
Die Machine-Learning-Operatoren (ML-Operatoren), die Sie in Ihrem Modell verwenden, können sich auf die Konvertierung eines TensorFlow-Modells in das LiteRT-Format auswirken. Der LiteRT-Konverter unterstützt eine begrenzte Anzahl von TensorFlow-Operationen, die in gängigen Inferenzmodellen verwendet werden. Das bedeutet, dass nicht jedes Modell direkt konvertiert werden kann. Mit dem Konvertertool können Sie zusätzliche Operatoren einfügen. Wenn Sie ein Modell auf diese Weise konvertieren, müssen Sie jedoch auch die LiteRT-Laufzeitumgebung ändern, die Sie zum Ausführen des Modells verwenden. Dadurch können Sie möglicherweise keine Standardoptionen für die Laufzeitbereitstellung wie Google Play-Dienste verwenden.
Der LiteRT-Konverter analysiert die Modellstruktur und wendet Optimierungen an, um das Modell mit den direkt unterstützten Operatoren kompatibel zu machen. Je nach den ML-Operatoren in Ihrem Modell kann der Konverter diese Operatoren beispielsweise auslassen oder zusammenführen, um sie ihren LiteRT-Entsprechungen zuzuordnen.
Auch bei unterstützten Vorgängen sind aus Leistungsgründen manchmal bestimmte Nutzungsmuster erforderlich. Am besten verstehen Sie, wie Sie ein TensorFlow-Modell erstellen, das mit LiteRT verwendet werden kann, wenn Sie sich genau ansehen, wie Vorgänge konvertiert und optimiert werden, und die Einschränkungen berücksichtigen, die sich aus diesem Prozess ergeben.
Unterstützte Operatoren
Die integrierten LiteRT-Operatoren sind eine Teilmenge der Operatoren, die Teil der TensorFlow-Kernbibliothek sind. Ihr TensorFlow-Modell kann auch benutzerdefinierte Operatoren in Form von zusammengesetzten Operatoren oder neuen Operatoren enthalten, die von Ihnen definiert wurden. Das Diagramm unten zeigt die Beziehungen zwischen diesen Operatoren.
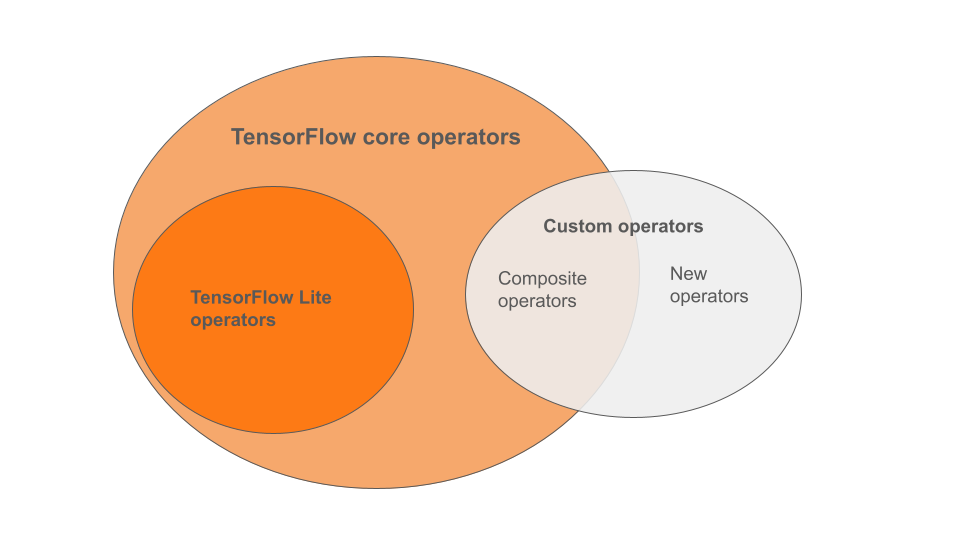
Aus diesem Bereich von ML-Modelloperatoren werden drei Modelltypen vom Konvertierungsprozess unterstützt:
- Modelle mit nur integriertem LiteRT-Operator. (Empfohlen)
- Modelle mit den integrierten Operatoren und ausgewählten TensorFlow-Kernoperatoren.
- Modelle mit integrierten Operatoren, TensorFlow-Kernoperatoren und/oder benutzerdefinierten Operatoren.
Wenn Ihr Modell nur Vorgänge enthält, die von LiteRT nativ unterstützt werden, benötigen Sie keine zusätzlichen Flags für die Konvertierung. Dies ist der empfohlene Pfad, da sich dieser Modelltyp problemlos konvertieren lässt und sich mit der standardmäßigen LiteRT-Laufzeit einfacher optimieren und ausführen lässt. Außerdem haben Sie mehr Bereitstellungsoptionen für Ihr Modell, z. B. die Google Play-Dienste. Leitfaden zum LiteRT-Konverter Eine Liste der integrierten Operatoren finden Sie auf der Seite „LiteRT Ops“.
Wenn Sie bestimmte TensorFlow-Operationen aus der Kernbibliothek einbeziehen müssen, müssen Sie das bei der Konvertierung angeben und dafür sorgen, dass Ihre Laufzeit diese Operationen enthält. Eine detaillierte Anleitung finden Sie im Thema TensorFlow-Operatoren auswählen.
Vermeiden Sie nach Möglichkeit die letzte Option, benutzerdefinierte Operatoren in Ihr konvertiertes Modell aufzunehmen. Benutzerdefinierte Operatoren werden entweder durch Kombinieren mehrerer primitiver TensorFlow Core-Operatoren oder durch Definieren eines völlig neuen Operators erstellt. Wenn benutzerdefinierte Operatoren konvertiert werden, kann sich die Größe des Gesamtmodells erhöhen, da Abhängigkeiten außerhalb der integrierten LiteRT-Bibliothek entstehen. Benutzerdefinierte Vorgänge, die nicht speziell für die Bereitstellung auf Mobilgeräten oder Geräten erstellt wurden, können im Vergleich zu einer Serverumgebung zu einer schlechteren Leistung führen, wenn sie auf Geräten mit begrenzten Ressourcen bereitgestellt werden. Schließlich müssen Sie wie bei der Einbindung ausgewählter TensorFlow-Kernoperatoren auch bei benutzerdefinierten Operatoren die Modelllaufzeitumgebung ändern. Dadurch können Sie keine Standardlaufzeitdienste wie die Google Play-Dienste nutzen.
Unterstützte Typen
Die meisten LiteRT-Vorgänge sind sowohl für die Inferenz mit Gleitkommazahlen (float32) als auch mit quantisierten Zahlen (uint8, int8) vorgesehen. Viele Vorgänge sind jedoch noch nicht für andere Typen wie tf.float16 und Strings verfügbar.
Abgesehen von der Verwendung unterschiedlicher Versionen der Operationen besteht der andere Unterschied zwischen Gleitkomma- und quantisierten Modellen in der Art und Weise, wie sie konvertiert werden. Für die quantisierte Konvertierung sind Informationen zum dynamischen Bereich für Tensoren erforderlich. Dazu ist während des Modelltrainings eine „Fake-Quantisierung“ erforderlich, um Bereichsinformationen über ein Kalibrierungs-Dataset zu erhalten oder eine „On-the-fly“-Bereichsschätzung durchzuführen. Weitere Informationen finden Sie unter Quantisierung.
Einfache Konvertierungen, Constant Folding und Fusing
Eine Reihe von TensorFlow-Vorgängen kann von LiteRT verarbeitet werden, auch wenn sie kein direktes Äquivalent haben. Das ist bei Vorgängen der Fall, die einfach aus dem Diagramm entfernt (tf.identity), durch Tensoren ersetzt (tf.placeholder) oder in komplexere Vorgänge zusammengeführt (tf.nn.bias_add) werden können. Selbst einige unterstützte Vorgänge können manchmal durch einen dieser Prozesse entfernt werden.
Hier ist eine nicht vollständige Liste von TensorFlow-Vorgängen, die normalerweise aus dem Diagramm entfernt werden:
tf.addtf.debugging.check_numericstf.constanttf.divtf.dividetf.fake_quant_with_min_max_argstf.fake_quant_with_min_max_varstf.identitytf.maximumtf.minimumtf.multiplytf.no_optf.placeholdertf.placeholder_with_defaulttf.realdivtf.reduce_maxtf.reduce_mintf.reduce_sumtf.rsqrttf.shapetf.sqrttf.squaretf.subtracttf.tiletf.nn.batch_norm_with_global_normalizationtf.nn.bias_addtf.nn.fused_batch_normtf.nn.relutf.nn.relu6
Experimentelle Vorgänge
Die folgenden LiteRT-Vorgänge sind vorhanden, aber noch nicht für benutzerdefinierte Modelle verfügbar:
CALLCONCAT_EMBEDDINGSCUSTOMEMBEDDING_LOOKUP_SPARSEHASHTABLE_LOOKUPLSH_PROJECTIONSKIP_GRAMSVDF