
Die Bearbeitung von Kundenanfragen, einschließlich E‑Mails, ist für viele Unternehmen unerlässlich, kann aber schnell überfordernd werden. Mit etwas Aufwand können KI-Modelle wie Gemma diese Arbeit erleichtern.
Jedes Unternehmen geht mit Anfragen wie E‑Mails etwas anders um. Daher ist es wichtig, Technologien wie generative KI an die Bedürfnisse Ihres Unternehmens anpassen zu können. In diesem Projekt geht es um das spezifische Problem, Bestellinformationen aus E-Mails an eine Bäckerei in strukturierte Daten zu extrahieren, damit sie schnell in ein Bestellbearbeitungssystem eingefügt werden können. Mit 10 bis 20 Beispielen für Anfragen und der gewünschten Ausgabe können Sie ein Gemma-Modell so abstimmen, dass es E‑Mails von Ihren Kunden verarbeitet, Ihnen hilft, schnell zu antworten, und sich in Ihre bestehenden Geschäftssysteme einbinden lässt. Dieses Projekt ist als KI-Anwendungsmuster konzipiert, das Sie erweitern und anpassen können, um Gemma-Modelle für Ihr Unternehmen zu nutzen.
Einen Videoüberblick über das Projekt und die Möglichkeiten zur Erweiterung, einschließlich der Erkenntnisse der Entwickler, finden Sie im Video Business Email AI Assistant Build with Google AI. Sie können sich den Code für dieses Projekt auch im Gemma Cookbook-Code-Repository ansehen. Andernfalls können Sie das Projekt mit der folgenden Anleitung erweitern.
Übersicht
In dieser Anleitung erfahren Sie, wie Sie eine mit Gemma, Python und Flask erstellte Anwendung für einen geschäftlichen E-Mail-Assistenten einrichten, ausführen und erweitern. Das Projekt bietet eine einfache Weboberfläche, die Sie an Ihre Bedürfnisse anpassen können. Die Anwendung wurde entwickelt, um Daten aus Kunden-E-Mails in eine Struktur für eine fiktive Bäckerei zu extrahieren. Sie können dieses Anwendungsmuster für jede geschäftliche Aufgabe verwenden, bei der Text als Eingabe und Ausgabe verwendet wird.
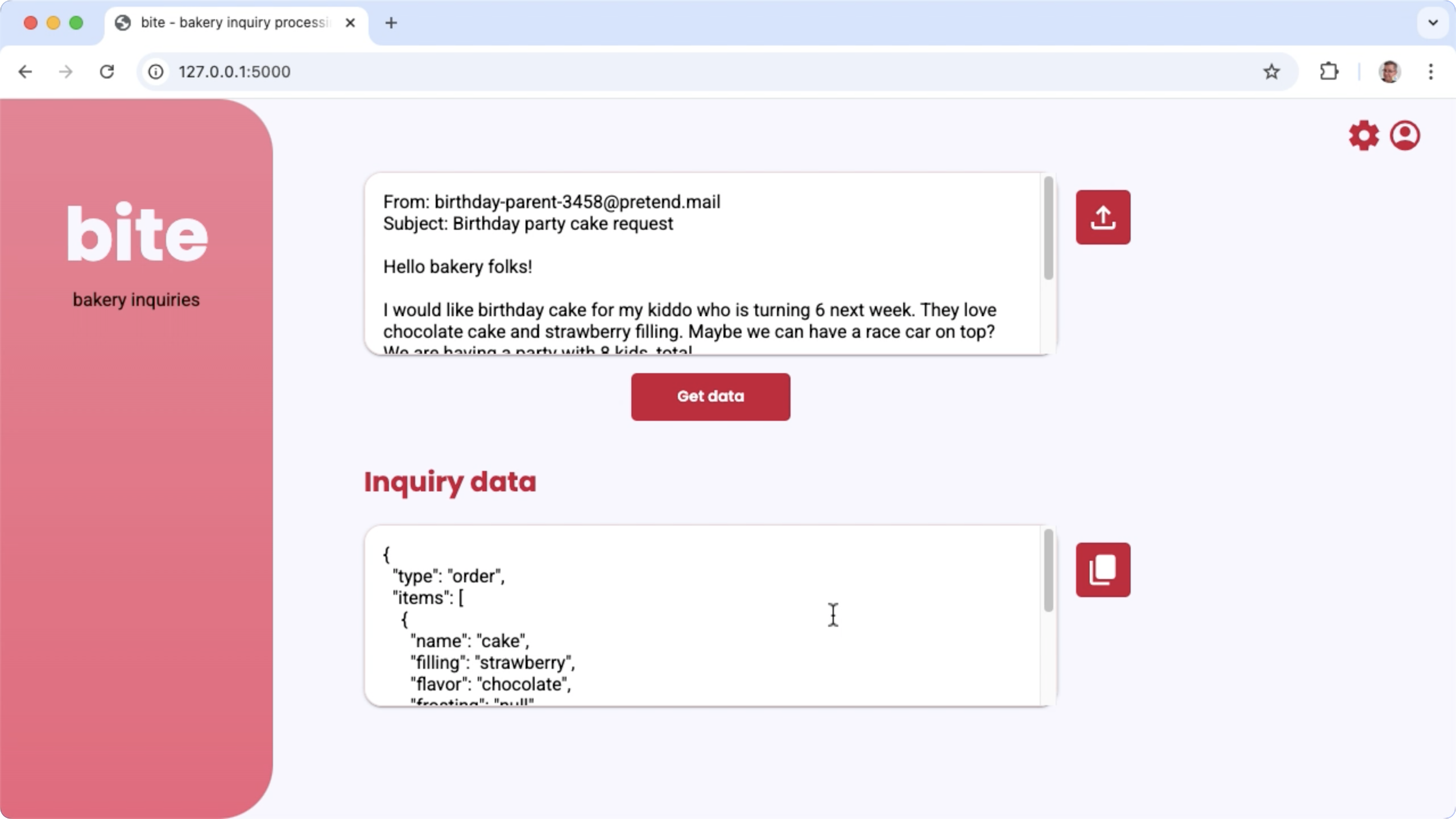
Abbildung 1. Projektoberfläche für die Bearbeitung von E‑Mail-Anfragen von Bäckereien
Hardwareanforderungen
Führen Sie diesen Optimierungsprozess auf einem Computer mit einer Graphics Processing Unit (GPU) oder einer Tensor Processing Unit (TPU) und ausreichend GPU- oder TPU-Arbeitsspeicher aus, um das vorhandene Modell und die Optimierungsdaten zu speichern. Um die Abstimmungskonfiguration in diesem Projekt auszuführen, benötigen Sie etwa 16 GB GPU-Arbeitsspeicher, etwa die gleiche Menge an regulärem RAM und mindestens 50 GB Speicherplatz.
Sie können den Teil dieser Anleitung zum Optimieren des Gemma-Modells in einer Colab-Umgebung mit einer T4-GPU-Laufzeit ausführen. Wenn Sie dieses Projekt auf einer VM-Instanz von Google Cloud erstellen, konfigurieren Sie die Instanz gemäß den folgenden Anforderungen:
- GPU-Hardware: Für die Ausführung dieses Projekts ist eine NVIDIA T4-GPU erforderlich (NVIDIA L4 oder höher empfohlen).
- Betriebssystem: Wählen Sie die Option Deep Learning unter Linux aus, insbesondere Deep Learning VM mit CUDA 12.3 M124 mit vorinstallierten GPU-Softwaretreibern.
- Größe des Bootlaufwerks: Stellen Sie mindestens 50 GB Speicherplatz für Ihre Daten, Modelle und unterstützende Software bereit.
Projekt einrichten
In dieser Anleitung erfahren Sie, wie Sie dieses Projekt für die Entwicklung und das Testen vorbereiten. Die allgemeinen Einrichtungsschritte umfassen die Installation der erforderlichen Software, das Klonen des Projekts aus dem Code-Repository, das Festlegen einiger Umgebungsvariablen, die Installation von Python-Bibliotheken und das Testen der Webanwendung.
Installieren und konfigurieren
In diesem Projekt werden Python 3 und virtuelle Umgebungen (venv) verwendet, um Pakete zu verwalten und die Anwendung auszuführen. Die folgende Installationsanleitung gilt für einen Linux-Hostcomputer.
So installieren Sie die erforderliche Software:
Installieren Sie Python 3 und das Paket für virtuelle Umgebungen
venvfür Python:sudo apt update sudo apt install git pip python3-venv
Projekt klonen
Laden Sie den Projektcode auf Ihren Entwicklercomputer herunter. Sie benötigen die git-Quellcodeverwaltungssoftware, um den Projektquellcode abzurufen.
So laden Sie den Projektcode herunter:
Klonen Sie das Git-Repository mit dem folgenden Befehl:
git clone https://github.com/google-gemini/gemma-cookbook.gitKonfigurieren Sie optional Ihr lokales Git-Repository für die Verwendung von Sparse Checkout, damit Sie nur die Dateien für das Projekt haben:
cd gemma-cookbook/ git sparse-checkout set Demos/business-email-assistant/ git sparse-checkout init --cone
Python-Bibliotheken installieren
Installieren Sie die Python-Bibliotheken mit aktivierter venv virtuellen Python-Umgebung, um Python-Pakete und ‑Abhängigkeiten zu verwalten. Achten Sie darauf, dass Sie die virtuelle Python-Umgebung vor der Installation von Python-Bibliotheken mit dem pip-Installationsprogramm aktivieren. Weitere Informationen zur Verwendung virtueller Python-Umgebungen finden Sie in der Python-venv-Dokumentation.
So installieren Sie die Python-Bibliotheken:
Wechseln Sie in einem Terminalfenster zum Verzeichnis
business-email-assistant:cd Demos/business-email-assistant/Konfigurieren und aktivieren Sie die virtuelle Python-Umgebung (venv) für dieses Projekt:
python3 -m venv venv source venv/bin/activateInstallieren Sie die erforderlichen Python-Bibliotheken für dieses Projekt mit dem Skript
setup_python:./setup_python.sh
Umgebungsvariablen festlegen
Für dieses Projekt sind einige Umgebungsvariablen erforderlich, darunter ein Kaggle-Nutzername und ein Kaggle API-Token. Sie benötigen ein Kaggle-Konto und müssen Zugriff auf die Gemma-Modelle anfordern, um sie herunterladen zu können. Für dieses Projekt fügen Sie Ihren Kaggle-Nutzername und Ihr Kaggle-API-Token in zwei .env-Dateien ein, die von der Webanwendung bzw. dem Optimierungsprogramm gelesen werden.
So legen Sie die Umgebungsvariablen fest:
- Rufen Sie Ihren Kaggle-Nutzernamen und Ihren Tokenschlüssel ab, indem Sie der Anleitung in der Kaggle-Dokumentation folgen.
- Folgen Sie der Anleitung unter Zugriff auf Gemma erhalten auf der Seite Gemma einrichten, um Zugriff auf das Gemma-Modell zu erhalten.
- Erstellen Sie Umgebungsvariablendateien für das Projekt, indem Sie an jedem dieser Speicherorte in Ihrem Klon des Projekts eine Textdatei
.enverstellen:email-processing-webapp/.env model-tuning/.env
Fügen Sie nach dem Erstellen der Textdateien
.envdie folgenden Einstellungen in beide Dateien ein:KAGGLE_USERNAME=<YOUR_KAGGLE_USERNAME_HERE> KAGGLE_KEY=<YOUR_KAGGLE_KEY_HERE>
Anwendung ausführen und testen
Nachdem Sie das Projekt installiert und konfiguriert haben, führen Sie die Webanwendung aus, um zu prüfen, ob Sie sie richtig konfiguriert haben. Das sollten Sie als Ausgangspunkt tun, bevor Sie das Projekt für Ihre eigenen Zwecke bearbeiten.
So führen Sie das Projekt aus und testen es:
Wechseln Sie in einem Terminalfenster zum Verzeichnis
email-processing-webapp:cd business-email-assistant/email-processing-webapp/Führen Sie die Anwendung mit dem Skript
run_appaus:./run_app.shNach dem Start der Webanwendung wird im Programmcode eine URL aufgeführt, über die Sie die Anwendung aufrufen und testen können. Normalerweise ist diese Adresse:
http://127.0.0.1:5000/Klicken Sie in der Weboberfläche unter dem ersten Eingabefeld auf die Schaltfläche Daten abrufen, um eine Antwort vom Modell generieren zu lassen.
Die erste Antwort des Modells nach dem Ausführen der Anwendung dauert länger, da bei der ersten Generierung Initialisierungsschritte ausgeführt werden müssen. Nachfolgende Aufforderungsanfragen und die Generierung in einer bereits laufenden Webanwendung werden in kürzerer Zeit abgeschlossen.
Anwendung erweitern
Sobald die Anwendung ausgeführt wird, können Sie sie erweitern, indem Sie die Benutzeroberfläche und die Geschäftslogik so anpassen, dass sie für Aufgaben funktioniert, die für Sie oder Ihr Unternehmen relevant sind. Sie können das Verhalten des Gemma-Modells auch über den Anwendungscode ändern, indem Sie die Komponenten des Prompts ändern, die die App an das generative KI-Modell sendet.
Die Anwendung stellt dem Modell zusammen mit den Eingabedaten des Nutzers einen vollständigen Prompt zur Verfügung. Sie können diese Anweisungen ändern, um das Verhalten des Modells anzupassen, z. B. indem Sie die Namen der Parameter und die Struktur des zu generierenden JSON angeben. Eine einfachere Möglichkeit, das Verhalten des Modells zu ändern, besteht darin, zusätzliche Anweisungen oder Richtlinien für die Antwort des Modells zu geben, z. B. dass die generierten Antworten keine Markdown-Formatierung enthalten sollen.
So ändern Sie Prompt-Anweisungen:
- Öffnen Sie im Entwicklungsprojekt die Codedatei
business-email-assistant/email-processing-webapp/app.py. Fügen Sie im
app.py-Code zusätzliche Anweisungen zur Funktionget_prompt():hinzu:def get_prompt(): return """ Extract the relevant details of this request and return them in JSON code, with no additional markdown formatting:\n"""
In diesem Beispiel wird der Anleitung der Satz „ohne zusätzliche Markdown-Formatierung“ hinzugefügt.
Zusätzliche Prompts können den generierten Output stark beeinflussen und sind mit deutlich weniger Aufwand umzusetzen. Sie sollten diese Methode zuerst ausprobieren, um zu sehen, ob Sie das gewünschte Verhalten des Modells erreichen können. Die Verwendung von Prompts zur Änderung des Verhaltens eines Gemma-Modells hat jedoch ihre Grenzen. Insbesondere das allgemeine Limit für Eingabetokens des Modells, das für Gemma 2 bei 8.192 Tokens liegt, erfordert, dass Sie detaillierte Prompts mit der Größe der neuen Daten, die Sie bereitstellen, in Einklang bringen, damit Sie dieses Limit nicht überschreiten.
Modell abstimmen
Die Feinabstimmung eines Gemma-Modells ist die empfohlene Methode, um zuverlässigere Antworten für bestimmte Aufgaben zu erhalten. Wenn das Modell beispielsweise JSON mit einer bestimmten Struktur generieren soll, einschließlich bestimmter benannter Parameter, sollten Sie das Modell entsprechend abstimmen. Je nach Aufgabe, die das Modell ausführen soll, können Sie mit 10 bis 20 Beispielen grundlegende Funktionen erreichen. In diesem Abschnitt der Anleitung wird beschrieben, wie Sie das Feinabstimmungstraining für ein Gemma-Modell für eine bestimmte Aufgabe einrichten und ausführen.
In der folgenden Anleitung wird beschrieben, wie Sie den Feinabstimmungsvorgang in einer VM-Umgebung ausführen. Sie können diesen Vorgang aber auch mit dem zugehörigen Colab-Notebook für dieses Projekt ausführen.
Hardwareanforderungen
Die Rechenanforderungen für die Feinabstimmung sind dieselben wie die Hardwareanforderungen für den Rest des Projekts. Sie können den Optimierungsvorgang in einer Colab-Umgebung mit einer T4-GPU-Laufzeit ausführen, wenn Sie die Eingabetokens auf 256 und die Batchgröße auf 1 beschränken.
Daten vorbereiten
Bevor Sie mit dem Abstimmen eines Gemma-Modells beginnen, müssen Sie Daten für die Abstimmung vorbereiten. Wenn Sie ein Modell für eine bestimmte Aufgabe abstimmen, benötigen Sie eine Reihe von Beispielen für Anfragen und Antworten. Diese Beispiele sollten den Anfragetext ohne Anweisungen und den erwarteten Antworttext enthalten. Zuerst sollten Sie ein Dataset mit etwa 10 Beispielen vorbereiten. Diese Beispiele sollten eine Vielzahl von Anfragen und die idealen Antworten darstellen. Achten Sie darauf, dass die Anfragen und Antworten nicht repetitiv sind, da dies dazu führen kann, dass die Antworten der Modelle repetitiv sind und sich nicht angemessen an Variationen in den Anfragen anpassen. Wenn Sie das Modell so abstimmen, dass es ein strukturiertes Datenformat ausgibt, müssen alle bereitgestellten Antworten dem gewünschten Datenausgabeformat entsprechen. Die folgende Tabelle enthält einige Beispieldatensätze aus dem Dataset dieses Codebeispiels:
| Anfrage | Antwort |
|---|---|
| Hallo Indian Bakery Central,\nhaben Sie zufällig 10 Pendas und 30 Bundi Ladoos auf Lager? Verkaufen Sie auch Kuchen mit Vanille- und Schokoladengeschmack? Ich suche nach einer Größe von 6 Zoll. | { "type": "inquiry", "items": [ { "name": "pendas", "quantity": 10 }, { "name": "bundi ladoos", "quantity": 30 }, { "name": "cake", "filling": null, "frosting": "vanilla", "flavor": "chocolate", "size": "6 in" } ] } |
| Ich habe Ihr Unternehmen auf Google Maps gesehen. Verkaufen Sie Jalebi und Gulab Jamun? | { "type": "inquiry", "items": [ { "name": "jellabi", "quantity": null }, { "name": "gulab jamun", "quantity": null } ] } |
Tabelle 1. Teilliste des Abstimmungsdatasets für den Extraktor für E-Mail-Daten der Bäckerei.
Datenformat und ‑laden
Sie können Ihre Trainingsdaten in einem beliebigen Format speichern, z. B. als Datenbankdatensätze, JSON-Dateien, CSV- oder Nur-Text-Dateien, solange Sie die Datensätze mit Python-Code abrufen können. In diesem Projekt werden JSON-Dateien aus dem Verzeichnis data in ein Array von Dictionary-Objekten eingelesen.
In diesem Beispiel-Abstimmungsprogramm wird das Abstimmungs-Dataset im Modul model-tuning/main.py mit der Funktion prepare_tuning_dataset() geladen:
def prepare_tuning_dataset():
# collect data from JSON files
prompt_data = read_json_files_to_dicts("./data")
...
Wie bereits erwähnt, können Sie das Dataset in einem beliebigen Format speichern, solange Sie die Anfragen mit den zugehörigen Antworten abrufen und in einen Textstring umwandeln können, der als Tuning-Datensatz verwendet wird.
Abstimmungsdatensätze zusammenstellen
Für den eigentlichen Optimierungsprozess wird jede Anfrage und Antwort in einem einzelnen String mit den Prompts und dem Inhalt der Antwort zusammengefasst. Das Tuning-Programm tokenisiert den String dann für die Verwendung durch das Modell. Den Code zum Erstellen eines Abstimmungsdatensatzes finden Sie in der Funktion prepare_tuning_dataset() des Moduls model-tuning/main.py:
def prepare_tuning_dataset():
...
# prepare data for tuning
tuning_dataset = []
template = "{instruction}\n{response}"
for prompt in prompt_data:
tuning_dataset.append(template.format(instruction=prompt["prompt"],
response=prompt["response"]))
return tuning_dataset
Diese Funktion verwendet die Daten als Eingabe und formatiert sie, indem sie zwischen der Anweisung und der Antwort einen Zeilenumbruch einfügt.
Modellgewichtungen generieren
Sobald die Optimierungsdaten vorhanden sind und geladen werden, können Sie das Optimierungsprogramm ausführen. Beim Abstimmungsprozess für diese Beispielanwendung wird die Keras NLP-Bibliothek verwendet, um das Modell mit der Low-Rank Adaptation- oder LoRA-Technik abzustimmen und neue Modellgewichte zu generieren. Im Vergleich zur Feinabstimmung mit voller Präzision ist die Verwendung von LoRA deutlich speichereffizienter, da die Änderungen an den Modellgewichten angenähert werden. Sie können diese geschätzten Gewichte dann auf die vorhandenen Modellgewichte legen, um das Verhalten des Modells zu ändern.
So führen Sie den Abstimmungslauf aus und berechnen neue Gewichte:
Wechseln Sie in einem Terminalfenster zum Verzeichnis
model-tuning/.cd business-email-assistant/model-tuning/Führen Sie den Optimierungsprozess mit dem Skript
tune_modelaus:./tune_model.sh
Der Optimierungsprozess dauert je nach verfügbaren Rechenressourcen einige Minuten. Wenn das Programm erfolgreich abgeschlossen wurde, werden neue *.h5-Gewichtsdateien im Verzeichnis model-tuning/weights im folgenden Format geschrieben:
gemma2-2b_inquiry_tuned_4_epoch##.lora.h5
Fehlerbehebung
Wenn die Optimierung nicht erfolgreich abgeschlossen wird, gibt es zwei wahrscheinliche Gründe:
- Nicht genügend Arbeitsspeicher oder Ressourcen erschöpft: Diese Fehler treten auf, wenn beim Optimierungsprozess Arbeitsspeicher angefordert wird, der den verfügbaren GPU- oder CPU-Arbeitsspeicher überschreitet. Achten Sie darauf, dass die Webanwendung nicht ausgeführt wird, während der Optimierungsprozess läuft. Wenn Sie auf einem Gerät mit 16 GB GPU-Arbeitsspeicher abstimmen, muss
token_limitauf 256 undbatch_sizeauf 1 festgelegt sein. - GPU-Treiber nicht installiert oder nicht mit JAX kompatibel: Für den Optimierungsprozess müssen auf dem Rechengerät Hardwaretreiber installiert sein, die mit der Version der JAX-Bibliotheken kompatibel sind. Weitere Informationen finden Sie in der Dokumentation zur JAX-Installation.
Abgestimmtes Modell bereitstellen
Beim Optimierungsprozess werden mehrere Gewichte basierend auf den Optimierungsdaten und der Gesamtzahl der Epochen generiert, die in der Optimierungsanwendung festgelegt sind. Standardmäßig werden im Rahmen des Abstimmungsprogramms drei Modelldateien mit Gewichten generiert, eine für jede Abstimmungsepoche. Mit jeder Tuning-Epoche werden Gewichte erzeugt, die die Ergebnisse der Tuning-Daten genauer wiedergeben. Die Genauigkeitsraten für die einzelnen Epochen sehen Sie in der Terminalausgabe des Optimierungsprozesses, wie unten dargestellt:
...
8/8 ━━━━━━━━━━━━━━━━━━━━ 121s 195ms/step - loss: 0.5432 - sparse_categorical_accuracy: 0.5982
Epoch 2/3
8/8 ━━━━━━━━━━━━━━━━━━━━ 2s 194ms/step - loss: 0.3320 - sparse_categorical_accuracy: 0.6966
Epoch 3/3
8/8 ━━━━━━━━━━━━━━━━━━━━ 2s 192ms/step - loss: 0.2135 - sparse_categorical_accuracy: 0.7848
Die Genauigkeitsrate sollte relativ hoch sein, etwa 0,80. Sie sollte aber nicht zu hoch oder sehr nahe an 1,00 liegen, da dies bedeutet, dass die Gewichte die Abstimmungsdaten fast überangepasst haben. In diesem Fall schneidet das Modell bei Anfragen, die sich deutlich von den Tuning-Beispielen unterscheiden, nicht gut ab. Standardmäßig werden im Bereitstellungsskript die Gewichte für Epoche 3 ausgewählt, die in der Regel eine Genauigkeitsrate von etwa 0, 80 haben.
So stellen Sie die generierten Gewichte in der Webanwendung bereit:
Wechseln Sie in einem Terminalfenster zum Verzeichnis
model-tuning:cd business-email-assistant/model-tuning/Führen Sie den Optimierungsprozess mit dem Skript
deploy_weightsaus:./deploy_weights.sh
Nachdem Sie dieses Skript ausgeführt haben, sollte im Verzeichnis email-processing-webapp/weights/ eine neue Datei namens *.h5 angezeigt werden.
Neues Modell testen
Nachdem Sie die neuen Gewichte in der Anwendung bereitgestellt haben, ist es an der Zeit, das neu abgestimmte Modell auszuprobieren. Dazu müssen Sie die Webanwendung noch einmal ausführen und eine Antwort generieren.
So führen Sie das Projekt aus und testen es:
Wechseln Sie in einem Terminalfenster zum Verzeichnis
email-processing-webapp:cd business-email-assistant/email-processing-webapp/Führen Sie die Anwendung mit dem Skript
run_appaus:./run_app.shNach dem Start der Webanwendung wird im Programmcode eine URL aufgeführt, unter der Sie die Anwendung aufrufen und testen können. In der Regel lautet diese Adresse:
http://127.0.0.1:5000/Klicken Sie in der Weboberfläche unter dem ersten Eingabefeld auf die Schaltfläche Daten abrufen, um eine Antwort vom Modell generieren zu lassen.
Sie haben jetzt ein Gemma-Modell in einer Anwendung optimiert und bereitgestellt. Experimentieren Sie mit der Anwendung und versuchen Sie, die Grenzen der Generierungsfähigkeit des optimierten Modells für Ihre Aufgabe zu ermitteln. Wenn Sie Szenarien finden, in denen das Modell keine gute Leistung erbringt, sollten Sie einige dieser Anfragen in Ihre Liste mit Beispieldaten für das Fine-Tuning aufnehmen. Fügen Sie dazu die Anfrage hinzu und geben Sie eine ideale Antwort an. Wiederholen Sie dann den Optimierungsprozess, stellen Sie die neuen Gewichte noch einmal bereit und testen Sie die Ausgabe.
Zusätzliche Ressourcen
Weitere Informationen zu diesem Projekt finden Sie im Gemma Cookbook-Code-Repository. Wenn Sie Hilfe beim Erstellen der Anwendung benötigen oder mit anderen Entwicklern zusammenarbeiten möchten, können Sie den Discord-Server der Google Developers Community besuchen. Weitere Build with Google AI-Projekte findest du in der Videoplaylist.