
Urządzenia brzegowe mają często ograniczoną pamięć lub moc obliczeniową. Do modeli można zastosować różne optymalizacje, aby można było je uruchamiać w ramach tych ograniczeń. Niektóre optymalizacje umożliwiają też korzystanie ze specjalistycznego sprzętu do przyspieszonego wnioskowania.
LiteRT i TensorFlow Model Optimization Toolkit udostępniają narzędzia, które minimalizują złożoność optymalizacji wnioskowania.
Zalecamy rozważenie optymalizacji modelu podczas procesu tworzenia aplikacji. W tym dokumencie przedstawiamy sprawdzone metody optymalizacji modeli TensorFlow pod kątem wdrażania na urządzeniach brzegowych.
Dlaczego modele powinny być zoptymalizowane
Optymalizacja modelu może pomóc w rozwoju aplikacji na kilka głównych sposobów.
Zmniejszanie rozmiaru
Niektóre formy optymalizacji mogą służyć do zmniejszania rozmiaru modelu. Mniejsze modele mają te zalety:
- Mniejszy rozmiar pamięci: mniejsze modele zajmują mniej miejsca na urządzeniach użytkowników. Na przykład aplikacja na Androida korzystająca z mniejszego modelu zajmuje mniej miejsca na urządzeniu mobilnym użytkownika.
- Mniejszy rozmiar pobierania: mniejsze modele wymagają mniej czasu i przepustowości, aby pobrać je na urządzenia użytkowników.
- Mniejsze zużycie pamięci: mniejsze modele zużywają mniej pamięci RAM podczas działania, co zwalnia pamięć na potrzeby innych części aplikacji i może przekładać się na lepszą wydajność i stabilność.
Kwantyzacja może zmniejszyć rozmiar modelu we wszystkich tych przypadkach, potencjalnie kosztem pewnej utraty dokładności. Przycinanie i grupowanie mogą zmniejszyć rozmiar modelu do pobrania, ponieważ ułatwiają jego kompresję.
Skracanie czasu oczekiwania
Opóźnienie to czas potrzebny na przeprowadzenie pojedynczego wnioskowania za pomocą danego modelu. Niektóre formy optymalizacji mogą zmniejszyć ilość obliczeń wymaganych do uruchomienia wnioskowania przy użyciu modelu, co skutkuje mniejszym opóźnieniem. Opóźnienie może też mieć wpływ na zużycie energii.
Kwantyzacja może obecnie służyć do zmniejszania opóźnień przez upraszczanie obliczeń wykonywanych podczas wnioskowania, potencjalnie kosztem pewnej utraty dokładności.
Zgodność akceleratora
Niektóre akceleratory sprzętowe, takie jak Edge TPU, mogą bardzo szybko przeprowadzać wnioskowanie na podstawie prawidłowo zoptymalizowanych modeli.
Zazwyczaj tego typu urządzenia wymagają kwantyzacji modeli w określony sposób. Więcej informacji o wymaganiach poszczególnych akceleratorów sprzętowych znajdziesz w ich dokumentacji.
Kompromisy
Optymalizacje mogą potencjalnie powodować zmiany w dokładności modelu, które należy uwzględnić podczas procesu tworzenia aplikacji.
Zmiany dokładności zależą od optymalizowanego modelu i trudno je przewidzieć. Zazwyczaj modele zoptymalizowane pod kątem rozmiaru lub opóźnienia tracą niewielką część dokładności. W zależności od aplikacji może to mieć wpływ na wrażenia użytkowników. W rzadkich przypadkach niektóre modele mogą zyskać na dokładności w wyniku procesu optymalizacji.
Rodzaje optymalizacji
LiteRT obsługuje obecnie optymalizację za pomocą kwantyzacji, przycinania i klastrowania.
Są one częścią TensorFlow Model Optimization Toolkit, który udostępnia zasoby dotyczące technik optymalizacji modeli zgodnych z TensorFlow Lite.
Kwantyzacja
Kwantyzacja polega na zmniejszeniu precyzji liczb używanych do reprezentowania parametrów modelu, które domyślnie są 32-bitowymi liczbami zmiennoprzecinkowymi. Dzięki temu model jest mniejszy i obliczenia są szybsze.
W LiteRT dostępne są te typy kwantyzacji:
| Metoda | Wymagania dotyczące danych | Zmniejszanie rozmiaru | Dokładność | Obsługiwany sprzęt |
|---|---|---|---|---|
| Kwantyzacja po trenowaniu w formacie float16 | Brak danych | Do 50% | Nieistotna utrata dokładności | CPU, GPU |
| Kwantyzacja zakresu dynamicznego po wytrenowaniu | Brak danych | Maksymalnie 75% | Najmniejsza utrata dokładności | CPU, GPU (Android) |
| Kwantyzacja liczb całkowitych po trenowaniu | Nieoznakowana próbka reprezentatywna | Maksymalnie 75% | niewielka utrata dokładności; | CPU, GPU (Android), EdgeTPU |
| Trenowanie z uwzględnieniem kwantyzacji | Dane treningowe z etykietami | Maksymalnie 75% | Najmniejsza utrata dokładności | CPU, GPU (Android), EdgeTPU |
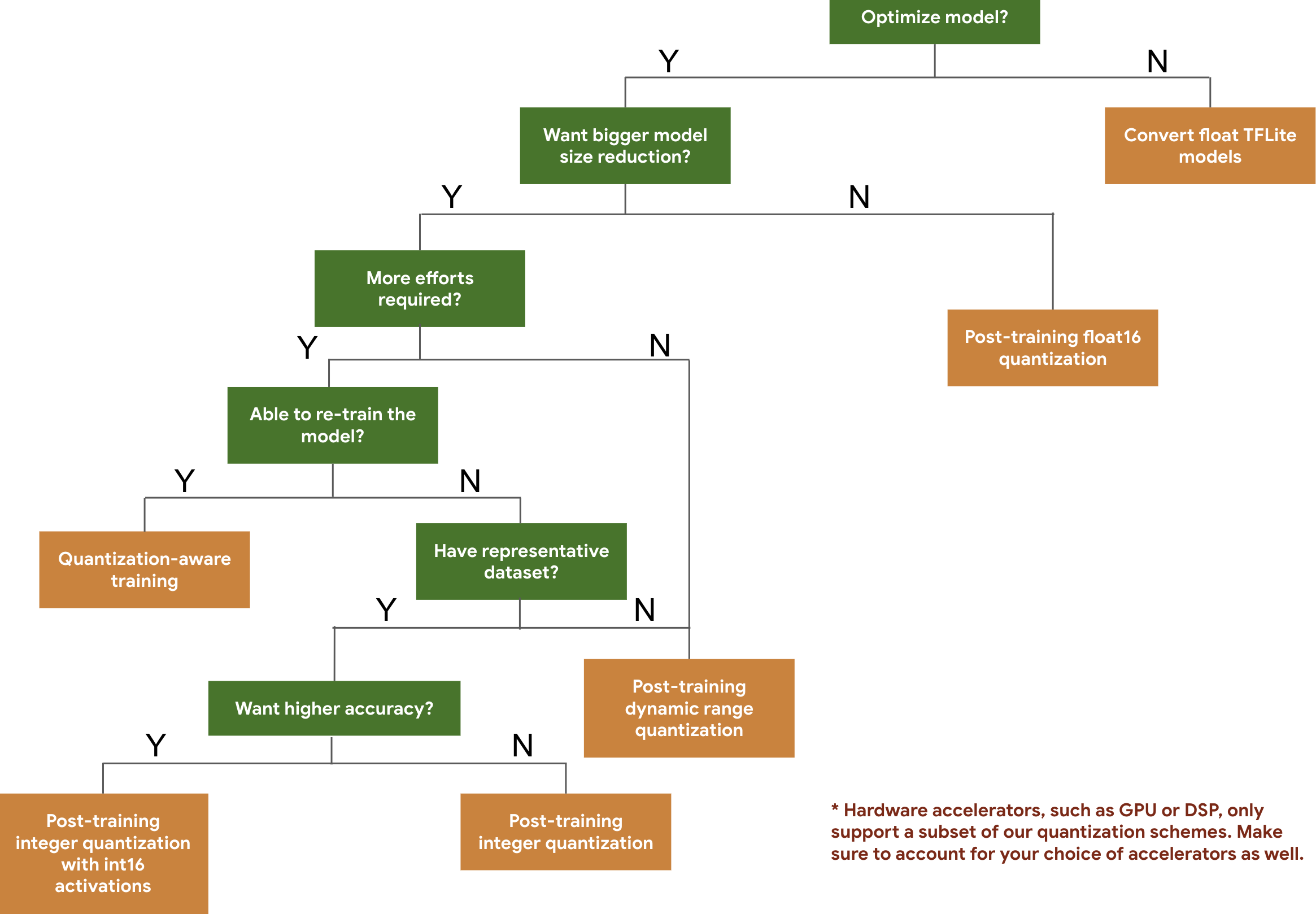
Poniższy schemat decyzyjny pomoże Ci wybrać schematy kwantyzacji, których możesz użyć w swoim modelu, na podstawie oczekiwanej wielkości i dokładności modelu.
Poniżej znajdziesz wyniki dotyczące opóźnienia i dokładności w przypadku kwantyzacji po trenowaniu i trenowania z uwzględnieniem kwantyzacji w kilku modelach. Wszystkie wartości opóźnienia są mierzone na urządzeniach Pixel 2 z użyciem jednego dużego rdzenia procesora. Wraz z ulepszaniem zestawu narzędzi będą się zmieniać te liczby:
| Model | Dokładność Top-1 (oryginalna) | Dokładność Top-1 (po kwantyzacji po trenowaniu) | Dokładność Top-1 (trenowanie z uwzględnieniem kwantyzacji) | Oczekiwanie (oryginalne) (ms) | Oczekiwanie (po kwantyzacji po trenowaniu) (ms) | Oczekiwanie (szkolenie z uwzględnieniem kwantyzacji) (ms) | Rozmiar (oryginalny) (MB) | Rozmiar (zoptymalizowany) (MB) |
|---|---|---|---|---|---|---|---|---|
| Mobilenet-v1-1-224 | 0,709 | 0.657 | 0,70 | 124 | 112 | 64 | 16,9 | 4,3 |
| Mobilenet-v2-1-224 | 0.719 | 0,637 | 0,709 | 89 | 98 | 54 | 14 | 3.6 |
| Inception_v3 | 0,78 | 0.772 | 0,775 | 1130 | 845 | 543 | 95,7 | 23,9 |
| Resnet_v2_101 | 0,770 | 0.768 | Nie dotyczy | 3973 | 2868 | Nie dotyczy | 178,3 | 44,9 |
Pełna kwantyzacja liczb całkowitych z aktywacjami int16 i wagami int8
Kwantyzacja z aktywacjami int16 to pełny schemat kwantyzacji liczb całkowitych z aktywacjami w formacie int16 i wagami w formacie int8. Ten tryb może poprawić dokładność skwantyzowanego modelu w porównaniu ze schematem kwantyzacji pełnych liczb całkowitych, w którym zarówno aktywacje, jak i wagi są w formacie int8, przy zachowaniu podobnego rozmiaru modelu. Jest zalecana, gdy aktywacje są wrażliwe na kwantyzację.
UWAGA: w TFLite są obecnie dostępne tylko nieoptymalizowane implementacje jądra referencyjnego dla tego schematu kwantyzacji, więc domyślnie wydajność będzie niska w porównaniu z jądrami int8. Pełne korzyści z tego trybu można obecnie uzyskać za pomocą specjalistycznego sprzętu lub niestandardowego oprogramowania.
Poniżej znajdziesz wyniki dokładności niektórych modeli, które korzystają z tego trybu.
| Model | Typ danych Dokładność | Dokładność (aktywacje float32) | Dokładność (aktywacje int8) | Dokładność (aktywacje int16) |
|---|---|---|---|---|
| Wav2letter | WER | 6,7% | 7,7% | 7,2% |
| DeepSpeech 0.5.1 (unrolled) | CER | 6,13% | 43,67% | 6,52% |
| YoloV3 | mAP(IOU=0.5) | 0,577 | 0,563 | 0.574 |
| MobileNetV1 | Dokładność Top-1 | 0,7062 | 0,694 | 0,6936 |
| MobileNetV2 | Dokładność Top-1 | 0.718 | 0.7126 | 0,7137 |
| MobileBert | F1(dopasowanie ścisłe) | 88,81(81,23) | 2,08(0) | 88,73(81,15) |
Przycinanie
Przycinanie polega na usuwaniu z modelu parametrów, które mają tylko niewielki wpływ na jego prognozy. Modele przycięte mają taki sam rozmiar na dysku i takie samo opóźnienie w czasie działania, ale można je skuteczniej kompresować. Dzięki temu przycinanie jest przydatną techniką zmniejszania rozmiaru pobierania modelu.
W przyszłości LiteRT będzie zmniejszać opóźnienia w przypadku przyciętych modeli.
Grupowanie
Klastrowanie polega na grupowaniu wag każdej warstwy w modelu w określoną liczbę klastrów, a następnie udostępnianiu wartości centroidów wag należących do poszczególnych klastrów. Zmniejsza to liczbę unikalnych wartości wag w modelu, a tym samym jego złożoność.
Dzięki temu modele klastrowe można skuteczniej kompresować, co daje podobne korzyści w zakresie wdrażania jak przycinanie.
Przepływ pracy w programowaniu
Na początek sprawdź, czy modele w modelach hostowanych mogą być używane w Twojej aplikacji. Jeśli nie, zalecamy rozpoczęcie od narzędzia do kwantyzacji po trenowaniu, ponieważ ma ono szerokie zastosowanie i nie wymaga danych treningowych.
W przypadku, gdy nie są spełnione wymagania dotyczące dokładności i opóźnienia lub gdy ważne jest wsparcie akceleratora sprzętowego, lepszym rozwiązaniem jest trenowanie z uwzględnieniem kwantyzacji. Dodatkowe techniki optymalizacji znajdziesz w zestawie narzędzi TensorFlow Model Optimization.
Jeśli chcesz jeszcze bardziej zmniejszyć rozmiar modelu, przed kwantyzacją możesz spróbować przycinania lub klastrowania.