Imagen ist das High-Fidelity-Modell zur Bildgenerierung von Google, mit dem sich realistische und hochwertige Bilder aus Text-Prompts generieren lassen. Alle generierten Bilder enthalten ein SynthID-Wasserzeichen. Weitere Informationen zu den verfügbaren Imagen-Modellvarianten finden Sie im Abschnitt Modellversionen.
Bilder mit den Imagen-Modellen generieren
In diesem Beispiel wird gezeigt, wie Sie Bilder mit einem Imagen-Modell generieren:
Python
from google import genai
from google.genai import types
from PIL import Image
from io import BytesIO
client = genai.Client()
response = client.models.generate_images(
model='imagen-4.0-generate-001',
prompt='Robot holding a red skateboard',
config=types.GenerateImagesConfig(
number_of_images= 4,
)
)
for generated_image in response.generated_images:
generated_image.image.show()
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const response = await ai.models.generateImages({
model: 'imagen-4.0-generate-001',
prompt: 'Robot holding a red skateboard',
config: {
numberOfImages: 4,
},
});
let idx = 1;
for (const generatedImage of response.generatedImages) {
let imgBytes = generatedImage.image.imageBytes;
const buffer = Buffer.from(imgBytes, "base64");
fs.writeFileSync(`imagen-${idx}.png`, buffer);
idx++;
}
}
main();
Ok
package main
import (
"context"
"fmt"
"os"
"google.golang.org/genai"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
config := &genai.GenerateImagesConfig{
NumberOfImages: 4,
}
response, _ := client.Models.GenerateImages(
ctx,
"imagen-4.0-generate-001",
"Robot holding a red skateboard",
config,
)
for n, image := range response.GeneratedImages {
fname := fmt.Sprintf("imagen-%d.png", n)
_ = os.WriteFile(fname, image.Image.ImageBytes, 0644)
}
}
REST
curl -X POST \
"https://generativelanguage.googleapis.com/v1beta/models/imagen-4.0-generate-001:predict" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"instances": [
{
"prompt": "Robot holding a red skateboard"
}
],
"parameters": {
"sampleCount": 4
}
}'

Imagen-Konfiguration
Imagen unterstützt derzeit nur Prompts in englischer Sprache und die folgenden Parameter:
numberOfImages: Die Anzahl der zu generierenden Bilder, von 1 bis 4 (einschließlich). Der Standardwert ist 4.imageSize: Die Größe des generierten Bildes. Dies wird nur für die Modelle „Standard“ und „Ultra“ unterstützt. Die unterstützten Werte sind1Kund2K. Der Standardwert ist1K.aspectRatio: Ändert das Seitenverhältnis des generierten Bildes. Unterstützte Werte sind"1:1","3:4","4:3","9:16"und"16:9". Der Standardwert ist"1:1".personGeneration: Das Modell darf Bilder von Personen generieren. Folgende Werte werden unterstützt:"dont_allow": Generierung von Bildern von Personen blockieren."allow_adult": Bilder von Erwachsenen, aber nicht von Kindern generieren. Das ist die Standardeinstellung."allow_all": Bilder generieren, die Erwachsene und Kinder enthalten.
Imagen-Prompt-Anleitung
In diesem Abschnitt des Imagen-Leitfadens erfahren Sie, wie sich durch Ändern einer Text-zu-Bild-Eingabeaufforderung unterschiedliche Ergebnisse erzielen lassen. Außerdem finden Sie Beispiele für Bilder, die Sie erstellen können.
Grundlagen zum Schreiben von Prompts
Ein guter Prompt ist beschreibend und klar und verwendet aussagekräftige Keywords und Modifikatoren. Beginnen Sie mit dem Motiv, dem Kontext und dem Stil.

Thema: Das Erste, woran Sie bei jeder Eingabeaufforderung denken müssen, ist das Motiv. Das Objekt, eine Person, ein Tier oder eine Landschaft, von der Sie ein Bild möchten.
Kontext und Hintergrund: Ebenso wichtig ist der Hintergrund oder Kontext, in dem das Motiv platziert wird. Platzieren Sie das Motiv vor verschiedenen Hintergründen. Zum Beispiel ein Studio mit weißem Hintergrund, im Freien oder in Gebäuden.
Stil: Fügen Sie abschließend den Stil des gewünschten Bildes hinzu. Stile können allgemein (Malerei, Fotografie, Skizzen) oder sehr spezifisch sein (Pastel, Kohlezeichnung, isometrische 3D-Perspektive). Sie können auch Stile kombinieren.
Nachdem Sie eine erste Version Ihres Prompts geschrieben haben, können Sie ihn verfeinern, indem Sie weitere Details hinzufügen, bis Sie das gewünschte Bild erhalten. Iteration ist wichtig. Beginnen Sie mit Ihrer Kernidee und verfeinern und erweitern Sie diese dann, bis das generierte Bild Ihrer Vision entspricht.

|

|

|
Imagen-Modelle können Ihre Ideen in detaillierte Bilder umwandeln, unabhängig davon, ob Ihre Prompts kurz oder lang und detailliert sind. Verfeinern Sie Ihre Vision durch iterative Prompts und fügen Sie Details hinzu, bis Sie das perfekte Ergebnis erzielen.
|
Mit kurzen Prompts können Sie schnell ein Bild generieren. 
|
Mit längeren Prompts können Sie spezifische Details hinzufügen und Ihr Bild erstellen. 
|
Zusätzliche Tipps zum Verfassen von Prompts für Imagen:
- Beschreibende Sprache verwenden: Verwenden Sie detaillierte Adjektive und Adverbien, um Imagen ein klares Bild zu vermitteln.
- Kontext angeben: Fügen Sie bei Bedarf Hintergrundinformationen hinzu, damit die KI den Prompt besser versteht.
- Auf bestimmte Künstler oder Stile verweisen: Wenn Sie eine bestimmte Ästhetik im Sinn haben, kann es hilfreich sein, auf bestimmte Künstler oder Kunstrichtungen zu verweisen.
- Tools für Prompt Engineering verwenden: Sie können Tools oder Ressourcen für Prompt Engineering nutzen, um Ihre Prompts zu optimieren und optimale Ergebnisse zu erzielen.
- Gesichtsdetails in Ihren persönlichen Fotos und Gruppenfotos optimieren: Geben Sie Gesichtsdetails als Fokus des Fotos an (z. B. mit dem Wort „Porträt“ im Prompt).
Text in Bildern generieren
Imagen-Modelle können Text in Bilder einfügen und so mehr kreative Möglichkeiten für die Bildgenerierung eröffnen. Mit den folgenden Tipps können Sie diese Funktion optimal nutzen:
- Sicher iterieren: Möglicherweise müssen Sie Bilder mehrmals neu generieren, bis Sie das gewünschte Ergebnis erhalten. Die Textintegration von Imagen wird ständig weiterentwickelt. Manchmal sind mehrere Versuche erforderlich, um die besten Ergebnisse zu erzielen.
- Kurz fassen: Der Text sollte maximal 25 Zeichen umfassen, damit er optimal generiert werden kann.
Mehrere Formulierungen: Testen Sie zwei oder drei unterschiedliche Formulierungen, um zusätzliche Informationen bereitzustellen. Verwenden Sie nicht mehr als drei Begriffe, um die Komposition übersichtlicher zu gestalten.

Prompt: Ein Poster mit dem Text „Summerland“ in fetter Schrift als Titel. Darunter befindet sich der Slogan „Summer never felt so good“ (Der Sommer hat sich noch nie so gut angefühlt). Platzierung von Anleitungen: Imagen kann versuchen, Text wie angegeben zu positionieren, aber es kann zu Abweichungen kommen. Diese Funktion wird kontinuierlich verbessert.
Schriftstil für Inspiration: Geben Sie einen allgemeinen Schriftstil an, um die Auswahl von Imagen subtil zu beeinflussen. Verlassen Sie sich nicht auf eine genaue Schriftartreplikation, sondern rechnen Sie mit kreativen Interpretationen.
Schriftgröße: Geben Sie eine Schriftgröße oder eine allgemeine Größenangabe (z. B. klein, mittel, groß) an, um die Generierung der Schriftgröße zu beeinflussen.
Prompt-Parametrisierung
Um die Ausgaberesultate besser zu steuern, kann es hilfreich sein, die Eingaben in Imagen zu parametrisieren. Angenommen, Sie möchten, dass Ihre Kunden Logos für ihr Unternehmen generieren können, und Sie möchten sicherstellen, dass Logos immer auf einem einfarbigen Hintergrund generiert werden. Außerdem möchten Sie die Optionen einschränken, die der Kunde in einem Menü auswählen kann.
In diesem Beispiel können Sie einen parametrisierten Prompt ähnlich dem folgenden erstellen:
A {logo_style} logo for a {company_area} company on a solid color background. Include the text {company_name}.In Ihrer benutzerdefinierten Benutzeroberfläche kann der Kunde die Parameter über ein Menü eingeben. Der ausgewählte Wert wird dann in den Prompt eingefügt, den Imagen erhält.
Beispiel:
Prompt:
A minimalist logo for a health care company on a solid color background. Include the text Journey.
Prompt:
A modern logo for a software company on a solid color background. Include the text Silo.
Prompt:
A traditional logo for a baking company on a solid color background. Include the text Seed.
Erweiterte Techniken zum Schreiben von Eingabeaufforderungen
Anhand der folgenden Beispiele können Sie anhand von Attributen wie Bilddeskriptoren, Formen und Materialien, historischen Kunstbewegungen und Bildqualitätsmodifikatoren spezifischere Prompts erstellen.
Fotografie
- Eingabeaufforderung enthält: „Ein Foto von...”
Um diesen Stil zu verwenden, beginnen Sie mit der Verwendung von Keywords, die Imagen klar mitteilen, dass Sie nach einem Foto suchen. Starten Sie die Eingabeaufforderungen mit „Ein Foto von. . .”. Beispiel:

|

|

|
Bildquelle: Jedes Bild wurde mit dem entsprechenden Text-Prompt mit dem Imagen 4-Modell generiert.
Fotografische Modifikatotionen
In den folgenden Beispielen sehen Sie mehrere fotospezifische Modifikatoren und Parameter. Sie können mehrere Modifikatoren kombinieren, um eine genauere Steuerung zu erreichen.
Kameranähe: aus der Nähe, von weit weg

Eingabeaufforderung: Ein Foto von Kaffeebohnen aus der Nähe 
Eingabeaufforderung: Ein herausgezoomtes Foto eines kleinen Beutels mit
Kaffeebohnen in einer unaufgeräumten KücheKameraposition: Luftaufnahme, von unten

Eingabeaufforderung: Luftaufnahme einer Stadt mit Wolkenkratzern 
Eingabeaufforderung: Ein Foto eines Waldstamms mit blauem Himmel von unten Beleuchtung: natürlich, dramatisch, warm, kalt

Prompt: Studiofoto eines modernen Sessels, natürliche Beleuchtung 
Eingabeaufforderung: Studiofoto eines modernen Sessels, dramatische Beleuchtung Kameraeinstellungen: Bewegungsunschärfe, Weichzeichnung, Bokeh, Hochformat

Prompt: Foto einer Stadt mit Wolkenkratzern aus dem Inneren eines Autos mit Bewegungsunschärfe 
Prompt: Weichzeichnung eines Fotos einer Brücke in einer Stadt bei Nacht Objektive: 35 mm, 50 mm, Fischauge, Weitwinkel, Makro

Eingabeaufforderung: Foto eines Blattes, Makroobjektiv 
Eingabeaufforderung: Straßenansicht, New York City, Fischaugenobjektiv Filmtypen: Schwarz-Weiß, Polaroid

Prompt: Ein Polaroid-Hochformatbild eines Hundes mit Sonnenbrille 
Eingabeaufforderung: Schwarz-Weiß-Foto eines Hundes mit Sonnenbrille
Bildquelle: Jedes Bild wurde mit dem entsprechenden Text-Prompt mit dem Imagen 4-Modell generiert.
Illustration und Kunst
- Eingabeaufforderung enthält: „Eine painting von...”, „Eine sketch von...”
Die Stile variieren von monochromen Stilen wie Bleistift bis hin zu hyperrealistischer digitaler Kunst. Die folgenden Bilder verwenden beispielsweise dieselbe Eingabeaufforderung mit unterschiedlichen Stilen:
„Eine [art style or creation technique] einer kantigen elektrischen Limousine mit Wolkenkratzern im Hintergrund“

|

|

|

|

|

|
Bildquelle: Jedes Bild wurde mit dem Imagen 2-Modell über den entsprechenden Text-Prompt generiert.
Formen und Materialien
- Eingabeaufforderung: „...aus...”, „...in Form von...”
Eine der Stärken dieser Technologie ist, dass Sie Bilder erstellen können, die andernfalls schwer oder unmöglich wären. Sie können beispielsweise Ihr Firmenlogo in verschiedenen Materialien und Texturen neu erstellen.

|

|

|
Bildquelle: Jedes Bild wurde mit dem entsprechenden Text-Prompt mit dem Imagen 4-Modell generiert.
Bezüge auf historische Kunst
- Eingabeaufforderung: „...im Stil von...”
Bestimmte Stile haben sich im Laufe der Jahre zu einem Mythos entwickelt. Im Folgenden finden Sie einige Ideen für historische Gemälde oder Kunststile, die Sie ausprobieren können.
„Erstelle ein Bild im Stil von [art period or movement] : ein Windpark“

|

|

|
Bildquelle: Jedes Bild wurde mit dem entsprechenden Text-Prompt mit dem Imagen 4-Modell generiert.
Modifikatoren für die Bildqualität
Bestimmte Keywords können dem Modell mitteilen, dass Sie nach einem qualitativ hochwertigen Bild suchen. Beispiele für Qualitätsmodifikatoren:
- Allgemeine Modifikatoren: hohe Qualität, ansprechend, stilisiert
- Fotos: 4K, HDR, Studiofoto
- Kunst, Illustration: von einem Profi, detailliert
Im Folgenden finden Sie einige Beispiele für Eingabeaufforderungen ohne Qualitätsmodifikatoren und die gleiche Aufforderung mit Qualitätsmodifikatoren.

|

Foto eines Getreidehalms von einem Profi-Fotografen aufgenommen |
Bildquelle: Jedes Bild wurde mit dem entsprechenden Text-Prompt mit dem Imagen 4-Modell generiert.
Seitenverhältnisse
Mit der Imagen-Bildgenerierung können Sie fünf verschiedene Bild-Seitenverhältnisse festlegen.
- Quadrat (1:1, Standard) - Ein quadratisches Standardfoto. Typische Anwendungsfälle für dieses Seitenverhältnis sind Beiträge in sozialen Medien.
Vollbild (4:3) - Dieses Seitenverhältnis wird häufig in Medien oder in Filmen verwendet. Es bezeichnet auch die Abmessungen der meisten alten (Nicht-Breitbild-)Fernseher und Mittelformatkameras. Es erfasst horizontal mehr von der Szene (im Vergleich zu 1:1), dadurch gehört es zu den bevorzugten Seitenverhältnissen für die Fotografie.

Prompt: Nahaufnahme der Finger eines Musikers, der Klavier spielt, Schwarz-Weiß-Film, Vintage (Seitenverhältnis 4:3) 
Prompt: Ein professionelles Studiofoto von Pommes Frites für ein High-End-Restaurant im Stil einer Lebensmittelzeitschrift (Seitenverhältnis 4:3). Vollbild-Vollbild (3:4) – Dies ist das um 90 Grad gedrehte Vollbild-Seitenverhältnis. So kann vertikal im Vergleich zum Seitenverhältnis 1:1 mehr von der Szene erfasst werden.

Prompt: Eine Frau wandert, Nahaufnahme ihrer Stiefel, die sich in einer Pfütze spiegeln, große Berge im Hintergrund, im Stil einer Werbung, dramatische Blickwinkel (Seitenverhältnis 3:4) 
Prompt: Luftaufnahme eines Flusses, der in einem mystischen Tal fließt (Seitenverhältnis 3:4) Breitbild (16:9): Dieses Seitenverhältnis hat 4:3 ersetzt und ist heute das gängigste Seitenverhältnis für Fernseher, Monitore und Bildschirme von Smartphones (Querformat). Verwenden Sie dieses Seitenverhältnis, wenn Sie mehr vom Hintergrund erfassen möchten (z. B. malerische Landschaften).

Prompt: Ein Mann ganz in weißer Kleidung, der am Strand sitzt, Nahaufnahme, Lichtverhältnisse einer goldenen Stunde (Seitenverhältnis 16:9) Hochformat (9:16): Dieses Seitenverhältnis entspricht dem Breitbild, aber gedreht. Dabei handelt es sich um ein relativ neues Seitenverhältnis, das in Kurzvideo-Apps beliebt ist (z. B. YouTube Shorts). Verwenden Sie es für hohe Objekte mit stark vertikalen Ausrichtungen wie Gebäude, Bäume, Wasserfälle oder ähnliche Objekte.

Prompt: ein digitales Rendering eines riesigen Wolkenkratzers, modern, groß, monumental, mit einem schönen Sonnenuntergang im Hintergrund (Seitenverhältnis 9:16)
Fotorealistische Bilder
Verschiedene Versionen des Bildgenerierungsmodells können eine Mischung aus künstlerischer und fotorealistischer Ausgabe bieten. Verwenden Sie die folgende Formulierung in Prompts, um je nach dem zu generierenden Thema eine fotorealistischere Ausgabe zu generieren.
| Anwendungsfall | Linsentyp | Brennweiten | Weitere Informationen |
|---|---|---|---|
| Personen (Hochformat) | Prime, Zoom | 24-35mm | Schwarz-Weiß-Film, Film Noir, Tiefenschärfe, Duotone (erwähnt zwei Farben) |
| Essen, Insekten, Pflanzen (Objekte, Stilleben) | Makro | 60-105mm | Hohe Details, präzise Fokussierung, kontrollierte Beleuchtung |
| Sport, Tiere (Bewegung) | Telefotozoom | 100-400mm | Schnelle Belichtungszeit, Aktions- oder Bewegungsverfolgung |
| Astronomisch, Landschaft (Weitwinkel) | Weitwinkel | 10-24mm | Langzeitbelichtung, scharfe Fokussierung, Langzeitbelichtung, glattes Wasser oder Wolken |
Porträts
| Anwendungsfall | Linsentyp | Brennweiten | Weitere Informationen |
|---|---|---|---|
| Personen (Hochformat) | Prime, Zoom | 24-35mm | Schwarz-Weiß-Film, Film Noir, Tiefenschärfe, Duotone (erwähnt zwei Farben) |
Mit mehreren Suchbegriffen aus der Tabelle kann Imagen die folgenden Porträts generieren:

|

|

|

|
Prompt: Eine Frau, 35 mm Hochformat, blaue und graue Duotones
Modell: imagen-4.0-generate-001

|

|

|

|
Eingabeaufforderung: Eine Frau, 35 mm Hochformat, Film Noir
Modell: imagen-4.0-generate-001
Objekte
| Anwendungsfall | Linsentyp | Brennweiten | Weitere Informationen |
|---|---|---|---|
| Essen, Insekten, Pflanzen (Objekte, Stilleben) | Makro | 60-105mm | Hohe Details, präzise Fokussierung, kontrollierte Beleuchtung |
Mit mehreren Suchbegriffen aus der Tabelle kann Imagen die folgenden Objektbilder generieren:

|

|

|

|
Eingabeaufforderung: Blatt einer Gebetspflanze, Makroobjektiv, 60 mm
Modell: imagen-4.0-generate-001

|

|

|

|
Eingabeaufforderung: Eine Nudelplatte, 100-mm-Makroobjektiv
Modell: imagen-4.0-generate-001
Bewegung
| Anwendungsfall | Linsentyp | Brennweiten | Weitere Informationen |
|---|---|---|---|
| Sport, Tiere (Bewegung) | Telefotozoom | 100-400mm | Schnelle Belichtungszeit, Aktions- oder Bewegungsverfolgung |
Mit mehreren Suchbegriffen aus der Tabelle kann Imagen die folgenden Bewegungsbilder generieren:

|

|
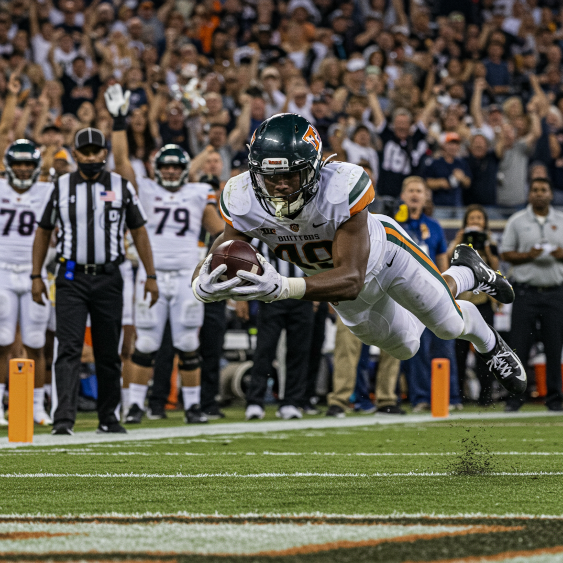
|

|
Prompt: Ein erfolgreicher Touchdown, schnelle Belichtungszeit, Bewegungsverfolgung
Modell: imagen-4.0-generate-001

|

|

|

|
Eingabeaufforderung: Ein Reh läuft im Wald, schnelle Belichtungszeit, Bewegungsverfolgung
Modell: imagen-4.0-generate-001
Weitwinkel
| Anwendungsfall | Linsentyp | Brennweiten | Weitere Informationen |
|---|---|---|---|
| Astronomisch, Landschaft (Weitwinkel) | Weitwinkel | 10-24mm | Langzeitbelichtung, scharfe Fokussierung, Langzeitbelichtung, glattes Wasser oder Wolken |
Mit mehreren Suchbegriffen aus der Tabelle kann Imagen die folgenden Weitwinkelbilder generieren:

|

|

|

|
Eingabeaufforderung: Großer Bergbereich, Querwinkel 10 mm
Modell: imagen-4.0-generate-001

|

|

|

|
Prompt: ein Foto des Mondes, Astrofotografie, Weitwinkel 10 mm
Modell: imagen-4.0-generate-001
Modellversionen
Imagen 4
| Attribut | Beschreibung |
|---|---|
| Modellcode |
Gemini API
|
| Unterstützte Datentypen |
Eingabe Text Ausgabe Bilder |
| Token-Limits[*] |
Eingabetokenlimit 480 Tokens (Text) Ausgabe von Bildern 1 bis 4 (Ultra/Standard/Schnell) |
| Letzte Aktualisierung | Juni 2025 |
Imagen 3
Das Imagen 3-Modell wurde eingestellt.