| | |  Посмотреть исходный код на GitHub Посмотреть исходный код на GitHub | |
В этой кодовой лаборатории показано, как создать индивидуальный классификатор текста с помощью эффективной настройки параметров (PET). Вместо точной настройки всей модели методы PET обновляют лишь небольшое количество параметров, что делает ее обучение относительно простым и быстрым. Это также позволяет модели легче освоить новое поведение при относительно небольшом объеме обучающих данных. Методология подробно описана в книге «На пути к гибким текстовым классификаторам для всех», где показано, как эти методы можно применять к различным задачам безопасности и достигать самых современных показателей с помощью всего лишь нескольких сотен обучающих примеров.
В этой лаборатории кода используется метод LoRA PET и меньшая модель Gemma ( gemma_instruct_2b_en ), поскольку ее можно запускать быстрее и эффективнее. Колаб охватывает этапы приема данных, их форматирования для LLM, тренировки весов LoRA и последующей оценки результатов. Эта лаборатория обучается на наборе данных ETHOS — общедоступном наборе данных для обнаружения разжигания ненависти, созданном на основе комментариев YouTube и Reddit. При обучении только на 200 примерах (1/4 набора данных) он достигает F1: 0,80 и ROC-AUC: 0,78, что немного выше значения SOTA, указанного в настоящее время в таблице лидеров (на момент написания статьи, 15 февраля 2024 г.). При обучении на полных 800 примерах он достигает оценки F1 83,74 и оценки ROC-AUC 88,17. Более крупные модели, такие как gemma_instruct_7b_en , обычно работают лучше, но затраты на обучение и выполнение также выше.
Предупреждение о триггере : поскольку эта кодовая лаборатория разрабатывает классификатор безопасности для обнаружения ненавистнических высказываний, примеры и оценка результатов содержат ужасные выражения.
Установка и настройка
Для этой лаборатории кода вам понадобится последняя версия keras (3), keras-nlp (0.8.0) и учетная запись Kaggle для загрузки модели Gemma.
import kagglehub
kagglehub.login()
pip install -q -U keras-nlppip install -q -U keras
import os
os.environ["KERAS_BACKEND"] = "tensorflow"
Загрузить набор данных ETHOS
В этом разделе вы загрузите набор данных для обучения нашего классификатора и предварительно обработаете его в обучающий и тестовый набор. Вы будете использовать популярный набор исследовательских данных ETHOS, который был собран для выявления разжигания ненависти в социальных сетях. Более подробную информацию о том, как собирался набор данных, можно найти в документе ETHOS: набор данных для обнаружения разжигания ненависти в Интернете .
import pandas as pd
gh_root = 'https://raw.githubusercontent.com'
gh_repo = 'intelligence-csd-auth-gr/Ethos-Hate-Speech-Dataset'
gh_path = 'master/ethos/ethos_data/Ethos_Dataset_Binary.csv'
data_url = f'{gh_root}/{gh_repo}/{gh_path}'
df = pd.read_csv(data_url, delimiter=';')
df['hateful'] = (df['isHate'] >= df['isHate'].median()).astype(int)
# Shuffle the dataset.
df = df.sample(frac=1, random_state=32)
# Split into train and test.
df_train, df_test = df[:800], df[800:]
# Display a sample of the data.
df.head(5)[['hateful', 'comment']]
Загрузите и создайте экземпляр модели
Как описано в документации , модель Gemma можно легко использовать разными способами. С Keras это то, что вам нужно сделать:
import keras
import keras_nlp
# For reproducibility purposes.
keras.utils.set_random_seed(1234)
# Download the model from Kaggle using Keras.
model = keras_nlp.models.GemmaCausalLM.from_preset('gemma_instruct_2b_en')
# Set the sequence length to a small enough value to fit in memory in Colab.
model.preprocessor.sequence_length = 128
model.generate('Question: what is the capital of France? ', max_length=32)
Предварительная обработка текста и токены-разделители
Чтобы помочь модели лучше понять наши намерения, вы можете предварительно обработать текст и использовать токены-разделители. Это снижает вероятность того, что модель создаст текст, не соответствующий ожидаемому формату. Например, вы можете попытаться запросить классификацию настроений из модели, написав такую подсказку:
Classify the following text into one of the following classes:[Positive,Negative]
Text: you look very nice today
Classification:
В этом случае модель может выводить, а может и не выдавать то, что вы ищете. Например, если текст содержит символы новой строки, это может отрицательно повлиять на производительность модели. Более надежный подход — использовать токены-разделители. Тогда приглашение будет выглядеть следующим образом:
Classify the following text into one of the following classes:[Positive,Negative]
<separator>
Text: you look very nice today
<separator>
Prediction:
Это можно абстрагировать с помощью функции, предварительно обрабатывающей текст:
def preprocess_text(
text: str,
labels: list[str],
instructions: str,
separator: str,
) -> str:
prompt = f'{instructions}:[{",".join(labels)}]'
return separator.join([prompt, f'Text:{text}', 'Prediction:'])
Теперь, если вы запустите функцию, используя ту же подсказку и текст, что и раньше, вы должны получить тот же результат:
text = 'you look very nice today'
prompt = preprocess_text(
text=text,
labels=['Positive', 'Negative'],
instructions='Classify the following text into one of the following classes',
separator='\n<separator>\n',
)
print(prompt)
Classify the following text into one of the following classes:[Positive,Negative] <separator> Text:you look very nice today <separator> Prediction:
Постобработка вывода
Выходными данными модели являются токены с различными вероятностями. Обычно для генерации текста вы выбираете несколько наиболее вероятных токенов и строите предложения, абзацы или даже полные документы. Однако для целей классификации на самом деле важно то, считает ли модель, что Positive более вероятно, чем Negative , или наоборот.
Учитывая модель, которую вы создали ранее, вы можете преобразовать ее выходные данные в независимые вероятности того, будет ли следующий токен Positive или Negative соответственно:
import numpy as np
def compute_output_probability(
model: keras_nlp.models.GemmaCausalLM,
prompt: str,
target_classes: list[str],
) -> dict[str, float]:
# Shorthands.
preprocessor = model.preprocessor
tokenizer = preprocessor.tokenizer
# NOTE: If a token is not found, it will be considered same as "<unk>".
token_unk = tokenizer.token_to_id('<unk>')
# Identify the token indices, which is the same as the ID for this tokenizer.
token_ids = [tokenizer.token_to_id(word) for word in target_classes]
# Throw an error if one of the classes maps to a token outside the vocabulary.
if any(token_id == token_unk for token_id in token_ids):
raise ValueError('One of the target classes is not in the vocabulary.')
# Preprocess the prompt in a single batch. This is done one sample at a time
# for illustration purposes, but it would be more efficient to batch prompts.
preprocessed = model.preprocessor.generate_preprocess([prompt])
# Identify output token offset.
padding_mask = preprocessed["padding_mask"]
token_offset = keras.ops.sum(padding_mask) - 1
# Score outputs, extract only the next token's logits.
vocab_logits = model.score(
token_ids=preprocessed["token_ids"],
padding_mask=padding_mask,
)[0][token_offset]
# Compute the relative probability of each of the requested tokens.
token_logits = [vocab_logits[ix] for ix in token_ids]
logits_tensor = keras.ops.convert_to_tensor(token_logits)
probabilities = keras.activations.softmax(logits_tensor)
return dict(zip(target_classes, probabilities.numpy()))
Вы можете протестировать эту функцию, запустив ее с помощью приглашения, которое вы создали ранее:
compute_output_probability(
model=model,
prompt=prompt,
target_classes=['Positive', 'Negative'],
)
{'Positive': 0.99994016, 'Negative': 5.984089e-05}
Обернув все это в классификатор
Для простоты использования вы можете объединить все только что созданные функции в один классификатор, подобный sklearn, с простыми в использовании и знакомыми функциями, такими как predict() и predict_score() .
import dataclasses
@dataclasses.dataclass(frozen=True)
class AgileClassifier:
"""Agile classifier to be wrapped around a LLM."""
# The classes whose probability will be predicted.
labels: tuple[str, ...]
# Provide default instructions and control tokens, can be overridden by user.
instructions: str = 'Classify the following text into one of the following classes'
separator_token: str = '<separator>'
end_of_text_token: str = '<eos>'
def encode_for_prediction(self, x_text: str) -> str:
return preprocess_text(
text=x_text,
labels=self.labels,
instructions=self.instructions,
separator=self.separator_token,
)
def encode_for_training(self, x_text: str, y: int) -> str:
return ''.join([
self.encode_for_prediction(x_text),
self.labels[y],
self.end_of_text_token,
])
def predict_score(
self,
model: keras_nlp.models.GemmaCausalLM,
x_text: str,
) -> list[float]:
prompt = self.encode_for_prediction(x_text)
token_probabilities = compute_output_probability(
model=model,
prompt=prompt,
target_classes=self.labels,
)
return [token_probabilities[token] for token in self.labels]
def predict(
self,
model: keras_nlp.models.GemmaCausalLM,
x_eval: str,
) -> int:
return np.argmax(self.predict_score(model, x_eval))
agile_classifier = AgileClassifier(labels=('Positive', 'Negative'))
Точная настройка модели
LoRA означает адаптацию низкого ранга. Это метод тонкой настройки, который можно использовать для эффективной настройки больших языковых моделей. Подробнее об этом можно прочитать в статье LoRA: Low-Rank Adaptation of Large Language Models .
Реализация Gemma в Keras предоставляет метод enable_lora() , который вы можете использовать для точной настройки:
# Enable LoRA for the model and set the LoRA rank to 4.
model.backbone.enable_lora(rank=4)
После включения LoRA вы можете начать процесс тонкой настройки. В Colab это занимает примерно 5 минут за эпоху:
import tensorflow as tf
# Create dataset with preprocessed text + labels.
map_fn = lambda x: agile_classifier.encode_for_training(*x)
x_train = list(map(map_fn, df_train[['comment', 'hateful']].values))
ds_train = tf.data.Dataset.from_tensor_slices(x_train).batch(2)
# Compile the model using the Adam optimizer and appropriate loss function.
model.compile(
loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer=keras.optimizers.Adam(learning_rate=0.0005),
weighted_metrics=[keras.metrics.SparseCategoricalAccuracy()],
)
# Begin training.
model.fit(ds_train, epochs=4)
Epoch 1/4 400/400 ━━━━━━━━━━━━━━━━━━━━ 354s 703ms/step - loss: 1.1365 - sparse_categorical_accuracy: 0.5874 Epoch 2/4 400/400 ━━━━━━━━━━━━━━━━━━━━ 338s 716ms/step - loss: 0.7579 - sparse_categorical_accuracy: 0.6662 Epoch 3/4 400/400 ━━━━━━━━━━━━━━━━━━━━ 324s 721ms/step - loss: 0.6818 - sparse_categorical_accuracy: 0.6894 Epoch 4/4 400/400 ━━━━━━━━━━━━━━━━━━━━ 323s 725ms/step - loss: 0.5922 - sparse_categorical_accuracy: 0.7220 <keras.src.callbacks.history.History at 0x7eb7e369c490>
Обучение на большее количество эпох приведет к более высокой точности, пока не произойдет переобучение.
Проверьте результаты
Теперь вы можете проверить выходные данные только что обученного гибкого классификатора. Этот код выведет прогнозируемую оценку класса по фрагменту текста:
text = 'you look really nice today'
scores = agile_classifier.predict_score(model, text)
dict(zip(agile_classifier.labels, scores))
{'Positive': 0.99899644, 'Negative': 0.0010035498}
Оценка модели
Наконец, вы оцените эффективность нашей модели, используя две общие метрики: оценку F1 и AUC-ROC . Оценка F1 фиксирует ложноотрицательные и ложноположительные ошибки путем оценки среднего гармонического значения точности и полноты при определенном пороге классификации. С другой стороны, AUC-ROC фиксирует компромисс между истинно положительными показателями и ложноположительными показателями при различных пороговых значениях и вычисляет площадь под этой кривой.
y_true = df_test['hateful'].values
# Compute the scores (aka probabilities) for each of the labels.
y_score = [agile_classifier.predict_score(model, x) for x in df_test['comment']]
# The label with highest score is considered the predicted class.
y_pred = np.argmax(y_score, axis=1)
# Extract the probability of a comment being considered hateful.
y_prob = [x[agile_classifier.labels.index('Negative')] for x in y_score]
from sklearn.metrics import f1_score, roc_auc_score
print(f'F1: {f1_score(y_true, y_pred):.2f}')
print(f'AUC-ROC: {roc_auc_score(y_true, y_prob):.2f}')
F1: 0.84 AUC-ROC: 0.88
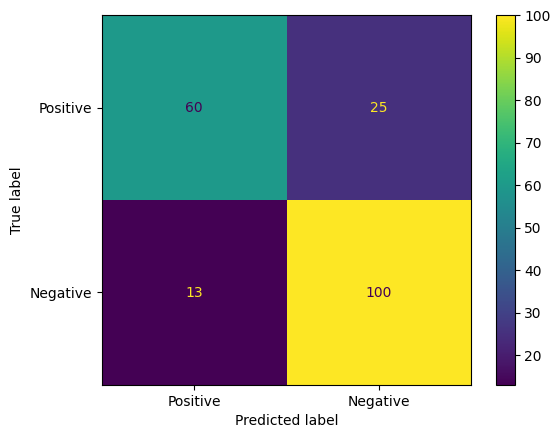
Еще одним интересным способом оценки прогнозов модели являются матрицы путаницы. Матрица путаницы визуально отобразит различные виды ошибок прогнозирования.
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
cm = confusion_matrix(y_true, y_pred)
ConfusionMatrixDisplay(
confusion_matrix=cm,
display_labels=agile_classifier.labels,
).plot()
<sklearn.metrics._plot.confusion_matrix.ConfusionMatrixDisplay at 0x7eb7e2d29ab0>
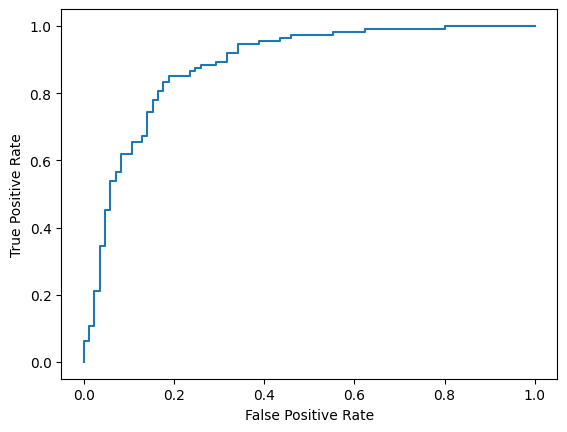
Наконец, вы также можете посмотреть на кривую ROC, чтобы получить представление о потенциальных ошибках прогнозирования при использовании различных порогов оценки.
from sklearn.metrics import RocCurveDisplay, roc_curve
fpr, tpr, _ = roc_curve(y_true, y_prob, pos_label=1)
RocCurveDisplay(fpr=fpr, tpr=tpr).plot()
<sklearn.metrics._plot.roc_curve.RocCurveDisplay at 0x7eb4d130ef20>
Приложение
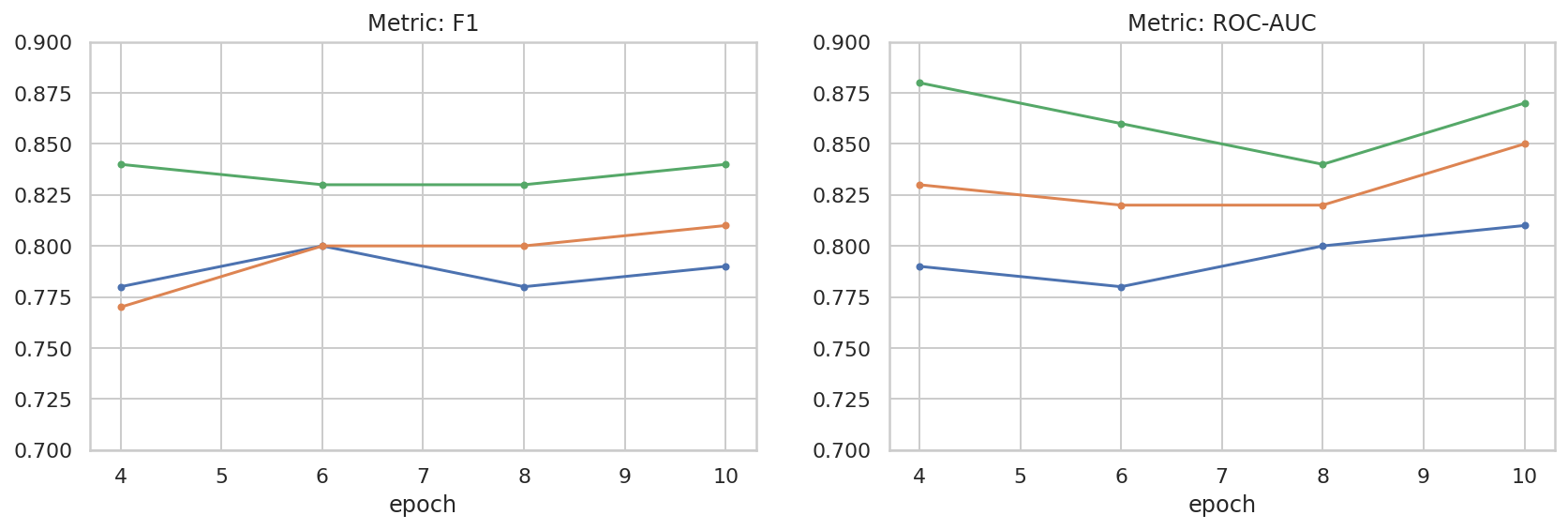
Мы провели базовое исследование пространства гиперпараметров, чтобы лучше понять взаимосвязь между размером набора данных и производительностью. Смотрите следующий сюжет.
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
sns.set_theme(style="whitegrid")
results_f1 = pd.DataFrame([
{'training_size': 800, 'epoch': 4, 'metric': 'f1', 'score': 0.84},
{'training_size': 800, 'epoch': 6, 'metric': 'f1', 'score': 0.83},
{'training_size': 800, 'epoch': 8, 'metric': 'f1', 'score': 0.83},
{'training_size': 800, 'epoch': 10, 'metric': 'f1', 'score': 0.84},
{'training_size': 400, 'epoch': 4, 'metric': 'f1', 'score': 0.77},
{'training_size': 400, 'epoch': 6, 'metric': 'f1', 'score': 0.80},
{'training_size': 400, 'epoch': 8, 'metric': 'f1', 'score': 0.80},
{'training_size': 400, 'epoch': 10,'metric': 'f1', 'score': 0.81},
{'training_size': 200, 'epoch': 4, 'metric': 'f1', 'score': 0.78},
{'training_size': 200, 'epoch': 6, 'metric': 'f1', 'score': 0.80},
{'training_size': 200, 'epoch': 8, 'metric': 'f1', 'score': 0.78},
{'training_size': 200, 'epoch': 10, 'metric': 'f1', 'score': 0.79},
])
results_roc_auc = pd.DataFrame([
{'training_size': 800, 'epoch': 4, 'metric': 'roc-auc', 'score': 0.88},
{'training_size': 800, 'epoch': 6, 'metric': 'roc-auc', 'score': 0.86},
{'training_size': 800, 'epoch': 8, 'metric': 'roc-auc', 'score': 0.84},
{'training_size': 800, 'epoch': 10, 'metric': 'roc-auc', 'score': 0.87},
{'training_size': 400, 'epoch': 4, 'metric': 'roc-auc', 'score': 0.83},
{'training_size': 400, 'epoch': 6, 'metric': 'roc-auc', 'score': 0.82},
{'training_size': 400, 'epoch': 8, 'metric': 'roc-auc', 'score': 0.82},
{'training_size': 400, 'epoch': 10,'metric': 'roc-auc', 'score': 0.85},
{'training_size': 200, 'epoch': 4, 'metric': 'roc-auc', 'score': 0.79},
{'training_size': 200, 'epoch': 6, 'metric': 'roc-auc', 'score': 0.78},
{'training_size': 200, 'epoch': 8, 'metric': 'roc-auc', 'score': 0.80},
{'training_size': 200, 'epoch': 10, 'metric': 'roc-auc', 'score': 0.81},
])
plot_opts = dict(style='.-', ylim=(0.7, 0.9))
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(14, 4))
process_results_df = lambda df: df.set_index('epoch').groupby('training_size')['score']
process_results_df(results_f1).plot(title='Metric: F1', ax=ax1, **plot_opts)
process_results_df(results_roc_auc).plot(title='Metric: ROC-AUC', ax=ax2, **plot_opts)
fig.show()