
Metadatat LiteRT ofrojnë një standard për përshkrimet e modelit. Metadatat janë një burim i rëndësishëm njohurish rreth asaj që bën modeli dhe informacionit të tij hyrës/dalës. Metadatat përbëhen nga të dyja:
- pjesë të lexueshme nga njeriu të cilat përcjellin praktikën më të mirë gjatë përdorimit të modelit, dhe
- pjesë të lexueshme nga makina që mund të shfrytëzohen nga gjeneratorët e kodit, siç është gjeneratori i kodit LiteRT për Android dhe funksioni Android Studio ML Binding .
Të gjitha modelet e imazheve të publikuara në Kaggle Models janë populluar me meta të dhëna.
Model me format metadatash
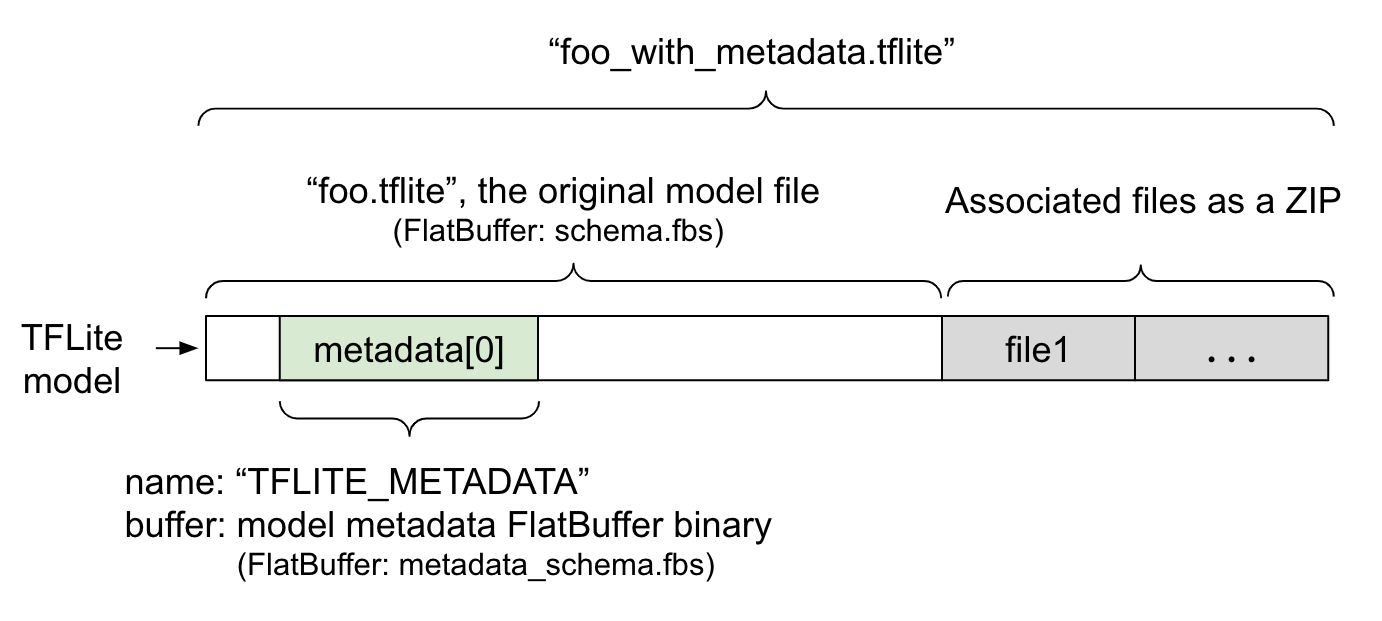
Meta të dhënat e modelit përcaktohen në metadata_schema.fbs , një skedar FlatBuffer . Siç tregohet në Figurën 1, ato ruhen në fushën e meta të dhënave të skemës së modelit TFLite , nën emrin "TFLITE_METADATA" . Disa modele mund të vijnë me skedarë të shoqëruar, siç janë skedarët e etiketave të klasifikimit . Këto skedarë bashkohen në fund të skedarit origjinal të modelit si një ZIP duke përdorur modalitetin "shtojce" të ZipFile (modaliteti 'a' ). Interpretuesi TFLite mund ta konsumojë formatin e ri të skedarit në të njëjtën mënyrë si më parë. Shihni Paketimi i skedarëve të shoqëruar për më shumë informacion.
Shihni udhëzimet më poshtë se si të populloni, vizualizoni dhe lexoni meta të dhënat.
Konfiguroni mjetet e meta të dhënave
Para se të shtoni meta të dhëna në modelin tuaj, do t'ju duhet të konfiguroni një mjedis programimi Python për të ekzekutuar TensorFlow. Këtu ka një udhëzues të detajuar se si ta konfiguroni këtë.
Pas konfigurimit të mjedisit të programimit Python, do t'ju duhet të instaloni mjete shtesë:
pip install tflite-support
Mjetet e meta të dhënave LiteRT mbështesin Python 3.
Shtimi i meta të dhënave duke përdorur API-n Flatbuffers Python
Ekzistojnë tre pjesë të meta të dhënave të modelit në skemë :
- Informacion mbi modelin - Përshkrim i përgjithshëm i modelit, si dhe artikuj të tillë si kushtet e licencës. Shih ModelMetadata . 2. Informacion mbi hyrjen - Përshkrimi i të dhënave hyrëse dhe përpunimit paraprak të kërkuar, siç është normalizimi. Shih SubGraphMetadata.input_tensor_metadata . 3. Informacion mbi daljen - Përshkrimi i rezultatit dhe përpunimit pasues të kërkuar, siç është hartëzimi me etiketat. Shih SubGraphMetadata.output_tensor_metadata .
Meqenëse LiteRT mbështet vetëm një nëngraf të vetëm në këtë pikë, gjeneratori i kodit LiteRT dhe funksioni i Android Studio ML Binding do të përdorin ModelMetadata.name dhe ModelMetadata.description , në vend të SubGraphMetadata.name dhe SubGraphMetadata.description , kur shfaqin meta të dhëna dhe gjenerojnë kod.
Llojet e Hyrjes / Daljes së Mbështetur
Meta të dhënat LiteRT për hyrje dhe dalje nuk janë projektuar duke pasur parasysh lloje specifike modelesh, por më tepër lloje hyrjesh dhe daljesh. Nuk ka rëndësi se çfarë bën modeli në mënyrë funksionale, për sa kohë që llojet e hyrjes dhe daljes përbëhen nga sa vijon ose një kombinim i sa vijon, ato mbështeten nga meta të dhënat TensorFlow Lite:
- Karakteristikë - Numra që janë numra të plotë pa shenjë ose me numër float32.
- Imazh - Metadatat aktualisht mbështesin imazhet RGB dhe ato në shkallë gri.
- Kutia kufizuese - Kuti kufizuese me formë drejtkëndëshe. Skema mbështet një sërë skemash numërimi .
Paketoni skedarët e lidhur
Modelet LiteRT mund të vijnë me skedarë të ndryshëm shoqërues. Për shembull, modelet e gjuhës natyrore zakonisht kanë skedarë fjalori që lidhin pjesët e fjalëve me ID-të e fjalëve; modelet e klasifikimit mund të kenë skedarë etiketash që tregojnë kategoritë e objekteve. Pa skedarët shoqërues (nëse ka), një model nuk do të funksionojë mirë.
Skedarët e shoqëruar tani mund të bashkohen me modelin përmes bibliotekës së meta të dhënave Python. Modeli i ri LiteRT bëhet një skedar zip që përmban si modelin ashtu edhe skedarët e shoqëruar. Mund të çpaketohet me mjetet e zakonshme zip. Ky format i ri i modelit vazhdon të përdorë të njëjtën prapashtesë skedari, .tflite . Është i pajtueshëm me kornizën ekzistuese TFLite dhe Interpreter. Shihni Paketimi i meta të dhënave dhe skedarëve të shoqëruar në model për më shumë detaje.
Informacioni i skedarit të shoqëruar mund të regjistrohet në meta të dhëna. Në varësi të llojit të skedarit dhe vendit ku është bashkangjitur skedari (p.sh. ModelMetadata , SubGraphMetadata dhe TensorMetadata ), gjeneratori i kodit LiteRT Android mund të aplikojë automatikisht përpunimin përkatës para/pas objektit. Shihni seksionin <Përdorimi i kodit të gjeneratorit> të secilit lloj skedari të shoqëruar në skemë për më shumë detaje.
Parametrat e normalizimit dhe kuantizimit
Normalizimi është një teknikë e zakonshme e përpunimit paraprak të të dhënave në të mësuarit automatik. Qëllimi i normalizimit është të ndryshojë vlerat në një shkallë të përbashkët, pa shtrembëruar ndryshimet në diapazonin e vlerave.
Kuantizimi i modelit është një teknikë që lejon përfaqësime me saktësi të reduktuar të peshave dhe, opsionalisht, aktivizime si për ruajtje ashtu edhe për llogaritje.
Për sa i përket parapërpunimit dhe paspërpunimit, normalizimi dhe kuantizimi janë dy hapa të pavarur. Ja detajet.
| Normalizimi | Kuantizimi | |
|---|---|---|
Një shembull i vlerave të parametrave të imazhit hyrës në MobileNet për modelet float dhe quant, përkatësisht. | Modeli notues : - mesatarja: 127.5 - standard: 127.5 Modeli kuant : - mesatarja: 127.5 - standard: 127.5 | Modeli notues : - zeroPikë: 0 - shkalla: 1.0 Modeli kuant : - zeroPikë: 128.0 - shkalla: 0.0078125f |
Kur të thirret? | Hyrjet : Nëse të dhënat hyrëse normalizohen gjatë trajnimit, të dhënat hyrëse të përfundimit duhet të normalizohen në përputhje me rrethanat. Daljet : të dhënat e daljes nuk do të normalizohen në përgjithësi. | Modelet notuese nuk kanë nevojë për kuantizim. Modeli i kuantizuar mund të ketë ose jo nevojë për kuantizim në përpunimin para/pas. Kjo varet nga lloji i të dhënave të tensorëve hyrës/dalës. - Tensorët lundrues: nuk nevojitet kuantizim në përpunimin para/pas. Op-i kuant dhe op-i dekuant përfshihen në grafikun e modelit. - Tensorët int8/uint8: kanë nevojë për kuantizim në përpunimin para/pas. |
Formula | normalizuar_hyrje = (hyrje - mesatare) / std | Kuantizoni për inputet : q = f / shkallë + pikë zero Dekuantizoni për daljet : f = (q - zeroPikë) * shkallë |
Ku janë parametrat | Plotësuar nga krijuesi i modelit dhe ruajtur në meta të dhënat e modelit, si NormalizationOptions | Plotësohet automatikisht nga konvertuesi TFLite dhe ruhet në skedarin e modelit tflite. |
| Si të merrni parametrat? | Përmes API-t MetadataExtractor [2] | Përmes API-t TFLite Tensor [1] ose përmes API-t MetadataExtractor [2] |
| A ndajnë modelet me vlerë notuese dhe ato kuantike të njëjtën vlerë? | Po, modelet float dhe quant kanë të njëjtat parametra normalizimi. | Jo, modeli notues nuk ka nevojë për kuantizim. |
| A e gjeneron automatikisht atë gjeneratori i kodit TFLite ose lidhja Android Studio ML gjatë përpunimit të të dhënave? | Po | Po |
[1] LiteRT Java API dhe LiteRT C++ API .
[2] Biblioteka e nxjerrësit të metadatave
Kur përpunohen të dhënat e imazhit për modelet uint8, normalizimi dhe kuantizimi ndonjëherë anashkalohen. Është në rregull ta bësh këtë kur vlerat e pikselëve janë në diapazonin [0, 255]. Por në përgjithësi, gjithmonë duhet t'i përpunosh të dhënat sipas parametrave të normalizimit dhe kuantizimit kur është e aplikueshme.
Shembuj
Mund të gjeni shembuj se si duhet të plotësohen meta të dhënat për lloje të ndryshme modelesh këtu:
Klasifikimi i imazheve
Shkarkoni skriptin këtu , i cili mbush metadatat në mobilenet_v1_0.75_160_quantized.tflite . Ekzekutoni skriptin si më poshtë:
python ./metadata_writer_for_image_classifier.py \
--model_file=./model_without_metadata/mobilenet_v1_0.75_160_quantized.tflite \
--label_file=./model_without_metadata/labels.txt \
--export_directory=model_with_metadata
Për të populluar metadatat për modele të tjera të klasifikimit të imazheve, shtoni specifikimet e modelit si kjo në skript. Pjesa tjetër e këtij udhëzuesi do të nxjerrë në pah disa nga seksionet kryesore në shembullin e klasifikimit të imazheve për të ilustruar elementët kryesorë.
Zhytje e thellë në shembullin e klasifikimit të imazheve
Informacion mbi modelin
Metadatat fillojnë duke krijuar një informacion të ri modeli:
from tflite_support import flatbuffers
from tflite_support import metadata as _metadata
from tflite_support import metadata_schema_py_generated as _metadata_fb
""" ... """
"""Creates the metadata for an image classifier."""
# Creates model info.
model_meta = _metadata_fb.ModelMetadataT()
model_meta.name = "MobileNetV1 image classifier"
model_meta.description = ("Identify the most prominent object in the "
"image from a set of 1,001 categories such as "
"trees, animals, food, vehicles, person etc.")
model_meta.version = "v1"
model_meta.author = "TensorFlow"
model_meta.license = ("Apache License. Version 2.0 "
"http://www.apache.org/licenses/LICENSE-2.0.")
Informacion hyrës/dalës
Ky seksion ju tregon se si të përshkruani nënshkrimin hyrës dhe dalës të modelit tuaj. Këto meta të dhëna mund të përdoren nga gjeneruesit automatikë të kodit për të krijuar kod para dhe pas përpunimit. Për të krijuar informacion hyrës ose dalës rreth një tensori:
# Creates input info.
input_meta = _metadata_fb.TensorMetadataT()
# Creates output info.
output_meta = _metadata_fb.TensorMetadataT()
Futja e imazhit
Imazhi është një lloj i zakonshëm i të dhënave hyrëse për të mësuarit automatik. Meta të dhënat LiteRT mbështesin informacione të tilla si hapësira e ngjyrave dhe informacione paraprake të përpunimit, siç është normalizimi. Dimensioni i imazhit nuk kërkon specifikim manual pasi ai është dhënë tashmë nga forma e tensorit të hyrjes dhe mund të nxirret automatikisht.
input_meta.name = "image"
input_meta.description = (
"Input image to be classified. The expected image is {0} x {1}, with "
"three channels (red, blue, and green) per pixel. Each value in the "
"tensor is a single byte between 0 and 255.".format(160, 160))
input_meta.content = _metadata_fb.ContentT()
input_meta.content.contentProperties = _metadata_fb.ImagePropertiesT()
input_meta.content.contentProperties.colorSpace = (
_metadata_fb.ColorSpaceType.RGB)
input_meta.content.contentPropertiesType = (
_metadata_fb.ContentProperties.ImageProperties)
input_normalization = _metadata_fb.ProcessUnitT()
input_normalization.optionsType = (
_metadata_fb.ProcessUnitOptions.NormalizationOptions)
input_normalization.options = _metadata_fb.NormalizationOptionsT()
input_normalization.options.mean = [127.5]
input_normalization.options.std = [127.5]
input_meta.processUnits = [input_normalization]
input_stats = _metadata_fb.StatsT()
input_stats.max = [255]
input_stats.min = [0]
input_meta.stats = input_stats
Dalja e etiketës
Etiketa mund të hartëzohet në një tensor dalës nëpërmjet një skedari të shoqëruar duke përdorur TENSOR_AXIS_LABELS .
# Creates output info.
output_meta = _metadata_fb.TensorMetadataT()
output_meta.name = "probability"
output_meta.description = "Probabilities of the 1001 labels respectively."
output_meta.content = _metadata_fb.ContentT()
output_meta.content.content_properties = _metadata_fb.FeaturePropertiesT()
output_meta.content.contentPropertiesType = (
_metadata_fb.ContentProperties.FeatureProperties)
output_stats = _metadata_fb.StatsT()
output_stats.max = [1.0]
output_stats.min = [0.0]
output_meta.stats = output_stats
label_file = _metadata_fb.AssociatedFileT()
label_file.name = os.path.basename("your_path_to_label_file")
label_file.description = "Labels for objects that the model can recognize."
label_file.type = _metadata_fb.AssociatedFileType.TENSOR_AXIS_LABELS
output_meta.associatedFiles = [label_file]
Krijo metadatat Flatbuffers
Kodi i mëposhtëm kombinon informacionin e modelit me informacionin hyrës dhe dalës:
# Creates subgraph info.
subgraph = _metadata_fb.SubGraphMetadataT()
subgraph.inputTensorMetadata = [input_meta]
subgraph.outputTensorMetadata = [output_meta]
model_meta.subgraphMetadata = [subgraph]
b = flatbuffers.Builder(0)
b.Finish(
model_meta.Pack(b),
_metadata.MetadataPopulator.METADATA_FILE_IDENTIFIER)
metadata_buf = b.Output()
Paketoni meta të dhënat dhe skedarët e lidhur në model
Pasi të krijohen metadatat Flatbuffers, metadatat dhe skedari i etiketës shkruhen në skedarin TFLite nëpërmjet metodës populate :
populator = _metadata.MetadataPopulator.with_model_file(model_file)
populator.load_metadata_buffer(metadata_buf)
populator.load_associated_files(["your_path_to_label_file"])
populator.populate()
Mund të paketoni sa skedarë të shoqëruar të dëshironi në model përmes load_associated_files . Megjithatë, kërkohet të paketohen të paktën ato skedarë të dokumentuar në meta të dhëna. Në këtë shembull, paketimi i skedarit të etiketës është i detyrueshëm.
Vizualizoni metadatat
Mund të përdorni Netron për të vizualizuar meta të dhënat tuaja, ose mund t'i lexoni ato nga një model LiteRT në një format json duke përdorur MetadataDisplayer :
displayer = _metadata.MetadataDisplayer.with_model_file(export_model_path)
export_json_file = os.path.join(FLAGS.export_directory,
os.path.splitext(model_basename)[0] + ".json")
json_file = displayer.get_metadata_json()
# Optional: write out the metadata as a json file
with open(export_json_file, "w") as f:
f.write(json_file)
Android Studio gjithashtu mbështet shfaqjen e meta të dhënave përmes funksionit Android Studio ML Binding .
Versioni i metadatave
Skema e meta të dhënave versionohet si nga numri i versionimit Semantik, i cili gjurmon ndryshimet e skedarit të skemës, ashtu edhe nga identifikimi i skedarit Flatbuffers, i cili tregon përputhshmërinë e vërtetë të versionit.
Numri i versionimit semantik
Skema e meta të dhënave versionohet nga numri i versionimit Semantic , siç është MAJOR.MINOR.PATCH. Ajo gjurmon ndryshimet e skemës sipas rregullave këtu . Shihni historikun e fushave të shtuara pas versionit 1.0.0 .
Identifikimi i skedarit Flatbuffers
Versionimi semantik garanton përputhshmërinë nëse ndiqen rregullat, por nuk nënkupton papajtueshmërinë e vërtetë. Kur rritet numri KRYESOR, kjo nuk do të thotë domosdoshmërisht se përputhshmëria prapa është e prishur. Prandaj, ne përdorim identifikimin e skedarit Flatbuffers , file_identifier , për të treguar përputhshmërinë e vërtetë të skemës së meta të dhënave. Identifikuesi i skedarit është saktësisht 4 karaktere i gjatë. Ai është i fiksuar në një skemë të caktuar të meta të dhënave dhe nuk i nënshtrohet ndryshimit nga përdoruesit. Nëse përputhshmëria prapa e skemës së meta të dhënave duhet të prishet për ndonjë arsye, file_identifier do të rritet, për shembull, nga "M001" në "M002". File_identifier pritet të ndryshohet shumë më rrallë se metadata_version.
Versioni minimal i nevojshëm i analizuesit të meta të dhënave
Versioni minimal i nevojshëm i analizuesit të meta të dhënave është versioni minimal i analizuesit të meta të dhënave (kodi i gjeneruar nga Flatbuffers) që mund t'i lexojë të gjitha meta të dhënat nga Flatbuffers. Versioni është në fakt numri më i madh i versionit midis versioneve të të gjitha fushave të mbushura dhe versioni më i vogël i përputhshëm i treguar nga identifikuesi i skedarit. Versioni minimal i nevojshëm i analizuesit të meta të dhënave mbushet automatikisht nga MetadataPopulator kur meta të dhënat mbushen në një model TFLite. Shihni nxjerrësin e meta të dhënave për më shumë informacion se si përdoret versioni minimal i nevojshëm i analizuesit të meta të dhënave.
Lexoni meta të dhënat nga modelet
Biblioteka e Ekstraktorit të Metadatave është një mjet i përshtatshëm për të lexuar metadatat dhe skedarët e shoqëruar nga modele në platforma të ndryshme (shih versionin Java dhe versionin C++ ). Ju mund të ndërtoni mjetin tuaj të ekstraktimit të metadatave në gjuhë të tjera duke përdorur bibliotekën Flatbuffers.
Lexoni meta të dhënat në Java
Për të përdorur bibliotekën Metadata Extractor në aplikacionin tuaj Android, ne rekomandojmë përdorimin e LiteRT Metadata AAR të strehuar në MavenCentral . Ai përmban klasën MetadataExtractor , si dhe lidhjet Java të FlatBuffers për skemën e meta të dhënave dhe skemën e modelit .
Mund ta specifikoni këtë në varësitë tuaja build.gradle si më poshtë:
dependencies {
implementation 'org.tensorflow:tensorflow-lite-metadata:0.1.0'
}
Për të përdorur pamjet e çastit çdo natë, sigurohuni që të keni shtuar repozitorin e pamjeve të çastit Sonatype .
Mund të inicializoni një objekt MetadataExtractor me një ByteBuffer që tregon te modeli:
public MetadataExtractor(ByteBuffer buffer);
ByteBuffer duhet të mbetet i pandryshuar për të gjithë jetëgjatësinë e objektit MetadataExtractor . Inicializimi mund të dështojë nëse identifikuesi i skedarit Flatbuffers i meta të dhënave të modelit nuk përputhet me atë të analizuesit të meta të dhënave. Shihni versionimin e meta të dhënave për më shumë informacion.
Me identifikuesit e skedarëve që përputhen, nxjerrësi i meta të dhënave do të lexojë me sukses meta të dhënat e gjeneruara nga të gjitha skemat e kaluara dhe të ardhshme për shkak të mekanizmit të përputhshmërisë përpara dhe prapa të Flatbuffers. Megjithatë, fushat nga skemat e ardhshme nuk mund të nxirren nga nxjerrësit më të vjetër të meta të dhënave. Versioni minimal i nevojshëm i analizuesit të meta të dhënave tregon versionin minimal të analizuesit të meta të dhënave që mund t'i lexojë të gjitha meta të dhënat e Flatbuffers. Mund të përdorni metodën e mëposhtme për të verifikuar nëse plotësohet kushti minimal i nevojshëm i versionit të analizuesit:
public final boolean isMinimumParserVersionSatisfied();
Kalimi i një modeli pa meta të dhëna lejohet. Megjithatë, thirrja e metodave që lexojnë nga meta të dhënat do të shkaktojë gabime në kohën e ekzekutimit. Mund të kontrolloni nëse një model ka meta të dhëna duke thirrur metodën hasMetadata :
public boolean hasMetadata();
MetadataExtractor ofron funksione të përshtatshme për ju që të merrni meta të dhënat e tenzorëve hyrës/dalës. Për shembull,
public int getInputTensorCount();
public TensorMetadata getInputTensorMetadata(int inputIndex);
public QuantizationParams getInputTensorQuantizationParams(int inputIndex);
public int[] getInputTensorShape(int inputIndex);
public int getoutputTensorCount();
public TensorMetadata getoutputTensorMetadata(int inputIndex);
public QuantizationParams getoutputTensorQuantizationParams(int inputIndex);
public int[] getoutputTensorShape(int inputIndex);
Edhe pse skema e modelit LiteRT mbështet nëngrafe të shumëfishta, Interpretuesi TFLite aktualisht mbështet vetëm një nëngraf të vetëm. Prandaj, MetadataExtractor nuk e përdor indeksin e nëngrafeve si argument hyrës në metodat e tij.
Lexoni skedarët e lidhur nga modelet
Modeli LiteRT me metadata dhe skedarë të lidhur është në thelb një skedar zip që mund të çpaketohet me mjete të zakonshme zip për të marrë skedarët e lidhur. Për shembull, mund të çkompresoni mobilenet_v1_0.75_160_quantized dhe të nxirrni skedarin e etiketës në model si më poshtë:
$ unzip mobilenet_v1_0.75_160_quantized_1_metadata_1.tflite
Archive: mobilenet_v1_0.75_160_quantized_1_metadata_1.tflite
extracting: labels.txt
Gjithashtu mund të lexoni skedarët e lidhur përmes bibliotekës Metadata Extractor.
Në Java, kaloni emrin e skedarit në metodën MetadataExtractor.getAssociatedFile :
public InputStream getAssociatedFile(String fileName);
Në mënyrë të ngjashme, në C++, kjo mund të bëhet me metodën ModelMetadataExtractor::GetAssociatedFile :
tflite::support::StatusOr<absl::string_view> GetAssociatedFile(
const std::string& filename) const;