
La quantification post-entraînement est une technique de conversion qui peut réduire la taille du modèle tout en améliorant la latence du processeur et de l'accélération matérielle, avec une légère dégradation de la précision du modèle. Vous pouvez quantifier un modèle TensorFlow flottant déjà entraîné lorsque vous le convertissez au format LiteRT à l'aide du convertisseur LiteRT.
Méthodes d'optimisation
Vous avez le choix entre plusieurs options de quantification post-entraînement. Voici un tableau récapitulatif des choix et des avantages qu'ils offrent :
| Technique | Avantages | Matériel |
|---|---|---|
| Quantification de la plage dynamique | 4 fois plus petit, 2 à 3 fois plus rapide | Processeur |
| Quantification d'entiers | 4 x plus petit, 3 x plus rapide | CPU, Edge TPU, microcontrôleurs |
| Quantification float16 | 2x plus petit, accélération GPU | Processeur, GPU |
L'arbre de décision suivant peut vous aider à déterminer la méthode de quantification post-entraînement la mieux adaptée à votre cas d'utilisation :
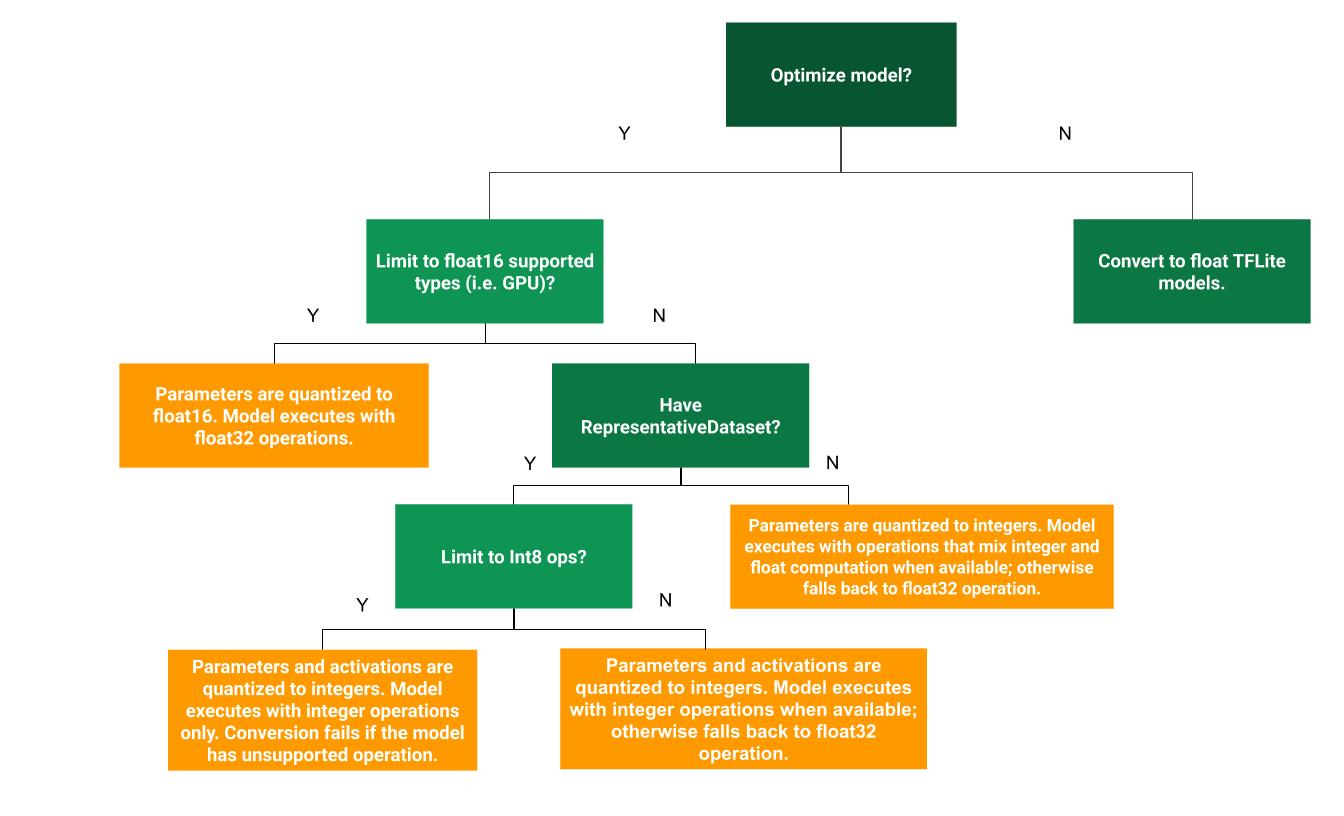
Aucune quantification
La conversion en modèle TFLite sans quantification est un bon point de départ. Un modèle TFLite float est alors généré.
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) tflite_quant_model = converter.convert()
Nous vous recommandons de le faire en tant qu'étape initiale pour vérifier que les opérateurs du modèle TF d'origine sont compatibles avec TFLite. Vous pouvez également l'utiliser comme référence pour déboguer les erreurs de quantification introduites par les méthodes de quantification post-entraînement ultérieures. Par exemple, si un modèle TFLite quantifié produit des résultats inattendus, alors que le modèle TFLite flottant est précis, nous pouvons identifier le problème comme étant lié à des erreurs introduites par la version quantifiée des opérateurs TFLite.
Quantification de la plage dynamique
La quantification de la plage dynamique permet de réduire l'utilisation de la mémoire et d'accélérer les calculs sans que vous ayez à fournir un ensemble de données représentatif pour la calibration. Ce type de quantification quantifie statiquement uniquement les pondérations de virgule flottante à entier au moment de la conversion, ce qui fournit une précision de 8 bits :
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] tflite_quant_model = converter.convert()
Pour réduire davantage la latence lors de l'inférence, les opérateurs "dynamic-range" quantifient dynamiquement les activations en fonction de leur plage sur 8 bits et effectuent des calculs avec des poids et des activations sur 8 bits. Cette optimisation permet d'obtenir des latences proches de celles des inférences entièrement en virgule fixe. Toutefois, les sorties sont toujours stockées à l'aide de nombres à virgule flottante. L'augmentation de la vitesse des opérations à plage dynamique est donc inférieure à celle d'un calcul complet à virgule fixe.
Quantification par nombres entiers
Vous pouvez améliorer davantage la latence, réduire l'utilisation maximale de la mémoire et assurer la compatibilité avec les accélérateurs ou appareils matériels utilisant uniquement des nombres entiers en vous assurant que tous les calculs du modèle sont quantifiés en nombres entiers.
Pour la quantification d'entiers complète, vous devez calibrer ou estimer la plage, c'est-à-dire (min, max) de tous les Tensors à virgule flottante du modèle. Contrairement aux Tensors constants tels que les pondérations et les biais, les Tensors variables tels que l'entrée du modèle, les activations (sorties des couches intermédiaires) et la sortie du modèle ne peuvent pas être calibrés, sauf si nous exécutons quelques cycles d'inférence. Par conséquent, le convertisseur nécessite un ensemble de données représentatif pour les calibrer. Cet ensemble de données peut être un petit sous-ensemble (environ 100 à 500 échantillons) des données d'entraînement ou de validation. Reportez-vous à la fonction representative_dataset() ci-dessous.
À partir de la version 2.7 de TensorFlow, vous pouvez spécifier l'ensemble de données représentatif à l'aide d'une signature, comme dans l'exemple suivant :
def representative_dataset():
for data in dataset:
yield {
"image": data.image,
"bias": data.bias,
}
Si le modèle TensorFlow donné comporte plusieurs signatures, vous pouvez spécifier l'ensemble de données multiple en indiquant les clés de signature :
def representative_dataset():
# Feed data set for the "encode" signature.
for data in encode_signature_dataset:
yield (
"encode", {
"image": data.image,
"bias": data.bias,
}
)
# Feed data set for the "decode" signature.
for data in decode_signature_dataset:
yield (
"decode", {
"image": data.image,
"hint": data.hint,
},
)
Vous pouvez générer l'ensemble de données représentatif en fournissant une liste de tenseurs d'entrée :
def representative_dataset():
for data in tf.data.Dataset.from_tensor_slices((images)).batch(1).take(100):
yield [tf.dtypes.cast(data, tf.float32)]
Depuis la version 2.7 de TensorFlow, nous vous recommandons d'utiliser l'approche basée sur les signatures plutôt que celle basée sur la liste des Tensors d'entrée, car l'ordre des Tensors d'entrée peut être facilement inversé.
À des fins de test, vous pouvez utiliser un ensemble de données factices comme suit :
def representative_dataset():
for _ in range(100):
data = np.random.rand(1, 244, 244, 3)
yield [data.astype(np.float32)]
Entier avec valeur flottante de secours (en utilisant l'entrée/sortie flottante par défaut)
Pour quantifier entièrement un modèle en nombres entiers, mais utiliser des opérateurs float lorsqu'ils n'ont pas d'implémentation d'entier (pour assurer une conversion fluide), procédez comme suit :
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.representative_dataset = representative_dataset tflite_quant_model = converter.convert()
Entiers uniquement
La création de modèles entiers uniquement est un cas d'utilisation courant pour LiteRT pour microcontrôleurs et les Coral Edge TPU.
De plus, pour assurer la compatibilité avec les appareils et accélérateurs utilisant uniquement des nombres entiers (tels que les microcontrôleurs 8 bits et les Coral Edge TPU), vous pouvez appliquer une quantification entière complète pour toutes les opérations, y compris les entrées et les sorties, en procédant comme suit :
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.representative_dataset = representative_dataset converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8] converter.inference_input_type = tf.int8 # or tf.uint8 converter.inference_output_type = tf.int8 # or tf.uint8 tflite_quant_model = converter.convert()
Quantification float16
Vous pouvez réduire la taille d'un modèle à virgule flottante en quantifiant les poids en float16, la norme IEEE pour les nombres à virgule flottante de 16 bits. Pour activer la quantification float16 des poids, procédez comme suit :
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.target_spec.supported_types = [tf.float16] tflite_quant_model = converter.convert()
Voici les avantages de la quantification float16 :
- Elle réduit la taille du modèle de moitié (puisque tous les poids sont divisés par deux).
- Elle entraîne une perte de précision minime.
- Il est compatible avec certains délégués (par exemple, le délégué GPU) qui peuvent fonctionner directement sur des données float16, ce qui permet une exécution plus rapide que les calculs float32.
Voici les inconvénients de la quantification float16 :
- Elle ne réduit pas la latence autant qu'une quantification en mathématiques à virgule fixe.
- Par défaut, un modèle quantifié float16 "déquantifie" les valeurs de poids en float32 lorsqu'il est exécuté sur le processeur. (Notez que le délégué GPU n'effectuera pas cette déquantification, car il peut fonctionner sur des données float16.)
Entiers uniquement : activations 16 bits avec poids 8 bits (expérimental)
Il s'agit d'un schéma de quantification expérimental. Il est semblable au schéma "entiers uniquement", mais les activations sont quantifiées en fonction de leur plage sur 16 bits, les pondérations sont quantifiées en entiers de 8 bits et le biais est quantifié en entiers de 64 bits. Nous y ferons référence plus loin sous le nom de quantification 16x8.
Le principal avantage de cette quantification est qu'elle peut améliorer considérablement la précision, tout en n'augmentant que légèrement la taille du modèle.
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.representative_dataset = representative_dataset converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.target_spec.supported_ops = [tf.lite.OpsSet.EXPERIMENTAL_TFLITE_BUILTINS_ACTIVATIONS_INT16_WEIGHTS_INT8] tflite_quant_model = converter.convert()
Si la quantification 16x8 n'est pas compatible avec certains opérateurs du modèle, le modèle peut toujours être quantifié, mais les opérateurs non compatibles sont conservés en float. L'option suivante doit être ajoutée à target_spec pour permettre cela.
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.representative_dataset = representative_dataset converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.target_spec.supported_ops = [tf.lite.OpsSet.EXPERIMENTAL_TFLITE_BUILTINS_ACTIVATIONS_INT16_WEIGHTS_INT8, tf.lite.OpsSet.TFLITE_BUILTINS] tflite_quant_model = converter.convert()
Voici quelques exemples de cas d'utilisation dans lesquels les améliorations de précision fournies par ce schéma de quantification sont utiles :
- super-résolution,
- le traitement du signal audio, comme la suppression du bruit et la formation de faisceaux ;
- le débruitage d'images ;
- Reconstruction HDR à partir d'une seule image.
L'inconvénient de cette quantification est le suivant :
- Actuellement, l'inférence est sensiblement plus lente que l'inférence en entier 8 bits en raison du manque d'implémentation de noyau optimisée.
- Il est actuellement incompatible avec les délégués TFLite existants accélérés par le matériel.
Un tutoriel sur ce mode de quantification est disponible ici.
Précision du modèle
Étant donné que les poids sont quantifiés après l'entraînement, il peut y avoir une perte de précision, en particulier pour les réseaux plus petits. Des modèles entièrement quantifiés et pré-entraînés sont fournis pour des réseaux spécifiques sur Kaggle Models. Il est important de vérifier l'exactitude du modèle quantifié pour s'assurer que toute dégradation de l'exactitude reste dans les limites acceptables. Il existe des outils pour évaluer l'exactitude des modèles LiteRT.
Si la baisse de précision est trop importante, vous pouvez également envisager d'utiliser l'entraînement tenant compte de la quantification. Toutefois, cela nécessite des modifications lors de l'entraînement du modèle pour ajouter de faux nœuds de quantification, alors que les techniques de quantification post-entraînement sur cette page utilisent un modèle pré-entraîné existant.
Représentation des tenseurs quantifiés
La quantification 8 bits permet d'approximer les valeurs à virgule flottante à l'aide de la formule suivante.
\[real\_value = (int8\_value - zero\_point) \times scale\]
La représentation comporte deux parties principales :
Pondérations par axe (ou par canal) ou par Tensor représentées par des valeurs int8 en complément à deux dans la plage [-127, 127] avec un point zéro égal à 0.
Activations/entrées par Tensor représentées par des valeurs int8 en complément à deux dans la plage [-128, 127], avec un point zéro dans la plage [-128, 127].
Pour obtenir une vue détaillée de notre schéma de quantification, veuillez consulter nos spécifications de quantification. Les fournisseurs de matériel qui souhaitent se connecter à l'interface de délégué de TensorFlow Lite sont encouragés à implémenter le schéma de quantification qui y est décrit.