
E-postalar da dahil olmak üzere müşteri sorgularını yanıtlamak birçok işletmenin olmazsa olmazıdır ancak bu işlem kısa sürede bunaltıcı bir hâl alabilir. Gemma gibi yapay zeka modelleri, biraz çabayla bu işi kolaylaştırmaya yardımcı olabilir.
Her işletme, e-posta gibi sorguları biraz farklı şekilde ele alır. Bu nedenle, üretken yapay zeka gibi teknolojileri işletmenizin ihtiyaçlarına uyarlayabilmeniz önemlidir. Bu proje, fırına gönderilen e-postalardan sipariş bilgilerini ayıklayıp yapılandırılmış verilere dönüştürme sorununu ele alarak bu bilgilerin sipariş işleme sistemine hızlıca eklenmesini sağlar. 10 ila 20 sorgu örneği ve istediğiniz çıkışı kullanarak bir Gemma modelini müşterilerinizden gelen e-postaları işleyecek, hızlı yanıt vermenize yardımcı olacak ve mevcut iş sistemlerinizle entegre olacak şekilde ayarlayabilirsiniz. Bu proje, işletmeniz için Gemma modellerinden değer elde etmek üzere genişletebileceğiniz ve uyarlayabileceğiniz bir yapay zeka uygulama kalıbı olarak oluşturulmuştur.
Projenin ve nasıl genişletileceğinin video özetini (geliştiricilerin görüşleri dahil) görmek için Business Email AI Assistant Build with Google AI videosunu izleyin. Bu projenin kodunu Gemma Cookbook kod deposunda da inceleyebilirsiniz. Aksi takdirde, aşağıdaki talimatları uygulayarak projeyi genişletmeye başlayabilirsiniz.
Genel Bakış
Bu eğitimde, Gemma, Python ve Flask ile oluşturulmuş bir işletme e-posta asistanı uygulamasını kurma, çalıştırma ve genişletme adımları açıklanmaktadır. Proje, ihtiyaçlarınıza göre değiştirebileceğiniz temel bir web kullanıcı arayüzü sağlar. Uygulama, müşteri e-postalarından veri ayıklayıp kurgusal bir fırın için yapı oluşturacak şekilde tasarlanmıştır. Bu uygulama kalıbını, metin girişi ve metin çıkışı kullanan tüm işletme görevlerinde kullanabilirsiniz.
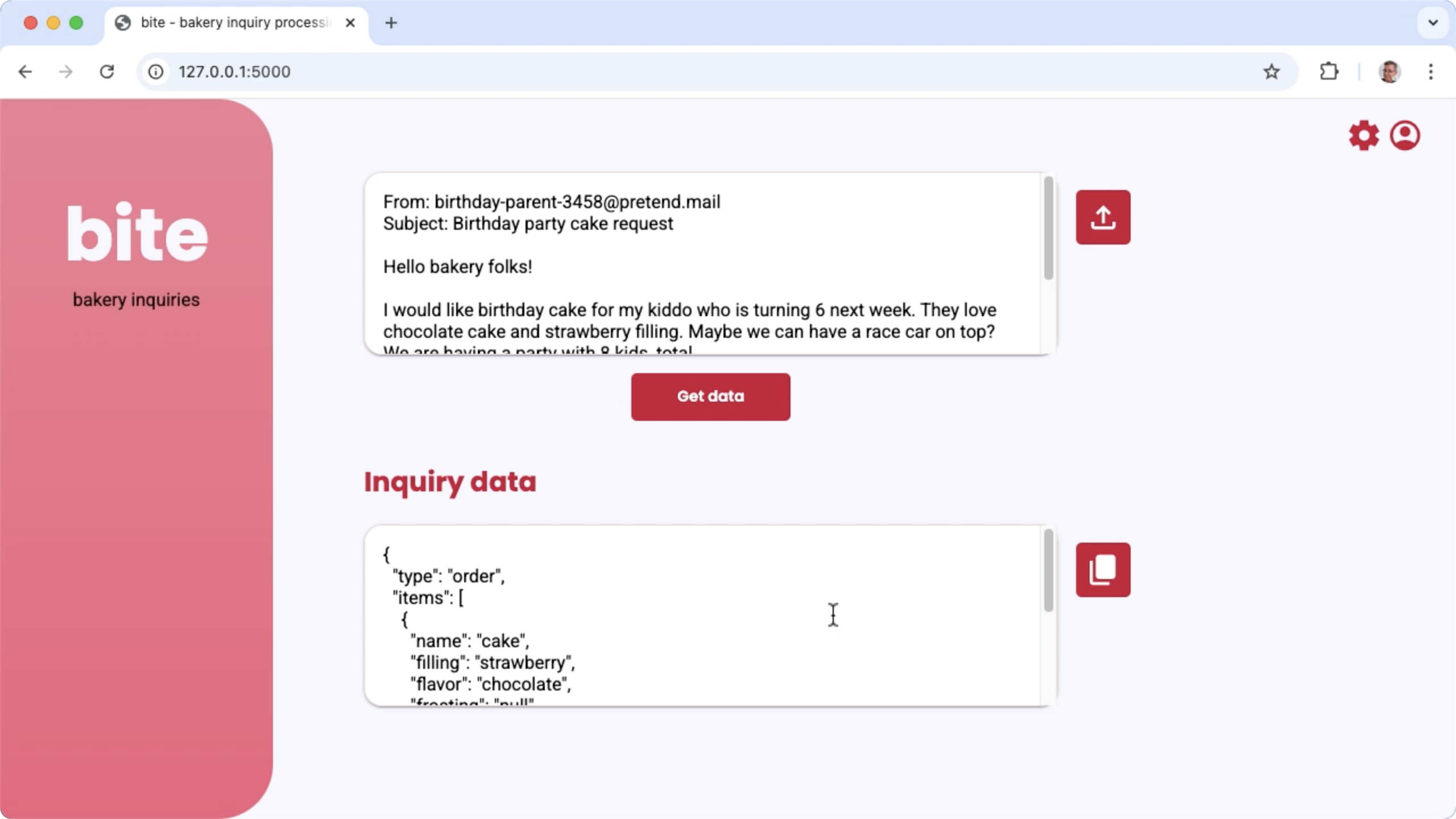
Şekil 1. Fırın e-posta sorgularını işlemek için proje kullanıcı arayüzü
Donanım gereksinimleri
Bu ayarlama sürecini, grafik işlem birimi (GPU) veya Tensor işlem birimi (TPU) olan ve mevcut modelin yanı sıra ayarlama verilerini tutmak için yeterli GPU veya TPU belleğine sahip bir bilgisayarda çalıştırın. Bu projede ayarlama yapılandırmasını çalıştırmak için yaklaşık 16 GB GPU belleği, yaklaşık aynı miktarda normal RAM ve en az 50 GB disk alanına ihtiyacınız vardır.
Bu eğitimin Gemma modeli ayarlama bölümünü T4 GPU çalışma zamanına sahip bir Colab ortamında çalıştırabilirsiniz. Bu projeyi bir Google Cloud sanal makine örneğinde oluşturuyorsanız örneği aşağıdaki şartlara göre yapılandırın:
- GPU donanımı: Bu projenin çalıştırılması için NVIDIA T4 gereklidir (NVIDIA L4 veya daha yüksek bir sürüm önerilir).
- İşletim Sistemi: Linux'ta Derin Öğrenme seçeneğini belirleyin. Özellikle önceden yüklenmiş GPU yazılım sürücülerine sahip CUDA 12.3 M124 ile Derin Öğrenme VM'si'ni seçin.
- Önyükleme diski boyutu: Verileriniz, modelleriniz ve destekleyici yazılımlarınız için en az 50 GB disk alanı sağlayın.
Proje ayarlama
Bu talimatlar, projeyi geliştirme ve test için hazırlama sürecinde size yol gösterir. Genel kurulum adımları arasında ön koşul yazılımlarının yüklenmesi, projenin kod deposundan klonlanması, birkaç ortam değişkeninin ayarlanması, Python kitaplıklarının yüklenmesi ve web uygulamasının test edilmesi yer alır.
Yükleme ve yapılandırma
Bu proje, paketleri yönetmek ve uygulamayı çalıştırmak için Python 3 ve sanal ortamları (venv) kullanır. Aşağıdaki yükleme talimatları bir Linux ana makinesi içindir.
Gerekli yazılımı yüklemek için:
Python 3'ü ve Python için
venvsanal ortam paketini yükleyin:sudo apt update sudo apt install git pip python3-venv
Projeyi klonlama
Proje kodunu geliştirme bilgisayarınıza indirin. Proje kaynak kodunu almak için git kaynak kontrol yazılımına ihtiyacınız vardır.
Proje kodunu indirmek için:
Aşağıdaki komutu kullanarak Git deposunu klonlayın:
git clone https://github.com/google-gemini/gemma-cookbook.gitİsteğe bağlı olarak, yerel Git deponuzu yalnızca proje dosyalarını içerecek şekilde seyrek ödeme kullanacak şekilde yapılandırın:
cd gemma-cookbook/ git sparse-checkout set Demos/business-email-assistant/ git sparse-checkout init --cone
Python kitaplıklarını yükleme
Python paketlerini ve bağımlılıklarını yönetmek için venvPython sanal ortamı
etkinleştirilmişken Python kitaplıklarını yükleyin. Python kitaplıklarını pip yükleyicisiyle yüklemeden önce Python sanal ortamını etkinleştirdiğinizden emin olun. Python sanal ortamlarını kullanma hakkında daha fazla bilgi için Python venv belgelerine bakın.
Python kitaplıklarını yüklemek için:
Bir terminal penceresinde
business-email-assistantdizinine gidin:cd Demos/business-email-assistant/Bu proje için Python sanal ortamını (venv) yapılandırın ve etkinleştirin:
python3 -m venv venv source venv/bin/activatesetup_pythonkomut dosyasını kullanarak bu proje için gerekli Python kitaplıklarını yükleyin:./setup_python.sh
Ortam değişkenlerini ayarlama
Bu projenin çalışması için Kaggle kullanıcı adı ve Kaggle API jetonu da dahil olmak üzere birkaç ortam değişkeni gerekir. Gemma modellerini indirebilmek için Kaggle hesabınızın olması ve bu modellere erişim isteğinde bulunmanız gerekir. Bu proje için Kaggle kullanıcı adınızı ve Kaggle API jetonunuzu iki .env dosyasına eklersiniz. Bu dosyalar, web uygulaması ve ayarlama programı tarafından okunur.
Ortam değişkenlerini ayarlamak için:
- Kaggle dokümanlarındaki talimatları uygulayarak Kaggle kullanıcı adınızı ve jeton anahtarınızı alın.
- Gemma Kurulumu sayfasındaki Gemma'ya erişme talimatlarını uygulayarak Gemma modeline erişin.
- Proje klonunuzda bu konumların her birinde
.envmetin dosyası oluşturarak proje için ortam değişkeni dosyaları oluşturun:email-processing-webapp/.env model-tuning/.env
.envmetin dosyalarını oluşturduktan sonra her iki dosyaya aşağıdaki ayarları ekleyin:KAGGLE_USERNAME=<YOUR_KAGGLE_USERNAME_HERE> KAGGLE_KEY=<YOUR_KAGGLE_KEY_HERE>
Uygulamayı çalıştırma ve test etme
Projenin kurulumunu ve yapılandırmasını tamamladıktan sonra, doğru yapılandırdığınızı onaylamak için web uygulamasını çalıştırın. Bu işlemi, projeyi kendi kullanımınız için düzenlemeden önce temel bir kontrol olarak yapmanız gerekir.
Projeyi çalıştırmak ve test etmek için:
Bir terminal penceresinde
email-processing-webappdizinine gidin:cd business-email-assistant/email-processing-webapp/run_appkomut dosyasını kullanarak uygulamayı çalıştırın:./run_app.shWeb uygulamasını başlattıktan sonra program kodu, göz atıp test edebileceğiniz bir URL listeler. Bu adres genellikle şöyledir:
http://127.0.0.1:5000/Web arayüzünde, modelden yanıt oluşturmak için ilk giriş alanının altındaki Veri al düğmesine basın.
Uygulamayı çalıştırdıktan sonra modelin ilk yanıtı daha uzun sürer. Bunun nedeni, ilk oluşturma çalıştırmasında başlatma adımlarını tamamlaması gerekmesidir. Zaten çalışan bir web uygulamasında sonraki istem istekleri ve oluşturma işlemleri daha kısa sürede tamamlanır.
Uygulamayı genişletme
Uygulama çalıştıktan sonra, kullanıcı arayüzünü ve iş mantığını değiştirerek uygulamayı size veya işletmenize uygun görevler için çalışacak şekilde genişletebilirsiniz. Uygulamanın üretken yapay zeka modeline gönderdiği istem bileşenlerini değiştirerek uygulama kodunu kullanarak Gemma modelinin davranışını da değiştirebilirsiniz.
Uygulama, kullanıcının giriş verileriyle birlikte modele talimatlar vererek modelin istemini tamamlar. Bu talimatları değiştirerek modelin davranışını değiştirebilirsiniz. Örneğin, oluşturulacak JSON'ın parametre adlarını ve yapısını belirtebilirsiniz. Modelin davranışını değiştirmenin daha basit bir yolu, modelin yanıtı için ek talimatlar veya rehberlik sağlamaktır. Örneğin, oluşturulan yanıtlarda Markdown biçimlendirmesi olmaması gerektiğini belirtebilirsiniz.
İstem talimatlarını değiştirmek için:
- Geliştirme projesinde
business-email-assistant/email-processing-webapp/app.pykod dosyasını açın. app.pykodunda,get_prompt():işlevine ek talimatlar ekleyin:def get_prompt(): return """ Extract the relevant details of this request and return them in JSON code, with no additional markdown formatting:\n"""
Bu örnek, talimatlara "ek markdown biçimlendirmesi olmadan" ifadesini ekler.
Ek istem talimatları sağlamak, oluşturulan çıktıyı büyük ölçüde etkileyebilir ve uygulaması çok daha az çaba gerektirir. Modelden istediğiniz davranışı elde edip edemeyeceğinizi görmek için önce bu yöntemi denemeniz gerekir. Ancak, bir Gemma modelinin davranışını değiştirmek için istem talimatlarını kullanmanın sınırları vardır. Özellikle, modelin genel giriş jetonu sınırı (Gemma 2 için 8.192 jeton) bu sınırın altında kalabilmeniz için ayrıntılı istem talimatlarını sağladığınız yeni verilerin boyutuyla dengelemenizi gerektirir.
Modeli ince şekilde ayarlama
Gemma modelinde ince ayar yapmak, belirli görevlerde daha güvenilir yanıtlar almanın önerilen yoludur. Özellikle modelin, belirli bir yapıya sahip JSON oluşturmasını istiyorsanız (ör. belirli adlandırılmış parametreler dahil), modeli bu davranış için ayarlamayı düşünebilirsiniz. Modelin tamamlamasını istediğiniz göreve bağlı olarak 10 ila 20 örnekle temel işlevselliğe ulaşabilirsiniz. Eğitimin bu bölümünde, belirli bir görev için Gemma modelinde ince ayar yapmanın nasıl ayarlanacağı ve çalıştırılacağı açıklanmaktadır.
Aşağıdaki talimatlarda, ince ayar işleminin bir sanal makine ortamında nasıl yapılacağı açıklanmaktadır. Ancak bu ince ayar işlemini, bu projeyle ilişkili Colab not defterini kullanarak da yapabilirsiniz.
Donanım gereksinimleri
İnce ayar için gereken işlem gücü, projenin geri kalanı için gereken donanım gereksinimleriyle aynıdır. Giriş jetonlarını 256 ile, toplu iş boyutunu ise 1 ile sınırlandırırsanız ayarlama işlemini T4 GPU çalışma zamanı olan bir Colab ortamında çalıştırabilirsiniz.
Verileri hazırlama
Bir Gemma modelini ayarlamaya başlamadan önce ayarlama için verileri hazırlamanız gerekir. Bir modeli belirli bir görev için ayarlarken bir dizi istek ve yanıt örneğine ihtiyacınız vardır. Bu örneklerde, talimat içermeyen istek metni ve beklenen yanıt metni gösterilmelidir. Başlamak için yaklaşık 10 örnek içeren bir veri kümesi hazırlamanız gerekir. Bu örnekler, çeşitli istekleri ve ideal yanıtları tam olarak yansıtmalıdır. İsteklerin ve yanıtların tekrarlı olmamasına dikkat edin. Aksi takdirde, modellerin yanıtları tekrarlı olabilir ve isteklerdeki değişikliklere uygun şekilde uyarlanmayabilir. Modeli yapılandırılmış veri biçimi oluşturacak şekilde ayarlıyorsanız sağlanan tüm yanıtların istediğiniz veri çıkışı biçimine kesinlikle uygun olduğundan emin olun. Aşağıdaki tabloda, bu kod örneğinin veri kümesinden birkaç örnek kayıt gösterilmektedir:
| İstek | Yanıt |
|---|---|
| Merhaba Indian Bakery Central,\nElinde 10 penda ve 30 bundi ladoo var mı? Ayrıca vanilyalı krema ve çikolatalı kek satıyor musunuz? 6 inç boyutunda bir ürün arıyorum. | { "type": "inquiry", "items": [ { "name": "pendas", "quantity": 10 }, { "name": "bundi ladoos", "quantity": 30 }, { "name": "cake", "filling": null, "frosting": "vanilla", "flavor": "chocolate", "size": "6 in" } ] } |
| Google Haritalar'da işletmenizi gördüm. Jalebi ve gulab jamun satıyor musunuz? | { "type": "inquiry", "items": [ { "name": "jellabi", "quantity": null }, { "name": "gulab jamun", "quantity": null } ] } |
Tablo 1. Fırın e-posta verileri için ayarlama veri kümesinin kısmi listesi çıkarıcı.
Veri biçimi ve yükleme
Kayıtları Python koduyla alabilmeniz koşuluyla, ayarlama verilerinizi veritabanı kayıtları, JSON dosyaları, CSV veya düz metin dosyaları gibi istediğiniz biçimde saklayabilirsiniz. Bu proje, data dizinindeki JSON dosyalarını sözlük nesneleri dizisine okur.
Bu örnek ayarlama programında, ayarlama veri kümesi prepare_tuning_dataset() işlevi kullanılarak model-tuning/main.py modülüne yüklenir:
def prepare_tuning_dataset():
# collect data from JSON files
prompt_data = read_json_files_to_dicts("./data")
...
Daha önce de belirtildiği gibi, istekleri ilişkili yanıtlarla birlikte alıp bir ayarlama kaydı olarak kullanılan bir metin dizesi halinde birleştirebildiğiniz sürece veri kümesini uygun bir biçimde saklayabilirsiniz.
Ayarlama kayıtlarını birleştirme
Program, gerçek ayarlama sürecinde her isteği ve yanıtı istem talimatları ve yanıtın içeriğiyle birlikte tek bir dizede birleştirir. Daha sonra ayarlama programı, dizeyi model tarafından kullanılmak üzere belirteklere ayırır. Bir ayarlama kaydını oluşturma kodunu model-tuning/main.py modülünün prepare_tuning_dataset() işlevinde aşağıdaki gibi görebilirsiniz:
def prepare_tuning_dataset():
...
# prepare data for tuning
tuning_dataset = []
template = "{instruction}\n{response}"
for prompt in prompt_data:
tuning_dataset.append(template.format(instruction=prompt["prompt"],
response=prompt["response"]))
return tuning_dataset
Bu işlev, verileri giriş olarak alır ve talimat ile yanıt arasına satır sonu ekleyerek biçimlendirir.
Model ağırlıkları oluşturma
İnce ayar verileri yerleştirilip yüklendikten sonra ince ayar programını çalıştırabilirsiniz. Bu örnek uygulamadaki ayarlama sürecinde, yeni model ağırlıkları oluşturmak için modeli Low Rank Adaptation (Düşük Dereceli Adaptasyon) veya LoRA tekniğiyle ayarlamak üzere Keras NLP kitaplığı kullanılır. LoRA, tam hassasiyetli ayarlamaya kıyasla model ağırlıklarındaki değişiklikleri yaklaştırdığı için önemli ölçüde daha az bellek kullanır. Ardından, modelin davranışını değiştirmek için bu yaklaşık ağırlıkları mevcut model ağırlıklarının üzerine yerleştirebilirsiniz.
İnce ayar çalıştırmasını gerçekleştirmek ve yeni ağırlıkları hesaplamak için:
Bir terminal penceresinde
model-tuning/dizinine gidin.cd business-email-assistant/model-tuning/tune_modelkomut dosyasını kullanarak ayarlama sürecini çalıştırın:./tune_model.sh
Ayarlama işlemi, kullanılabilir işlem kaynaklarınıza bağlı olarak birkaç dakika sürer. Başarıyla tamamlandığında, ayarlama programı *.h5 ağırlık dosyalarını model-tuning/weights dizinine şu biçimde yazar:
gemma2-2b_inquiry_tuned_4_epoch##.lora.h5
Sorun giderme
Ayarlama işlemi başarıyla tamamlanmazsa bunun iki olası nedeni vardır:
- Yetersiz bellek veya kaynaklar tükendi: Bu hatalar, ayarlama işlemi mevcut GPU belleğini veya CPU belleğini aşan bir bellek istediğinde ortaya çıkar. Ayarlama işlemi çalışırken web uygulamasını çalıştırmadığınızdan emin olun. GPU belleği 16 GB olan bir cihazda ayarlama yapıyorsanız
token_limitdeğerinin 256,batch_sizedeğerinin ise 1 olarak ayarlandığından emin olun. - GPU sürücüleri yüklü değil veya JAX ile uyumlu değil: Ayarlama işlemi, işlem cihazında JAX kitaplıklarının sürümüyle uyumlu donanım sürücülerinin yüklü olmasını gerektirir. Daha fazla bilgi için JAX yükleme belgelerini inceleyin.
Ayarlanmış modeli dağıtma
Ayarlama işlemi, ayarlama verilerine ve ayarlama uygulamasında ayarlanan toplam dönem sayısına göre birden fazla ağırlık oluşturur. Ayarlama programı varsayılan olarak her ayarlama dönemi için bir tane olmak üzere 3 model ağırlık dosyası oluşturur. Birbirini izleyen her ayarlama dönemi, ayarlama verilerinin sonuçlarını daha doğru şekilde üreten ağırlıklar oluşturur. Her dönem için doğruluk oranlarını, ayarlama işleminin terminal çıkışında aşağıdaki gibi görebilirsiniz:
...
8/8 ━━━━━━━━━━━━━━━━━━━━ 121s 195ms/step - loss: 0.5432 - sparse_categorical_accuracy: 0.5982
Epoch 2/3
8/8 ━━━━━━━━━━━━━━━━━━━━ 2s 194ms/step - loss: 0.3320 - sparse_categorical_accuracy: 0.6966
Epoch 3/3
8/8 ━━━━━━━━━━━━━━━━━━━━ 2s 192ms/step - loss: 0.2135 - sparse_categorical_accuracy: 0.7848
Doğruluk oranının nispeten yüksek (yaklaşık 0,80) olmasını istersiniz ancak bu oranın çok yüksek veya 1,00'a çok yakın olmasını istemezsiniz. Çünkü bu, ağırlıkların ayarlama verilerine aşırı uyum sağladığı anlamına gelir. Bu durumda model, ince ayar örneklerinden önemli ölçüde farklı olan isteklerde iyi performans göstermez. Dağıtım komut dosyası, varsayılan olarak genellikle yaklaşık %80 doğruluk oranına sahip olan 3.dönem ağırlıklarını seçer.
Oluşturulan ağırlıkları web uygulamasına dağıtmak için:
Bir terminal penceresinde
model-tuningdizinine gidin:cd business-email-assistant/model-tuning/deploy_weightskomut dosyasını kullanarak ayarlama sürecini çalıştırın:./deploy_weights.sh
Bu komut dosyası çalıştırıldıktan sonra email-processing-webapp/weights/ dizininde yeni bir *.h5 dosyası görmeniz gerekir.
Yeni modeli test etme
Yeni ağırlıkları uygulamaya dağıttıktan sonra yeni ayarlanmış modeli denemenin zamanı gelmiştir. Bunu, web uygulamasını yeniden çalıştırıp yanıt oluşturarak yapabilirsiniz.
Projeyi çalıştırmak ve test etmek için:
Bir terminal penceresinde
email-processing-webappdizinine gidin:cd business-email-assistant/email-processing-webapp/run_appkomut dosyasını kullanarak uygulamayı çalıştırın:./run_app.shWeb uygulaması başlatıldıktan sonra program kodu, göz atıp test edebileceğiniz bir URL'yi listeler. Bu adres genellikle şudur:
http://127.0.0.1:5000/Web arayüzünde, modelden yanıt oluşturmak için ilk giriş alanının altındaki Veri al düğmesine basın.
Artık bir uygulamada Gemma modelini ayarlayıp dağıttınız. Uygulamayla denemeler yapın ve ince ayar yapılmış modelin göreviniz için oluşturma özelliğinin sınırlarını belirlemeye çalışın. Modelin iyi performans göstermediği senaryolarla karşılaşırsanız isteği ekleyip ideal yanıtı sağlayarak bu isteklerden bazılarını ince ayar örnek verileri listenize ekleyebilirsiniz. Ardından ayarlama sürecini yeniden çalıştırın, yeni ağırlıkları yeniden dağıtın ve çıkışı test edin.
Ek kaynaklar
Bu proje hakkında daha fazla bilgi için Gemma Cookbook kod deposunu inceleyin. Uygulama oluşturma konusunda yardıma ihtiyacınız varsa veya diğer geliştiricilerle iş birliği yapmak istiyorsanız Google Developers Community Discord sunucusuna göz atın. Google Yapay Zeka ile Geliştirme projeleri hakkında daha fazla bilgi için video oynatma listesine göz atın.