tembakan
Winogrande
Benchmark Winogrande menguji kemampuan model bahasa untuk menyelesaikan tugas mengisi titik-titik yang ambigu dengan opsi biner, yang memerlukan penalaran akal sehat umum.
10-shot
HellaSwag
Benchmark HellaSwag menantang kemampuan model bahasa untuk memahami dan menerapkan penalaran akal sehat dengan memilih akhir cerita yang paling logis.
4-shot
MATH
MATH mengevaluasi kemampuan model bahasa untuk menyelesaikan soal cerita matematika yang kompleks, yang memerlukan penalaran, pemecahan masalah multilangkah, dan pemahaman konsep matematika.
0-shot
ARC-e
Benchmark ARC-e menguji keterampilan menjawab pertanyaan lanjutan model bahasa dengan pertanyaan sains pilihan ganda tingkat sekolah dasar yang asli.
0-shot
PIQA
Benchmark PIQA menguji kemampuan model bahasa untuk memahami dan menerapkan pengetahuan umum fisik dengan menjawab pertanyaan tentang interaksi fisik sehari-hari.
0-shot
SIQA
Tolok ukur SIQA mengevaluasi pemahaman model bahasa tentang interaksi sosial dan akal sehat sosial dengan mengajukan pertanyaan tentang tindakan orang dan implikasi sosialnya.
0-shot
Boolq
Benchmark BoolQ menguji kemampuan model bahasa untuk menjawab pertanyaan ya/tidak yang muncul secara alami, menguji kemampuan model untuk melakukan tugas inferensi bahasa alami di dunia nyata.
5-shot
TriviaQA
Tolok ukur TriviaQA menguji keterampilan pemahaman membaca dengan tiga pertanyaan-jawaban-bukti.
5-shot
NQ
Benchmark NQ (Natural Questions) menguji kemampuan model bahasa untuk menemukan dan memahami jawaban dalam seluruh artikel Wikipedia, yang menyimulasikan skenario menjawab pertanyaan di dunia nyata.
pass@1
HumanEval
Benchmark HumanEval menguji kemampuan pembuatan kode model bahasa dengan mengevaluasi apakah solusinya lulus pengujian unit fungsional untuk masalah pemrograman.
3-shot
MBPP
Benchmark MBPP menguji kemampuan model bahasa untuk menyelesaikan masalah pemrograman Python dasar, dengan berfokus pada konsep pemrograman dasar dan penggunaan library standar.
100%
75%
50%
25%
0%
100%
75%
50%
25%
0%
Gemma 1
2,5 M
Gemma 2
2,6 miliar
Mistral
7B
LLAMA 3
8B
Gemma 1
7B
Gemma 2
9 miliar
Gemma 2
27B
Gemma 1
2,5 M
Gemma 2
2,6 miliar
Mistral
7B
LLAMA 3
8B
Gemma 1
7B
Gemma 2
9 miliar
Gemma 2
27B
Gemma 1
2,5 M
Gemma 2
2,6 miliar
Mistral
7B
LLAMA 3
8B
Gemma 1
7B
Gemma 2
9 miliar
Gemma 2
27B
Gemma 1
2,5 M
Gemma 2
2,6 miliar
Mistral
7B
LLAMA 3
8B
Gemma 1
7B
Gemma 2
9 miliar
Gemma 2
27B
Gemma 1
2,5 M
Gemma 2
2,6 miliar
Mistral
7B
LLAMA 3
8B
Gemma 1
7B
Gemma 2
9 miliar
Gemma 2
27B
Gemma 1
2,5 M
Gemma 2
2,6 miliar
Mistral
7B
LLAMA 3
8B
Gemma 1
7B
Gemma 2
9 miliar
Gemma 2
27B
Gemma 1
2,5 M
Gemma 2
2,6 miliar
Mistral
7B
LLAMA 3
8B
Gemma 1
7B
Gemma 2
9 miliar
Gemma 2
27B
Gemma 1
2,5 M
Gemma 2
2,6 miliar
Mistral
7B
LLAMA 3
8B
Gemma 1
7B
Gemma 2
9 miliar
Gemma 2
27B
Gemma 1
2,5 M
Gemma 2
2,6 miliar
Mistral
7B
Gemma 1
7B
Gemma 2
9 miliar
Gemma 2
27B
Gemma 1
2,5 M
Gemma 2
2,6 miliar
Mistral
7B
Gemma 1
7B
Gemma 2
9 miliar
Gemma 2
27B
Gemma 1
2,5 M
Gemma 2
2,6 miliar
Mistral
7B
Gemma 1
7B
Gemma 2
9 miliar
Gemma 2
27B
Gemma 1
2,5 M
Gemma 2
2,6 miliar
Mistral
7B
Gemma 1
7B
Gemma 2
9 miliar
Gemma 2
27B
Gemma 1
2,5 M
Gemma 2
2,6 miliar
Mistral
7B
Gemma 1
7B
Gemma 2
9 miliar
Gemma 2
27B
Gemma 1
2,5 M
Gemma 2
2,6 miliar
Mistral
7B
Gemma 1
7B
Gemma 2
9 miliar
Gemma 2
27B
Gemma 1
2,5 M
Gemma 2
2,6 miliar
Mistral
7B
Gemma 1
7B
Gemma 2
9 miliar
Gemma 2
27B
Gemma 1
2,5 M
Gemma 2
2,6 miliar
Mistral
7B
Gemma 1
7B
Gemma 2
9 miliar
Gemma 2
27B
Gemma 1
2,5 M
Gemma 2
2,6 miliar
Mistral
7B
Gemma 1
7B
Gemma 2
9 miliar
Gemma 2
27B
*Ini adalah tolok ukur untuk model terlatih sebelumnya. Lihat laporan teknis untuk mengetahui detail performa dengan metodologi lainnya.
Model Riset
Menemukan rangkaian model Gemma yang diperluas
PaliGemma 2 Baru
Cakupan Gemma

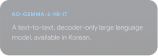

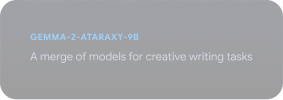
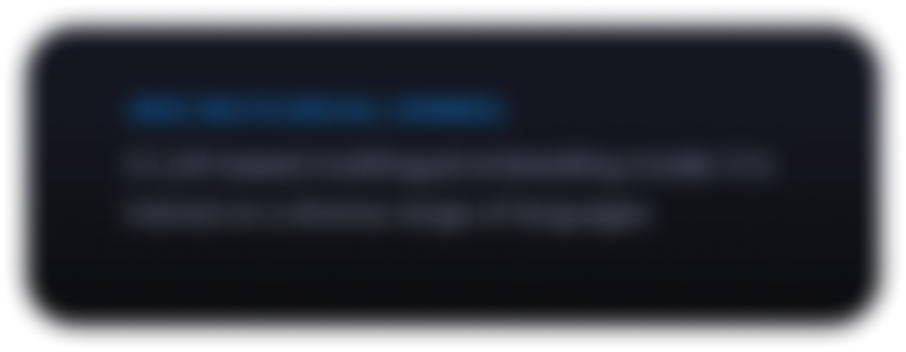
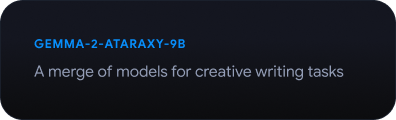

Jelajahi Gemmaverse
Ekosistem luas alat dan model Gemma buatan komunitas, siap mendukung dan menginspirasi inovasi Anda
Build
Mulai membangun dengan Gemma




Men-deploy model
Memilih target deployment
![]() Perangkat seluler
Perangkat seluler
Men-deploy di perangkat dengan Google AI Edge
Men-deploy langsung ke perangkat untuk fungsi offline dengan latensi rendah. Ideal untuk aplikasi yang memerlukan responsivitas dan privasi real-time, seperti aplikasi seluler, perangkat IoT, dan sistem tersemat.
![]() Web
Web
Mengintegrasikan dengan lancar ke dalam aplikasi web
Perkuat situs dan layanan web Anda dengan kemampuan AI tingkat lanjut, yang memungkinkan fitur interaktif, konten yang dipersonalisasi, dan otomatisasi cerdas.
![]() Cloud
Cloud
Menskalakan dengan mudah menggunakan infrastruktur cloud
Manfaatkan skalabilitas dan fleksibilitas cloud untuk menangani deployment berskala besar, workload yang menuntut, dan aplikasi AI yang kompleks.


Membuka komunikasi global
Ikuti kompetisi Kaggle global kami. Membuat varian model Gemma untuk bahasa tertentu atau aspek budaya yang unik