
Trajtimi i pyetjeve të klientëve, përfshirë email-et, është një pjesë e domosdoshme e drejtimit të shumë bizneseve, por mund të bëhet shpejt i vështirë. Me pak përpjekje, modelet e inteligjencës artificiale (IA) si Gemma mund të ndihmojnë në lehtësimin e kësaj pune.
Çdo biznes i trajton pyetjet si emailet pak më ndryshe, prandaj është e rëndësishme të jeni në gjendje të përshtatni teknologjitë si IA gjeneruese me nevojat e biznesit tuaj. Ky projekt trajton problemin specifik të nxjerrjes së informacionit të porosisë nga emailet në një furrë buke në të dhëna të strukturuara, në mënyrë që të mund të shtohet shpejt në një sistem përpunimi porosish. Duke përdorur 10 deri në 20 shembuj pyetjesh dhe rezultatin që dëshironi, mund të akordoni një model Gemma për të përpunuar emailet nga klientët tuaj, t'ju ndihmojë të përgjigjeni shpejt dhe të integroheni me sistemet tuaja ekzistuese të biznesit. Ky projekt është ndërtuar si një model aplikacioni IA që mund ta zgjeroni dhe përshtatni për të marrë vlerë nga modelet Gemma për biznesin tuaj.
Për një përmbledhje video të projektit dhe si ta zgjeroni atë, duke përfshirë njohuri nga njerëzit që e ndërtuan, shikoni videon Build with Google AI të Business Email AI Assistant . Gjithashtu mund ta rishikoni kodin për këtë projekt në deponë e kodit Gemma Cookbook . Përndryshe, mund të filloni zgjerimin e projektit duke përdorur udhëzimet e mëposhtme.
Përmbledhje
Ky tutorial ju udhëzon në konfigurimin, ekzekutimin dhe zgjerimin e një aplikacioni asistent email-i për biznesin të ndërtuar me Gemma, Python dhe Flask. Projekti ofron një ndërfaqe bazë përdoruesi në internet që mund ta modifikoni për t'iu përshtatur nevojave tuaja. Aplikacioni është ndërtuar për të nxjerrë të dhëna nga email-et e klientëve në një strukturë për një furrë buke fiktive. Mund ta përdorni këtë model aplikacioni për çdo detyrë biznesi që përdor futjen dhe daljen e tekstit.
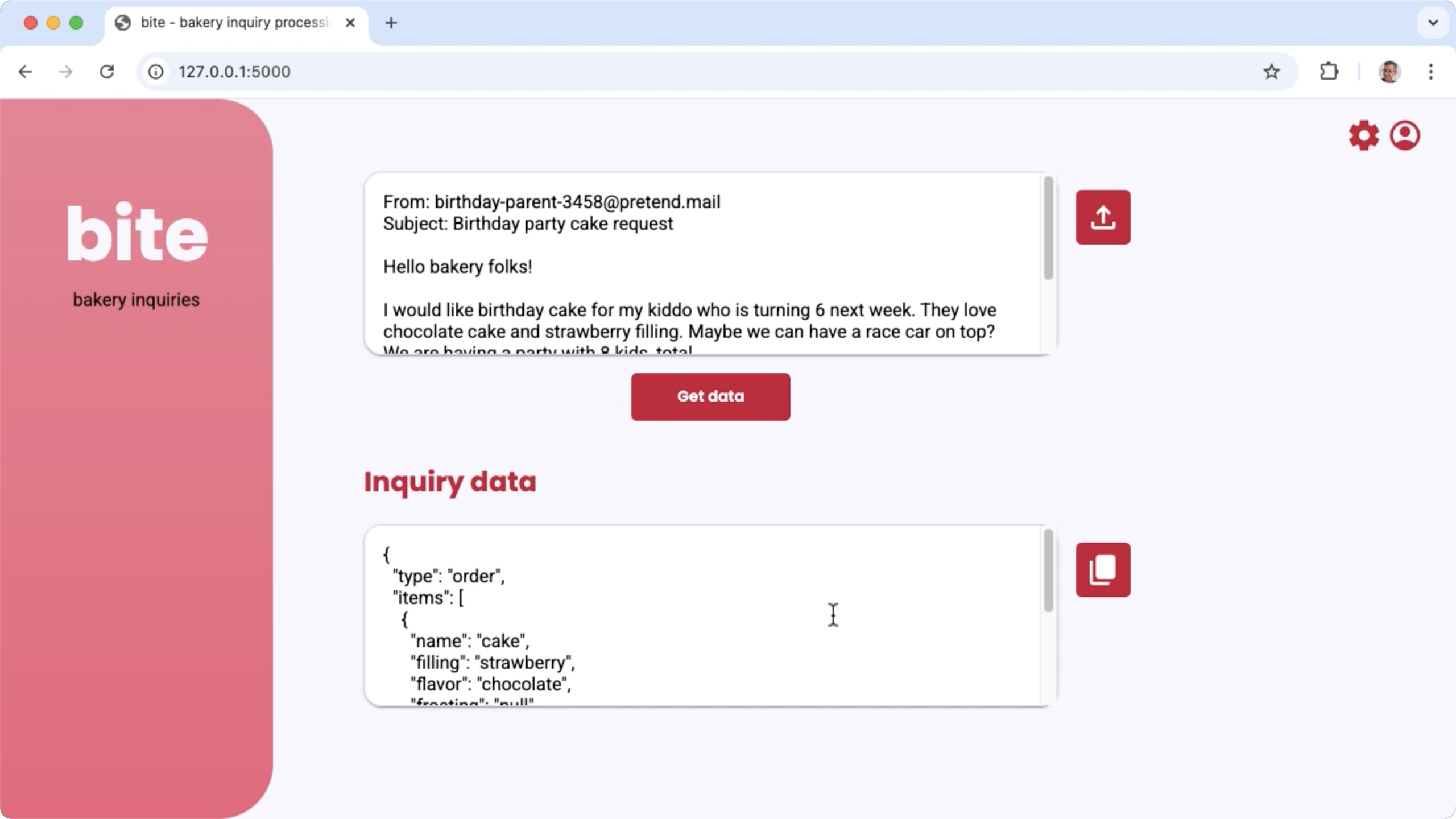
Figura 1. Ndërfaqja e përdoruesit të Projektit për përpunimin e pyetjeve me email të furrave të bukës
Kërkesat e harduerit
Ekzekutoni këtë proces akordimi në një kompjuter me një njësi përpunimi grafik (GPU) ose një njësi përpunimi Tensor (TPU), dhe memorie të mjaftueshme GPU ose TPU për të mbajtur modelin ekzistues, plus të dhënat e akordimit. Për të ekzekutuar konfigurimin e akordimit në këtë projekt, ju nevojiten rreth 16 GB memorie GPU, afërsisht e njëjta sasi RAM të rregullt dhe një minimum prej 50 GB hapësirë në disk.
Mund ta ekzekutoni pjesën e akordimit të modelit Gemma të këtij tutoriali duke përdorur një mjedis Colab me një kohë ekzekutimi GPU T4 . Nëse po e ndërtoni këtë projekt në një instancë të VM- së Google Cloud, konfiguroni instancën duke ndjekur këto kërkesa:
- Pajisjet GPU : Kërkohet një NVIDIA T4 për të ekzekutuar këtë projekt (rekomandohet NVIDIA L4 ose më i lartë)
- Sistemi Operativ : Zgjidhni një opsion Deep Learning në Linux , konkretisht Deep Learning VM me CUDA 12.3 M124 me drajverë të parainstaluar të softuerit GPU.
- Madhësia e diskut të nisjes : Siguroni të paktën 50 GB hapësirë në disk për të dhënat, modelet dhe softuerët mbështetës.
Konfigurimi i projektit
Këto udhëzime ju udhëzojnë në përgatitjen e këtij projekti për zhvillim dhe testim. Hapat e përgjithshëm të konfigurimit përfshijnë instalimin e softuerit paraprak, klonimin e projektit nga depoja e kodit, vendosjen e disa variablave të mjedisit, instalimin e bibliotekave Python dhe testimin e aplikacionit web.
Instalo dhe konfiguro
Ky projekt përdor Python 3 dhe Mjedise Virtuale ( venv ) për të menaxhuar paketat dhe për të ekzekutuar aplikacionin. Udhëzimet e mëposhtme të instalimit janë për një makinë pritëse Linux.
Për të instaluar softuerin e nevojshëm:
Instaloni Python 3 dhe paketën e mjedisit virtual
venvpër Python:sudo apt update sudo apt install git pip python3-venv
Klono projektin
Shkarko kodin e projektit në kompjuterin tënd të zhvillimit. Ju nevojitet softueri i kontrollit të burimit git për të rikuperuar kodin burimor të projektit.
Për të shkarkuar kodin e projektit:
Klononi repozitorin git duke përdorur komandën e mëposhtme:
git clone https://github.com/google-gemini/gemma-cookbook.gitOpsionalisht, konfiguroni repozitorin tuaj lokal git për të përdorur kontrollin e rrallë, në mënyrë që të keni vetëm skedarët për projektin:
cd gemma-cookbook/ git sparse-checkout set Demos/business-email-assistant/ git sparse-checkout init --cone
Instaloni bibliotekat e Python
Instaloni bibliotekat Python me mjedisin virtual venv Python të aktivizuar për të menaxhuar paketat dhe varësitë Python. Sigurohuni që ta aktivizoni mjedisin virtual Python përpara se të instaloni bibliotekat Python me instaluesin pip . Për më shumë informacion rreth përdorimit të mjediseve virtuale Python, shihni dokumentacionin Python venv .
Për të instaluar bibliotekat Python:
Në një dritare terminali, shkoni te direktoria
business-email-assistant:cd Demos/business-email-assistant/Konfiguroni dhe aktivizoni mjedisin virtual Python (venv) për këtë projekt:
python3 -m venv venv source venv/bin/activateInstaloni libraritë e kërkuara Python për këtë projekt duke përdorur skriptin
setup_python:./setup_python.sh
Vendos variablat e mjedisit
Ky projekt kërkon disa variabla mjedisi për t'u ekzekutuar, duke përfshirë një emër përdoruesi Kaggle dhe një token API të Kaggle. Duhet të keni një llogari Kaggle dhe të kërkoni qasje në modelet Gemma për të qenë në gjendje t'i shkarkoni ato. Për këtë projekt, ju shtoni Emrin e Përdoruesit të Kaggle dhe tokenin API të Kaggle në dy skedarë .env , të cilët lexohen përkatësisht nga aplikacioni web dhe programi i akordimit.
Për të vendosur variablat e mjedisit:
- Merrni emrin e përdoruesit dhe çelësin e tokenit në Kaggle duke ndjekur udhëzimet në dokumentacionin e Kaggle .
- Merrni akses në modelin Gemma duke ndjekur udhëzimet " Merrni akses në Gemma" në faqen e Konfigurimit të Gemma-s .
- Krijo skedarë të variablave të mjedisit për projektin, duke krijuar një skedar teksti
.envnë secilën nga këto vendndodhje në klonin tënd të projektit:email-processing-webapp/.env model-tuning/.env
Pasi të keni krijuar skedarët tekst
.env, shtoni cilësimet e mëposhtme në të dy skedarët:KAGGLE_USERNAME=<YOUR_KAGGLE_USERNAME_HERE> KAGGLE_KEY=<YOUR_KAGGLE_KEY_HERE>
Ekzekutoni dhe testoni aplikacionin
Pasi të keni përfunduar instalimin dhe konfigurimin e projektit, ekzekutoni aplikacionin web për të konfirmuar që e keni konfiguruar saktë. Duhet ta bëni këtë si një kontroll bazë përpara se të modifikoni projektin për përdorimin tuaj.
Për të ekzekutuar dhe testuar projektin:
Në një dritare terminali, shkoni te direktoria
email-processing-webapp:cd business-email-assistant/email-processing-webapp/Ekzekutoni aplikacionin duke përdorur skriptin
run_app:./run_app.shPas nisjes së aplikacionit web, kodi i programit rendit një URL ku mund të shfletoni dhe testoni. Zakonisht, kjo adresë është:
http://127.0.0.1:5000/Në ndërfaqen e internetit, shtypni butonin Merr të dhëna poshtë fushës së parë të futjes për të gjeneruar një përgjigje nga modeli.
Përgjigja e parë nga modeli pasi të ekzekutoni aplikacionin zgjat më shumë, pasi duhet të përfundojë hapat e inicializimit në ekzekutimin e gjeneratës së parë. Kërkesat pasuese të mesazheve dhe gjenerimi në një aplikacion web që është tashmë në ekzekutim përfundojnë në më pak kohë.
Zgjero aplikacionin
Pasi ta keni aplikacionin në punë, mund ta zgjeroni atë duke modifikuar ndërfaqen e përdoruesit dhe logjikën e biznesit për ta bërë të funksionojë për detyra që janë të rëndësishme për ju ose biznesin tuaj. Gjithashtu mund të modifikoni sjelljen e modelit Gemma duke përdorur kodin e aplikacionit duke ndryshuar komponentët e kërkesës që aplikacioni i dërgon modelit gjenerues të IA-së.
Aplikacioni i ofron modelit udhëzime së bashku me të dhënat hyrëse nga përdoruesi, një informacion të plotë mbi modelin. Ju mund t'i modifikoni këto udhëzime për të ndryshuar sjelljen e modelit, siç është specifikimi i emrave të parametrave dhe strukturës së JSON-it që do të gjenerohet. Një mënyrë më e thjeshtë për të ndryshuar sjelljen e modelit është të ofroni udhëzime ose udhëzime shtesë për përgjigjen e modelit, siç është specifikimi që përgjigjet e gjeneruara nuk duhet të përfshijnë asnjë formatim Markdown.
Për të modifikuar udhëzimet e menjëhershme:
- Në projektin e zhvillimit, hapni skedarin e kodit
business-email-assistant/email-processing-webapp/app.py. Në kodin
app.py, shtoni udhëzime shtesash në funksioninget_prompt():::def get_prompt(): return """ Extract the relevant details of this request and return them in JSON code, with no additional markdown formatting:\n"""
Ky shembull shton frazën "pa formatim shtesë të uljes së çmimit" në udhëzime.
Dhënia e udhëzimeve shtesë të menjëhershme mund të ndikojë fuqishëm në rezultatin e gjeneruar dhe kërkon shumë më pak përpjekje për t'u zbatuar. Duhet ta provoni këtë metodë së pari për të parë nëse mund të merrni sjelljen që dëshironi nga modeli. Megjithatë, përdorimi i udhëzimeve të menjëhershme për të modifikuar sjelljen e një modeli Gemma ka kufizimet e veta. Në veçanti, limiti i përgjithshëm i tokenëve të hyrjes së modelit, i cili është 8,192 tokena për Gemma 2, kërkon që ju të balanconi udhëzimet e hollësishme të menjëhershme me madhësinë e të dhënave të reja që jepni, në mënyrë që të qëndroni nën atë limit.
Akordoni modelin
Kryerja e rregullimit të imët të një modeli Gemma është mënyra e rekomanduar për ta bërë atë të përgjigjet më me besueshmëri për detyra specifike. Në veçanti, nëse dëshironi që modeli të gjenerojë JSON me një strukturë specifike, duke përfshirë parametra të emërtuar posaçërisht, duhet të merrni në konsideratë rregullimin e modelit për atë sjellje. Në varësi të detyrës që dëshironi që modeli të përfundojë, mund të arrini funksionalitetin bazë me 10 deri në 20 shembuj. Ky seksion i tutorialit shpjegon se si të konfiguroni dhe ekzekutoni rregullimin e imët në një model Gemma për një detyrë specifike.
Udhëzimet e mëposhtme shpjegojnë se si të kryhet operacioni i rregullimit të imët në një mjedis VM, megjithatë, ju mund ta kryeni këtë operacion rregullimi edhe duke përdorur fletoren e shënimeve Colab të lidhur me këtë projekt.
Kërkesat e harduerit
Kërkesat llogaritëse për rregullimin e imët janë të njëjta me kërkesat e harduerit për pjesën tjetër të projektit. Mund ta ekzekutoni operacionin e rregullimit në një mjedis Colab me një kohë ekzekutimi të GPU-së T4 nëse i kufizoni tokenët hyrës në 256 dhe madhësinë e grupit në 1.
Përgatitni të dhënat
Para se të filloni të akordoni një model Gemma, duhet të përgatitni të dhëna për akordim. Kur po akordoni një model për një detyrë specifike, ju nevojitet një grup shembujsh kërkese dhe përgjigjesh. Këta shembuj duhet të tregojnë tekstin e kërkesës, pa asnjë udhëzim , dhe tekstin e përgjigjes së pritur. Për të filluar, duhet të përgatitni një grup të dhënash me rreth 10 shembuj. Këta shembuj duhet të përfaqësojnë një larmi të plotë kërkesash dhe përgjigjesh ideale. Sigurohuni që kërkesat dhe përgjigjet të mos jenë përsëritëse, pasi kjo mund të shkaktojë që përgjigjet e modeleve të jenë përsëritëse dhe të mos përshtaten siç duhet me ndryshimet në kërkesa. Nëse po e akordoni modelin për të prodhuar një format të strukturuar të të dhënave, sigurohuni që të gjitha përgjigjet e dhëna të përputhen në mënyrë strikte me formatin e daljes së të dhënave që dëshironi. Tabela e mëposhtme tregon disa të dhëna shembull nga grupi i të dhënave të këtij shembulli kodi:
| Kërkesë | Përgjigje |
|---|---|
| Përshëndetje Indian Bakery Central,\nA keni rastësisht 10 penda dhe tridhjetë bundi ladoo në dispozicion? Gjithashtu, a shisni torta me krem vaniljeje dhe shije çokollate? Po kërkoj një madhësi 6 inç. | { "lloji": "kërkesë", "artikuj": [ { "emri": "penda", "sasia": 10 }, { "emri": "bundi ladoos", "sasia": 30 }, { "emri": "tortë", "mbushje": null, "krem": "vanilje", "shije": "çokollatë", "madhësia": "6 inç" } ] } |
| E pashë biznesin tënd në Google Maps. A shet pelte dhe gulab jamun? | { "lloji": "kërkesë", "artikuj": [ { "emri": "xhelabi", "sasia": null }, { "emri": "sasia e gulab", "sasia": null } ] } |
Tabela 1. Renditje e pjesshme e të dhënave të akordimit për nxjerrësin e të dhënave të email-it të furrës së bukës.
Formati dhe ngarkimi i të dhënave
Ju mund t'i ruani të dhënat e akordimit në çdo format që ju përshtatet, duke përfshirë të dhënat e bazës së të dhënave, skedarët JSON, CSV ose skedarët me tekst të thjeshtë, për sa kohë që keni mjetet për të rikuperuar të dhënat me kod Python. Ky projekt lexon skedarët JSON nga një drejtori data në një varg objektesh fjalori. Në këtë shembull të programit të akordimit, grupi i të dhënave të akordimit ngarkohet në modulin model-tuning/main.py duke përdorur funksionin prepare_tuning_dataset() :
def prepare_tuning_dataset():
# collect data from JSON files
prompt_data = read_json_files_to_dicts("./data")
...
Siç u përmend më parë, ju mund ta ruani të dhënat në një format të përshtatshëm, për sa kohë që mund të merrni kërkesat me përgjigjet përkatëse dhe t'i bashkoni ato në një varg teksti i cili përdoret si një regjistrim akordimi.
Montoni disqet e akordimit
Për procesin aktual të akordimit, programi mbledh çdo kërkesë dhe përgjigje në një varg të vetëm me udhëzimet e menjëhershme dhe përmbajtjen e përgjigjes. Programi i akordimit më pas e tokenizon vargun për t'u konsumuar nga modeli. Mund ta shihni kodin për montimin e një regjistrimi akordimi në funksionin prepare_tuning_dataset() të modulit model-tuning/main.py , si më poshtë:
def prepare_tuning_dataset():
...
# prepare data for tuning
tuning_dataset = []
template = "{instruction}\n{response}"
for prompt in prompt_data:
tuning_dataset.append(template.format(instruction=prompt["prompt"],
response=prompt["response"]))
return tuning_dataset
Ky funksion merr të dhënat si të dhëna hyrëse dhe i formaton ato duke shtuar një ndërprerje rreshti midis udhëzimit dhe përgjigjes.
Gjeneroni peshat e modelit
Pasi të keni të dhënat e akordimit në vend dhe të ngarkohen, mund të ekzekutoni programin e akordimit. Procesi i akordimit për këtë aplikacion shembull përdor bibliotekën Keras NLP për të akorduar modelin me një teknikë Low Rank Adaptation , ose LoRA, për të gjeneruar pesha të reja të modelit. Krahasuar me akordimin me precizion të plotë, përdorimi i LoRA është dukshëm më efikas në kujtesë sepse përafron ndryshimet në peshat e modelit. Pastaj mund t'i mbivendosni këto pesha të përafërta mbi peshat ekzistuese të modelit për të ndryshuar sjelljen e modelit.
Për të kryer ekzekutimin e akordimit dhe për të llogaritur peshat e reja:
Në një dritare terminali, shkoni te drejtoria
model-tuning/.cd business-email-assistant/model-tuning/Ekzekutoni procesin e akordimit duke përdorur skriptin
tune_model:./tune_model.sh
Procesi i akordimit zgjat disa minuta në varësi të burimeve tuaja llogaritëse në dispozicion. Kur përfundon me sukses, programi i akordimit shkruan skedarë të rinj të peshave *.h5 në direktorinë model-tuning/weights me formatin e mëposhtëm:
gemma2-2b_inquiry_tuned_4_epoch##.lora.h5
Zgjidhja e problemeve
Nëse akordimi nuk përfundon me sukses, ka dy arsye të mundshme:
- Memoria mungon ose burimet janë shteruar : Këto gabime ndodhin kur procesi i akordimit kërkon memorie që tejkalon memorien e disponueshme GPU ose CPU. Sigurohuni që nuk po e ekzekutoni aplikacionin web ndërsa procesi i akordimit është në ekzekutim. Nëse po e akordoni në një pajisje me 16 GB memorie GPU, sigurohuni që ta keni
token_limittë vendosur në 256 dhebatch_sizetë vendosur në 1 . - Drajverët e GPU-së nuk janë instaluar ose janë të papajtueshëm me JAX : Procesi i akordimit kërkon që pajisja llogaritëse të ketë të instaluar drajverë harduerikë që janë të pajtueshëm me versionin e bibliotekave JAX . Për më shumë detaje, shihni dokumentacionin e instalimit të JAX .
Vendos modelin e akorduar
Procesi i akordimit gjeneron pesha të shumëfishta bazuar në të dhënat e akordimit dhe numrin total të epokave të vendosura në aplikacionin e akordimit. Si parazgjedhje, programi i akordimit gjeneron 3 skedarë peshash modeli, një për secilën epokë akordimi. Çdo epokë pasuese akordimi prodhon pesha që riprodhojnë më saktë rezultatet e të dhënave të akordimit. Mund të shihni shkallët e saktësisë për secilën epokë në daljen e terminalit të procesit të akordimit, si më poshtë:
...
8/8 ━━━━━━━━━━━━━━━━━━━━ 121s 195ms/step - loss: 0.5432 - sparse_categorical_accuracy: 0.5982
Epoch 2/3
8/8 ━━━━━━━━━━━━━━━━━━━━ 2s 194ms/step - loss: 0.3320 - sparse_categorical_accuracy: 0.6966
Epoch 3/3
8/8 ━━━━━━━━━━━━━━━━━━━━ 2s 192ms/step - loss: 0.2135 - sparse_categorical_accuracy: 0.7848
Ndërkohë që dëshironi që shkalla e saktësisë të jetë relativisht e lartë, rreth 0.80, nuk dëshironi që shkalla të jetë shumë e lartë ose shumë afër 1.00, sepse kjo do të thotë që peshat i janë afruar shumë të dhënave të akordimit. Kur kjo ndodh, modeli nuk funksionon mirë në kërkesat që janë dukshëm të ndryshme nga shembujt e akordimit. Si parazgjedhje, skripti i vendosjes zgjedh peshat e epokës 3, të cilat zakonisht kanë një shkallë saktësie rreth 0.80.
Për të vendosur peshat e gjeneruara në aplikacionin web:
Në një dritare terminali, shkoni te drejtoria e
model-tuning:cd business-email-assistant/model-tuning/Ekzekutoni procesin e akordimit duke përdorur skriptin
deploy_weights:./deploy_weights.sh
Pas ekzekutimit të këtij skripti, duhet të shihni një skedar të ri *.h5 në direktorinë email-processing-webapp/weights/ .
Testoni modelin e ri
Pasi të keni vendosur peshat e reja në aplikacion, është koha të provoni modelin e akorduar rishtazi. Mund ta bëni këtë duke riekzekutuar aplikacionin web dhe duke gjeneruar një përgjigje.
Për të ekzekutuar dhe testuar projektin:
Në një dritare terminali, shkoni te direktoria
email-processing-webapp:cd business-email-assistant/email-processing-webapp/Ekzekutoni aplikacionin duke përdorur skriptin
run_app:./run_app.shPas fillimit të aplikacionit web, kodi i programit rendit një URL ku mund të shfletoni dhe testoni, zakonisht kjo adresë është:
http://127.0.0.1:5000/Në ndërfaqen e internetit, shtypni butonin Merr të dhëna poshtë fushës së parë të futjes për të gjeneruar një përgjigje nga modeli.
Tani keni akorduar dhe vendosur një model Gemma në një aplikacion! Eksperimentoni me aplikacionin dhe përpiquni të përcaktoni kufijtë e aftësisë së gjenerimit të modelit të akorduar për detyrën tuaj. Nëse gjeni skenarë ku modeli nuk funksionon mirë, merrni në konsideratë shtimin e disa prej këtyre kërkesave në listën tuaj të të dhënave të shembullit të akordimit duke shtuar kërkesën dhe duke ofruar një përgjigje ideale. Pastaj riekzekutoni procesin e akordimit, rivendosni peshat e reja dhe testoni rezultatin.
Burime shtesë
Për më shumë informacion rreth këtij projekti, shihni depozitën e kodit Gemma Cookbook . Nëse ju nevojitet ndihmë për ndërtimin e aplikacionit ose nëse doni të bashkëpunoni me zhvillues të tjerë, shikoni serverin Discord të Komunitetit të Zhvilluesve të Google . Për më shumë projekte Build with Google AI, shikoni listën e videove .