
Lidar com consultas de clientes, incluindo e-mails, é uma parte necessária da administração de muitas empresas, mas pode ficar rapidamente complicado. Com um pouco de esforço, os modelos de inteligência artificial (IA) como o Gemma podem facilitar esse trabalho.
Cada empresa lida com consultas, como e-mails, de maneira um pouco diferente. Por isso, é importante adaptar tecnologias como a IA generativa às necessidades do seu negócio. Este projeto aborda o problema específico de extrair informações de pedidos de e-mails para uma padaria e transformá-las em dados estruturados, para que possam ser adicionadas rapidamente a um sistema de processamento de pedidos. Usando de 10 a 20 exemplos de consultas e a saída desejada, você pode ajustar um modelo Gemma para processar e-mails dos seus clientes, ajudar você a responder rapidamente e se integrar aos seus sistemas comerciais atuais. Ele foi criado como um padrão de aplicativo de IA que pode ser estendido e adaptado para gerar valor com os modelos da Gemma para sua empresa.
Para uma visão geral em vídeo do projeto e como estendê-lo, incluindo insights das pessoas que o criaram, confira o vídeo Assistente de IA para e-mails comerciais Crie com a IA do Google. Você também pode analisar o código deste projeto no repositório de código do Gemma Cookbook. Caso contrário, comece a estender o projeto usando as instruções a seguir.
Visão geral
Neste tutorial, você vai aprender a configurar, executar e estender um aplicativo assistente de e-mail comercial criado com Gemma, Python e Flask. O projeto fornece uma interface básica de usuário da Web que pode ser modificada para atender às suas necessidades. O aplicativo foi criado para extrair dados de e-mails de clientes em uma estrutura para uma padaria fictícia. É possível usar esse padrão de aplicativo para qualquer tarefa comercial que use entrada e saída de texto.
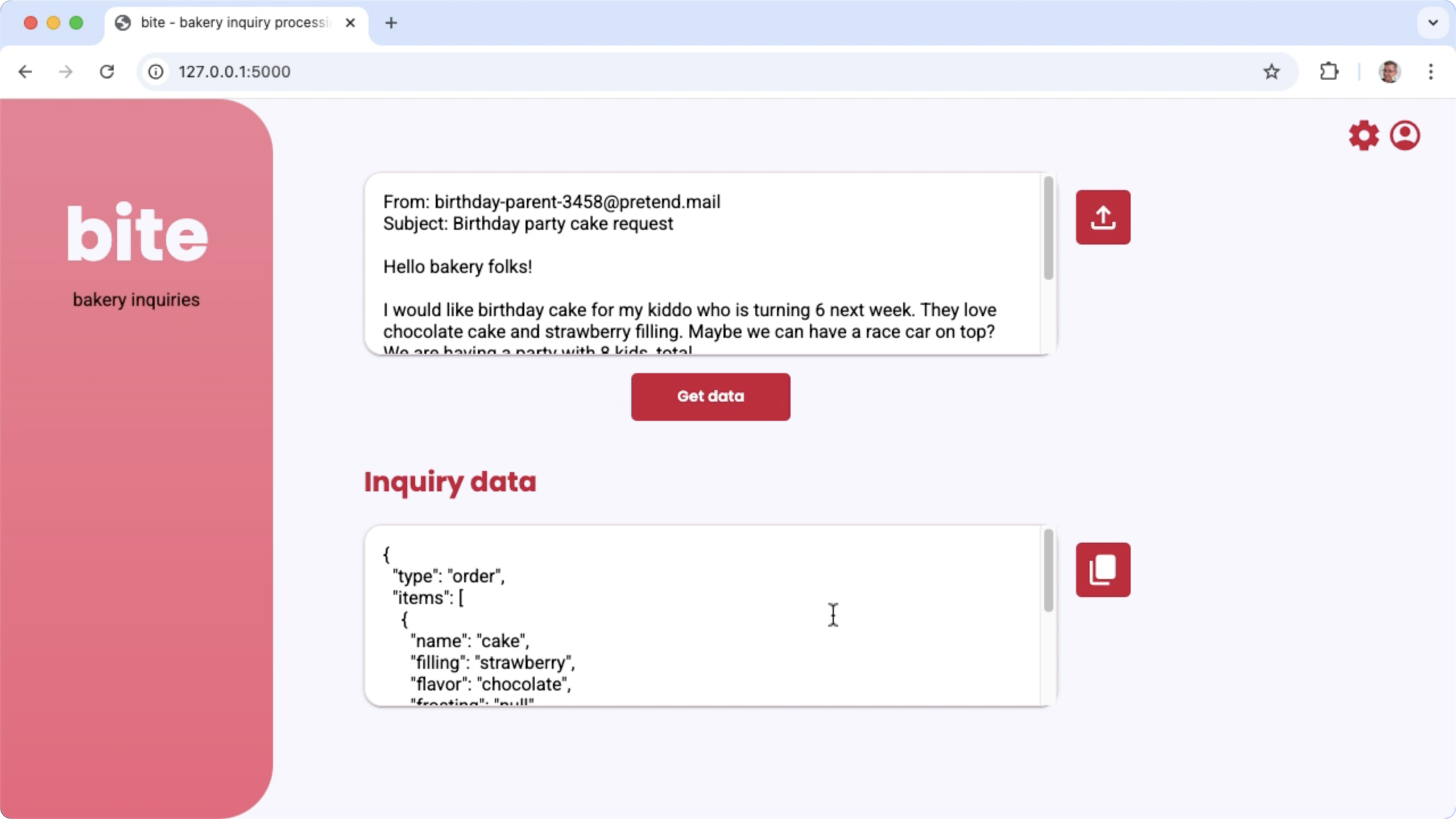
Figura 1. Interface do usuário do projeto para processar consultas por e-mail da padaria
Requisitos de hardware
Execute esse processo de ajuste em um computador com uma unidade de processamento gráfico (GPU) ou uma unidade de processamento de tensor (TPU) e memória de GPU ou TPU suficiente para armazenar o modelo atual e os dados de ajuste. Para executar a configuração de ajuste neste projeto, você precisa de cerca de 16 GB de memória da GPU, aproximadamente a mesma quantidade de RAM normal e um mínimo de 50 GB de espaço em disco.
Você pode executar a parte de ajuste do modelo Gemma deste tutorial usando um ambiente do Colab com um tempo de execução de GPU T4. Se você estiver criando este projeto em uma instância de VM do Google Cloud, configure a instância seguindo estes requisitos:
- Hardware de GPU: uma NVIDIA T4 é necessária para executar este projeto (recomenda-se NVIDIA L4 ou superior).
- Sistema operacional: escolha uma opção de Aprendizado profundo no Linux, especificamente VM de aprendizado profundo com CUDA 12.3 M124 com drivers de software de GPU pré-instalados.
- Tamanho do disco de inicialização: provisione pelo menos 50 GB de espaço em disco para seus dados, modelos e software de suporte.
Configurar o projeto
Estas instruções mostram como preparar o projeto para desenvolvimento e testes. As etapas gerais de configuração incluem a instalação do software de pré-requisito, a clonagem do projeto do repositório de código, a definição de algumas variáveis de ambiente, a instalação de bibliotecas Python e o teste do aplicativo da Web.
Instalar e configurar
Este projeto usa o Python 3 e ambientes virtuais (venv) para gerenciar pacotes
e executar o aplicativo. As instruções de instalação a seguir são para uma máquina host Linux.
Para instalar o software necessário:
Instale o Python 3 e o pacote de ambiente virtual
venvpara Python:sudo apt update sudo apt install git pip python3-venv
Clonar o projeto
Faça o download do código do projeto para o computador de desenvolvimento. Você precisa do software de controle de origem git para recuperar o código-fonte do projeto.
Para fazer o download do código do projeto:
Clone o repositório git usando o comando a seguir:
git clone https://github.com/google-gemini/gemma-cookbook.gitSe quiser, configure seu repositório git local para usar o sparse checkout, assim você terá apenas os arquivos do projeto:
cd gemma-cookbook/ git sparse-checkout set Demos/business-email-assistant/ git sparse-checkout init --cone
Instalar bibliotecas Python
Instale as bibliotecas Python com o ambiente virtual venv ativado para gerenciar pacotes e dependências do Python. Ative o ambiente virtual do Python antes de instalar as bibliotecas do Python com o instalador pip. Para mais informações sobre como usar ambientes virtuais do Python, consulte a documentação do
venv do Python.
Para instalar as bibliotecas Python:
Em uma janela de terminal, navegue até o diretório
business-email-assistant:cd Demos/business-email-assistant/Configure e ative o ambiente virtual Python (venv) para este projeto:
python3 -m venv venv source venv/bin/activateInstale as bibliotecas necessárias do Python para este projeto usando o script
setup_python:./setup_python.sh
Defina as variáveis de ambiente
Esse projeto exige algumas variáveis de ambiente para ser executado, incluindo um nome de usuário e um token da API do Kaggle. Você precisa ter uma conta do Kaggle e solicitar acesso aos modelos Gemma para fazer o download deles. Para
este projeto, adicione seu nome de usuário e token da API do Kaggle a dois arquivos .env, que são lidos pelo aplicativo da Web e pelo programa de ajuste,
respectivamente.
Para definir as variáveis de ambiente:
- Siga as instruções na documentação do Kaggle para conseguir seu nome de usuário e a chave do token.
- Siga as instruções em Acessar o Gemma na página Configuração do Gemma para ter acesso ao modelo.
- Crie arquivos de variáveis de ambiente para o projeto. Para isso, crie um arquivo de texto
.envem cada um destes locais no clone do projeto:email-processing-webapp/.env model-tuning/.env
Depois de criar os arquivos de texto
.env, adicione as seguintes configurações aos dois arquivos:KAGGLE_USERNAME=<YOUR_KAGGLE_USERNAME_HERE> KAGGLE_KEY=<YOUR_KAGGLE_KEY_HERE>
executar e testar o aplicativo
Depois de concluir a instalação e a configuração do projeto, execute o aplicativo da Web para confirmar se você o configurou corretamente. Faça isso como uma verificação de linha de base antes de editar o projeto para seu próprio uso.
Para executar e testar o projeto:
Em uma janela de terminal, navegue até o diretório
email-processing-webapp:cd business-email-assistant/email-processing-webapp/Execute o aplicativo usando o script
run_app:./run_app.shDepois de iniciar o aplicativo da Web, o código do programa lista um URL em que é possível navegar e testar. Normalmente, esse endereço é:
http://127.0.0.1:5000/Na interface da Web, pressione o botão Receber dados abaixo do primeiro campo de entrada para gerar uma resposta do modelo.
A primeira resposta do modelo depois que você executa o aplicativo leva mais tempo porque precisa concluir as etapas de inicialização na primeira execução da geração. As solicitações e gerações de comandos subsequentes em um aplicativo da Web já em execução são concluídas em menos tempo.
Estender o aplicativo
Depois que o aplicativo estiver em execução, você poderá estendê-lo modificando a interface do usuário e a lógica de negócios para que ele funcione em tarefas relevantes para você ou sua empresa. Também é possível modificar o comportamento do modelo Gemma usando o código do aplicativo ao mudar os componentes do comando que o app envia para o modelo de IA generativa.
O aplicativo fornece instruções ao modelo junto com os dados de entrada do usuário, um comando completo do modelo. É possível modificar essas instruções para mudar o comportamento do modelo, como especificar os nomes dos parâmetros e a estrutura do JSON a ser gerado. Uma maneira mais simples de mudar o comportamento do modelo é fornecer mais instruções ou orientações para a resposta dele, como especificar que as respostas geradas não devem incluir formatação Markdown.
Para modificar as instruções do comando:
- No projeto de desenvolvimento, abra o arquivo de código
business-email-assistant/email-processing-webapp/app.py. No código
app.py, adicione instruções de adição à funçãoget_prompt()::def get_prompt(): return """ Extract the relevant details of this request and return them in JSON code, with no additional markdown formatting:\n"""
Este exemplo adiciona a frase "sem formatação Markdown adicional" às instruções.
Fornecer mais instruções para o comando pode influenciar muito a saída gerada e exige muito menos esforço para ser implementado. Tente esse método primeiro para ver se você consegue o comportamento desejado do modelo. No entanto, o uso de instruções de comando para modificar o comportamento de um modelo da Gemma tem limites. Em particular, o limite geral de tokens de entrada do modelo, que é de 8.192 tokens para o Gemma 2, exige que você equilibre instruções detalhadas de comandos com o tamanho dos novos dados fornecidos para ficar abaixo desse limite.
Ajustar o modelo
O ajuste de um modelo Gemma é a maneira recomendada de fazer com que ele responda de forma mais confiável para tarefas específicas. Em particular, se você quiser que o modelo gere JSON com uma estrutura específica, incluindo parâmetros com nomes específicos, considere ajustar o modelo para esse comportamento. Dependendo da tarefa que você quer que o modelo conclua, é possível alcançar uma funcionalidade básica com 10 a 20 exemplos. Esta seção do tutorial explica como configurar e executar o ajuste fino em um modelo da Gemma para uma tarefa específica.
As instruções a seguir explicam como realizar a operação de ajuste fino em um ambiente de VM. No entanto, também é possível fazer isso usando o notebook do Colab associado a este projeto.
Requisitos de hardware
Os requisitos de computação para ajuste fino são os mesmos dos requisitos de hardware para o restante do projeto. É possível executar a operação de ajuste em um ambiente do Colab com um tempo de execução de GPU T4 se você limitar os tokens de entrada a 256 e o tamanho do lote a 1.
Preparar dados
Antes de começar a ajustar um modelo da Gemma, é necessário preparar os dados para o ajuste. Ao ajustar um modelo para uma tarefa específica, você precisa de um conjunto de exemplos de solicitação e resposta. Esses exemplos devem mostrar o texto da solicitação, sem instruções, e o texto da resposta esperada. Para começar, prepare um conjunto de dados com cerca de 10 exemplos. Esses exemplos precisam representar uma variedade completa de solicitações e as respostas ideais. Verifique se as solicitações e respostas não são repetitivas, já que isso pode fazer com que as respostas dos modelos sejam repetitivas e não se ajustem adequadamente às variações nas solicitações. Se você estiver ajustando o modelo para produzir um formato de dados estruturados, verifique se todas as respostas fornecidas estão estritamente de acordo com o formato de saída de dados desejado. A tabela a seguir mostra alguns exemplos de registros do conjunto de dados deste exemplo de código:
| Solicitação | Resposta |
|---|---|
| Olá, Indian Bakery Central,\nVocês têm 10 pendas e 30 bundi ladoos? Vocês também vendem cobertura de baunilha e bolos de chocolate? Estou procurando um tamanho de 15 cm | { "type": "inquiry", "items": [ { "name": "pendas", "quantity": 10 }, { "name": "bundi ladoos", "quantity": 30 }, { "name": "cake", "filling": null, "frosting": "vanilla", "flavor": "chocolate", "size": "6 in" } ] } |
| Vi sua empresa no Google Maps. Vocês vendem jellabi e gulab jamun? | { "type": "inquiry", "items": [ { "name": "jellabi", "quantity": null }, { "name": "gulab jamun", "quantity": null } ] } |
Tabela 1. Lista parcial do conjunto de dados de ajuste para o extrator de dados de e-mail da padaria.
Formato e carregamento de dados
Você pode armazenar os dados de ajuste em qualquer formato conveniente, incluindo registros de banco de dados, arquivos JSON, CSV ou de texto simples, desde que tenha os meios para recuperar os registros com código Python. Esse projeto lê arquivos JSON de um diretório data em uma matriz de objetos de dicionário.
Neste exemplo de programa de ajuste, o conjunto de dados de ajuste é carregado no módulo
model-tuning/main.py usando a função prepare_tuning_dataset():
def prepare_tuning_dataset():
# collect data from JSON files
prompt_data = read_json_files_to_dicts("./data")
...
Como mencionado anteriormente, é possível armazenar o conjunto de dados em um formato conveniente, desde que seja possível recuperar as solicitações com as respostas associadas e reuni-las em uma string de texto usada como um registro de ajuste.
Reúna registros de ajuste
Para o processo de ajuste real, o programa monta cada solicitação e resposta
em uma única string com as instruções do comando e o conteúdo da
resposta. Em seguida, o programa de ajuste tokeniza a string para consumo pelo modelo. Confira o código para montar um registro de ajuste na função prepare_tuning_dataset() do módulo model-tuning/main.py:
def prepare_tuning_dataset():
...
# prepare data for tuning
tuning_dataset = []
template = "{instruction}\n{response}"
for prompt in prompt_data:
tuning_dataset.append(template.format(instruction=prompt["prompt"],
response=prompt["response"]))
return tuning_dataset
Essa função usa os dados como entrada e os formata adicionando uma quebra de linha entre a instrução e a resposta.
Gerar pesos de modelo
Depois que os dados de ajuste estiverem no lugar e carregados, execute o programa de ajuste. O processo de ajuste deste aplicativo de exemplo usa a biblioteca Keras NLP para ajustar o modelo com uma adaptação de classificação baixa, ou técnica LoRA, para gerar novos pesos de modelo. Em comparação com o ajuste de precisão total, o uso do LoRA é muito mais eficiente em termos de memória porque aproxima as mudanças nos pesos do modelo. Em seguida, você pode sobrepor esses pesos aproximados aos pesos do modelo atual para mudar o comportamento dele.
Para executar o ajuste e calcular novos pesos:
Em uma janela de terminal, navegue até o diretório
model-tuning/.cd business-email-assistant/model-tuning/Execute o processo de ajuste usando o script
tune_model:./tune_model.sh
O processo de ajuste leva vários minutos, dependendo dos recursos de computação disponíveis. Quando a conclusão for bem-sucedida, o programa de ajuste vai gravar novos arquivos de peso *.h5 no diretório model-tuning/weights com o seguinte formato:
gemma2-2b_inquiry_tuned_4_epoch##.lora.h5
Solução de problemas
Se o ajuste não for concluído, há dois motivos prováveis:
- Sem memória ou recursos esgotados: esses erros ocorrem quando o processo de ajuste solicita memória que excede a memória disponível da GPU ou da CPU. Verifique se você não está executando o aplicativo da Web enquanto o processo de ajuste está em andamento. Se você estiver fazendo o ajuste em um dispositivo com 16 GB de memória de GPU,
verifique se o
token_limitestá definido como 256 e obatch_sizecomo 1. - Drivers de GPU não instalados ou incompatíveis com o JAX: o processo de ajuste requer que o dispositivo de computação tenha drivers de hardware instalados que sejam compatíveis com a versão das bibliotecas JAX. Para mais detalhes, consulte a documentação de instalação do JAX.
Implantar o modelo ajustado
O processo de ajuste gera várias ponderações com base nos dados de ajuste e no número total de épocas definidas no aplicativo de ajuste. Por padrão, o programa de ajuste gera três arquivos de peso do modelo, um para cada época de ajuste. Cada época de ajuste sucessiva produz pesos que reproduzem com mais precisão os resultados dos dados de ajuste. Você pode conferir as taxas de acurácia de cada época na saída do terminal do processo de ajuste, como mostrado abaixo:
...
8/8 ━━━━━━━━━━━━━━━━━━━━ 121s 195ms/step - loss: 0.5432 - sparse_categorical_accuracy: 0.5982
Epoch 2/3
8/8 ━━━━━━━━━━━━━━━━━━━━ 2s 194ms/step - loss: 0.3320 - sparse_categorical_accuracy: 0.6966
Epoch 3/3
8/8 ━━━━━━━━━━━━━━━━━━━━ 2s 192ms/step - loss: 0.2135 - sparse_categorical_accuracy: 0.7848
Embora você queira que a taxa de acurácia seja relativamente alta, em torno de 0,80, não é bom que ela seja muito alta ou muito próxima de 1,00, porque isso significa que os pesos estão quase fazendo overfitting nos dados de ajuste. Quando isso acontece, o modelo não tem um bom desempenho em solicitações significativamente diferentes dos exemplos de ajuste. Por padrão, o script de implantação escolhe os pesos da época 3, que geralmente têm uma taxa de acurácia de cerca de 0,80.
Para implantar os pesos gerados no aplicativo da Web:
Em uma janela de terminal, navegue até o diretório
model-tuning:cd business-email-assistant/model-tuning/Execute o processo de ajuste usando o script
deploy_weights:./deploy_weights.sh
Depois de executar esse script, você vai encontrar um novo arquivo *.h5 no diretório
email-processing-webapp/weights/.
Testar o novo modelo
Depois de implantar os novos pesos no aplicativo, é hora de testar o modelo recém-ajustado. Para isso, execute o aplicativo da Web novamente e gere uma resposta.
Para executar e testar o projeto:
Em uma janela de terminal, navegue até o diretório
email-processing-webapp:cd business-email-assistant/email-processing-webapp/Execute o aplicativo usando o script
run_app:./run_app.shDepois de iniciar o aplicativo da Web, o código do programa lista um URL em que é possível navegar e testar. Normalmente, o endereço é:
http://127.0.0.1:5000/Na interface da Web, pressione o botão Receber dados abaixo do primeiro campo de entrada para gerar uma resposta do modelo.
Agora você ajustou e implantou um modelo Gemma em um aplicativo. Teste o aplicativo e tente determinar os limites da capacidade de geração do modelo ajustado para sua tarefa. Se você encontrar cenários em que o modelo não tem um bom desempenho, considere adicionar algumas dessas solicitações à sua lista de dados de exemplo de ajuste, incluindo a solicitação e fornecendo uma resposta ideal. Em seguida, execute o processo de ajuste novamente, reimplante os novos pesos e teste a saída.
Outros recursos
Para mais informações sobre esse projeto, consulte o repositório de código do Gemma Cookbook. Se você precisar de ajuda para criar o aplicativo ou quiser colaborar com outros desenvolvedores, confira o servidor Discord da Comunidade de Desenvolvedores do Google. Para mais projetos do Build with Google AI, confira a playlist de vídeos.