
Any responsible approach to applying artificial intelligence (AI) should include safety policies, transparency artifacts, and safeguards, but being responsible with AI means more than following checklists.
GenAI products are relatively new and the behaviors of an application can vary more than earlier forms of software. For this reason, you should probe the models being used to examine examples of the model's behavior, and investigate surprises.
Prompting is the ubiquitous interface for interacting with GenAI, and engineering those prompts is as much art as it is science. However, there are tools that can help you empirically improve prompts for LLMs, such as the Learning Interpretability Tool (LIT). LIT is an open-source tool for visually understanding and debugging AI models, that can be used as a debugger for prompt engineering work. Follow along with the provided tutorial using the Colab or Codelab.
Analyze Gemma Models with LIT
|
|
|
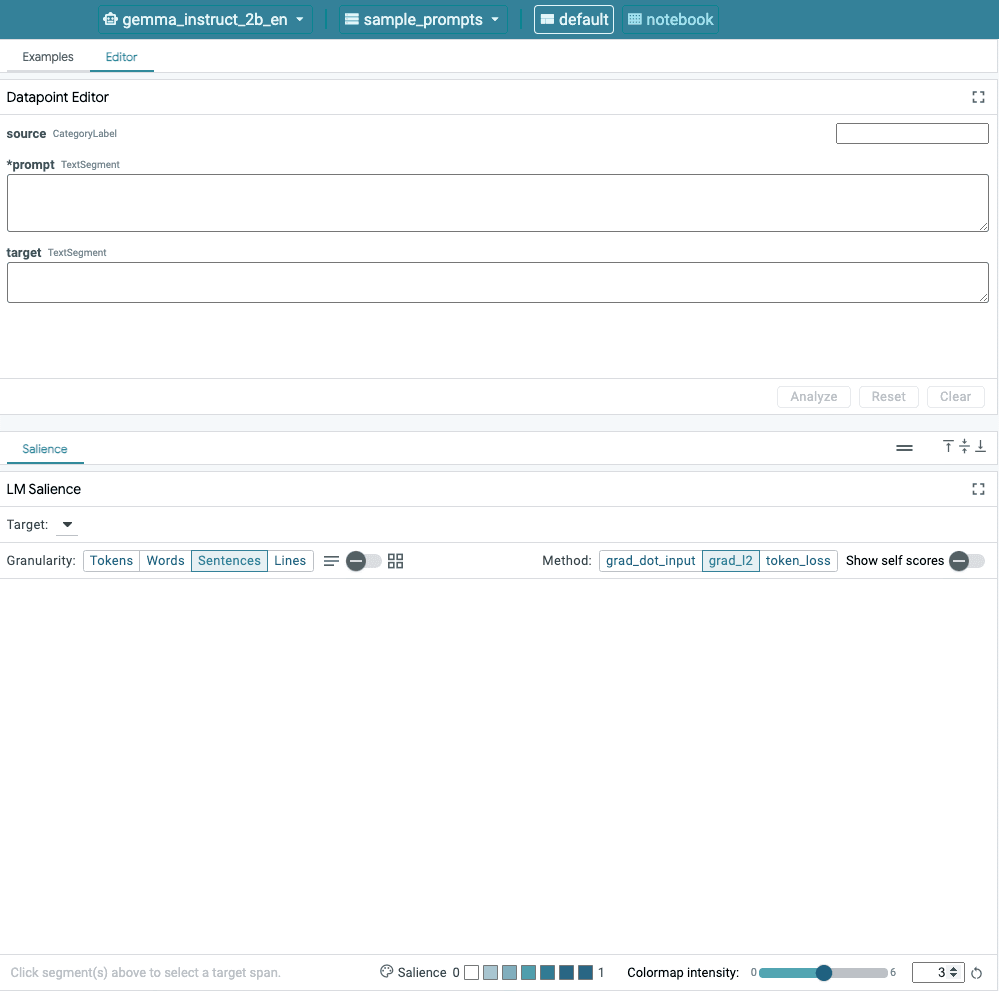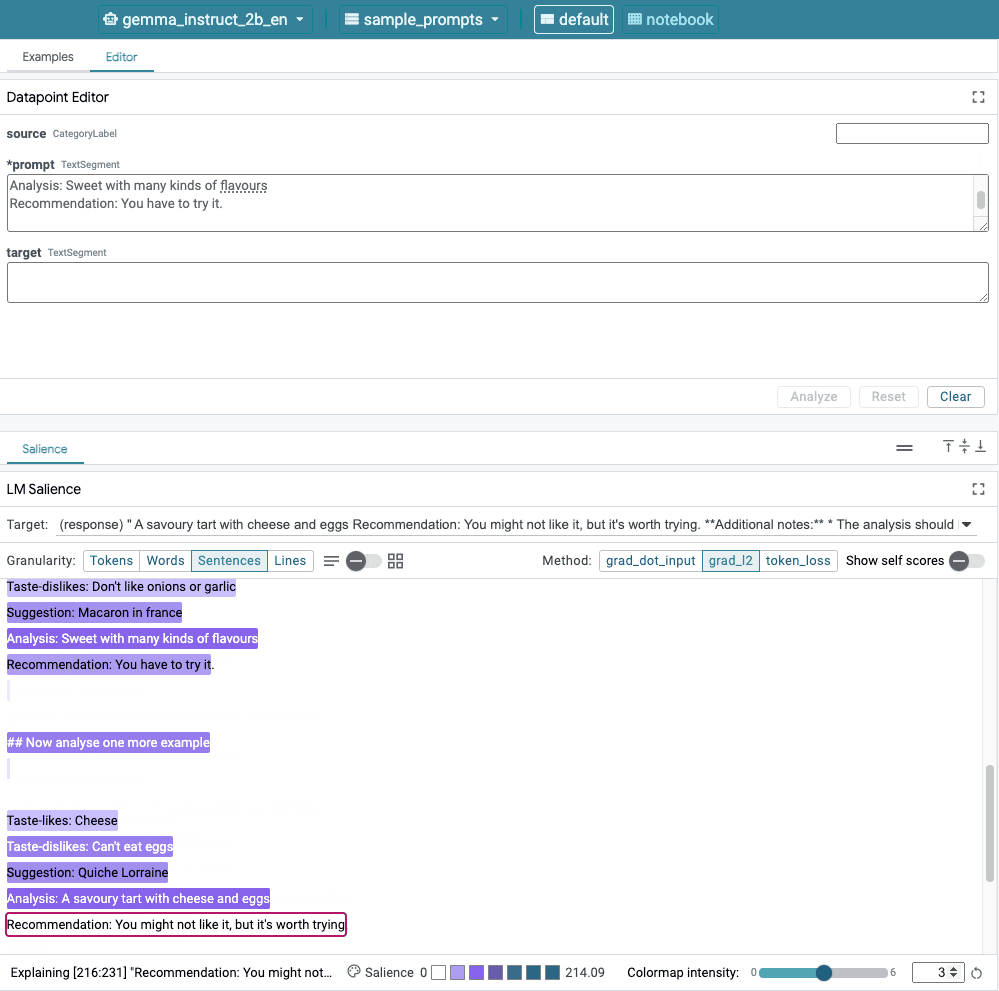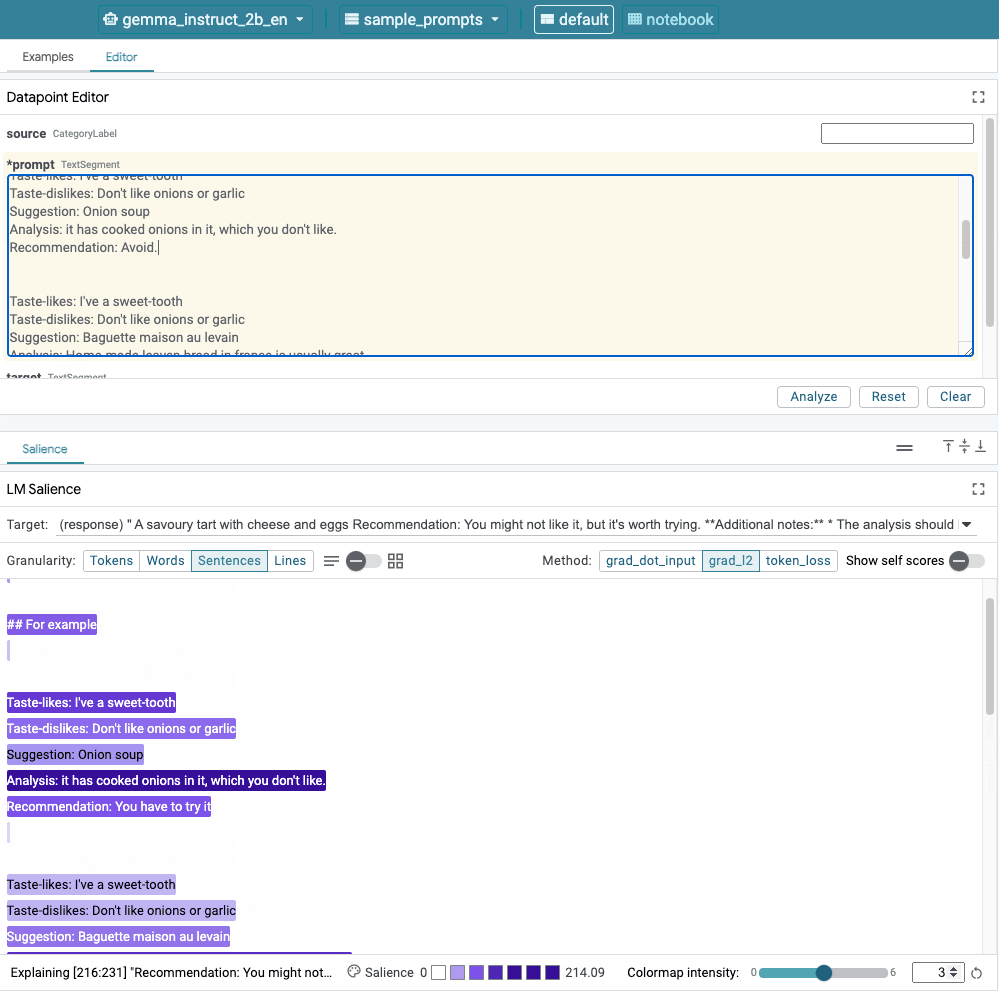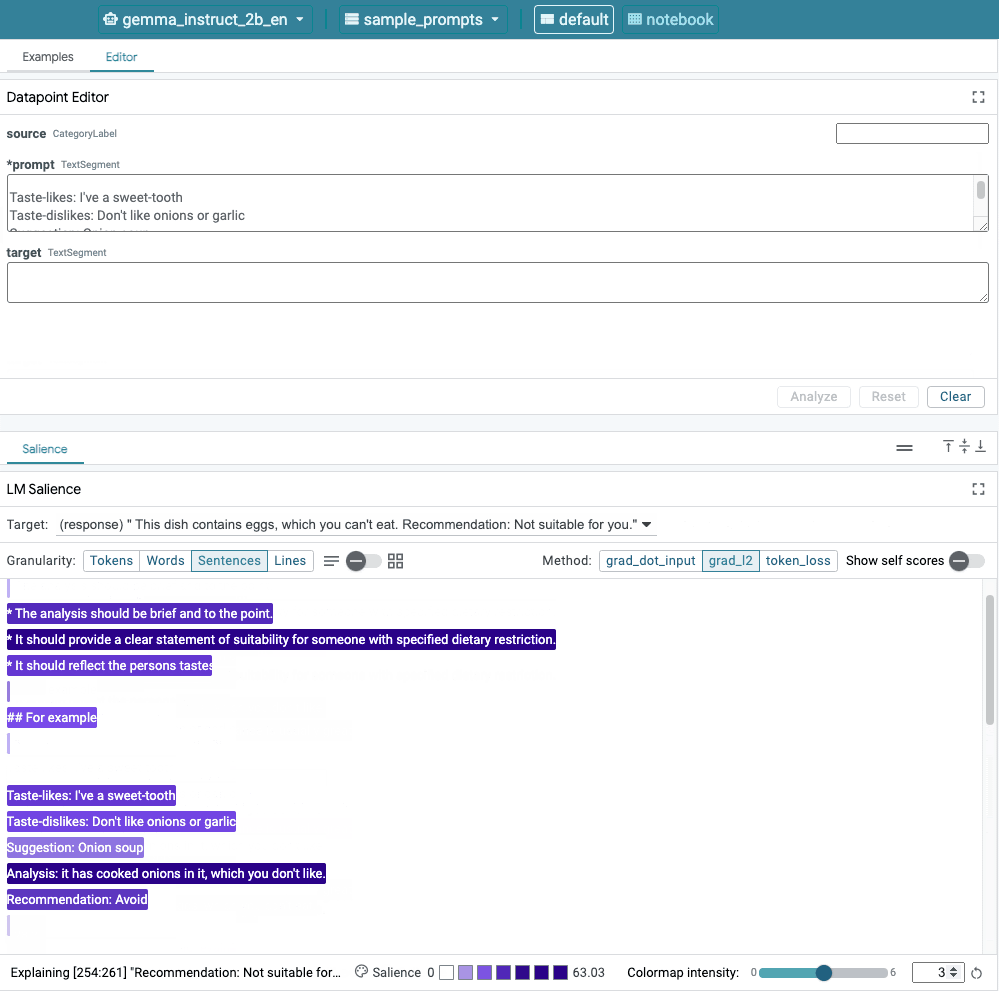
Figure 1. The LIT's user interface: the Datapoint Editor at the top allows users to edit their prompts. At the bottom, the LM Salience module allows them to check saliency results.
You can use LIT on your local machine, in Colab, or on Google Cloud.
Include non-technical teams in model probing and exploration
Interpretability is meant to be a team effort, spanning expertise across policy, legal, and more. LIT's visual medium and interactive ability to examine salience and explore examples can help different stakeholders share and communicate findings. This approach can enables more diversity of perspective in model exploration, probing, and debugging. Exposing your teammates to these technical methods can enhance their understanding of how models work. In addition, a more diverse set of expertise in early model testing can also help uncover undesirable outcomes that can be improved.