
Les opérateurs de machine learning (ML) que vous utilisez dans votre modèle peuvent avoir un impact sur le processus de conversion d'un modèle TensorFlow au format LiteRT. Le convertisseur LiteRT est compatible avec un nombre limité d'opérations TensorFlow utilisées dans les modèles d'inférence courants, ce qui signifie que tous les modèles ne sont pas directement convertibles. L'outil de conversion vous permet d'inclure des opérateurs supplémentaires, mais la conversion d'un modèle de cette manière vous oblige également à modifier l'environnement d'exécution LiteRT que vous utilisez pour exécuter votre modèle. Cela peut limiter votre capacité à utiliser des options de déploiement d'exécution standard, telles que les services Google Play.
Le convertisseur LiteRT est conçu pour analyser la structure du modèle et appliquer des optimisations afin de le rendre compatible avec les opérateurs directement pris en charge. Par exemple, en fonction des opérateurs de ML de votre modèle, le convertisseur peut élider ou fusionner ces opérateurs afin de les mapper à leurs équivalents LiteRT.
Même pour les opérations compatibles, des schémas d'utilisation spécifiques sont parfois attendus pour des raisons de performances. Pour comprendre comment créer un modèle TensorFlow utilisable avec LiteRT, il est important d'examiner attentivement la façon dont les opérations sont converties et optimisées, ainsi que les limites imposées par ce processus.
Opérateurs compatibles
Les opérateurs intégrés LiteRT sont un sous-ensemble des opérateurs qui font partie de la bibliothèque principale TensorFlow. Votre modèle TensorFlow peut également inclure des opérateurs personnalisés sous la forme d'opérateurs composites ou de nouveaux opérateurs que vous avez définis. Le schéma ci-dessous illustre les relations entre ces opérateurs.
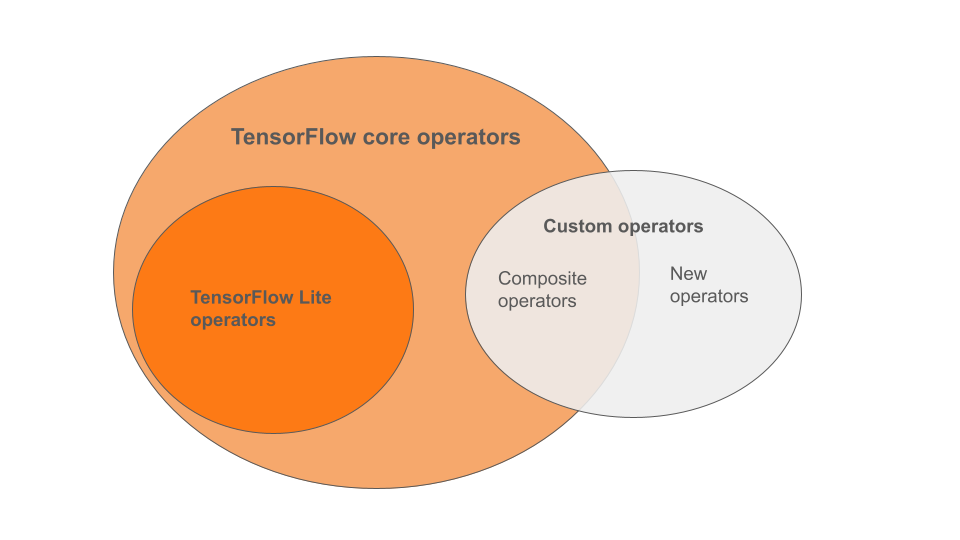
Parmi cette gamme d'opérateurs de modèles de ML, trois types de modèles sont compatibles avec le processus de conversion :
- Modèles avec uniquement l'opérateur LiteRT intégré. (Recommandé)
- Modèles avec les opérateurs intégrés et certains opérateurs TensorFlow Core.
- Modèles avec des opérateurs intégrés, des opérateurs TensorFlow Core et/ou des opérateurs personnalisés.
Si votre modèle ne contient que des opérations compatibles de manière native avec LiteRT, vous n'avez besoin d'aucun indicateur supplémentaire pour le convertir. Il s'agit du chemin recommandé, car ce type de modèle se convertit facilement et est plus simple à optimiser et à exécuter à l'aide du runtime LiteRT par défaut. Vous disposez également de plus d'options de déploiement pour votre modèle, comme les services Google Play. Pour commencer, consultez le guide du convertisseur LiteRT. Consultez la page sur les opérations LiteRT pour obtenir la liste des opérateurs intégrés.
Si vous devez inclure certaines opérations TensorFlow de la bibliothèque principale, vous devez le spécifier lors de la conversion et vous assurer que votre environnement d'exécution inclut ces opérations. Pour obtenir des instructions détaillées, consultez la section Sélectionner des opérateurs TensorFlow.
Dans la mesure du possible, évitez la dernière option qui consiste à inclure des opérateurs personnalisés dans votre modèle converti. Les opérateurs personnalisés sont des opérateurs créés en combinant plusieurs opérateurs TensorFlow Core primitifs ou en définissant un opérateur entièrement nouveau. Lorsque des opérateurs personnalisés sont convertis, ils peuvent augmenter la taille globale du modèle en entraînant des dépendances en dehors de la bibliothèque LiteRT intégrée. Les opérations personnalisées, si elles ne sont pas spécifiquement créées pour le déploiement sur mobile ou sur un appareil, peuvent entraîner des performances moins bonnes lorsqu'elles sont déployées sur des appareils aux ressources limitées par rapport à un environnement de serveur. Enfin, tout comme l'inclusion de certains opérateurs TensorFlow Core, les opérateurs personnalisés vous obligent à modifier l'environnement d'exécution du modèle, ce qui vous empêche de profiter des services d'exécution standards tels que les services Google Play.
Types acceptés
La plupart des opérations LiteRT ciblent l'inférence à virgule flottante (float32) et quantifiée (uint8, int8), mais de nombreuses opérations ne le font pas encore pour d'autres types tels que tf.float16 et les chaînes.
Outre l'utilisation de différentes versions des opérations, la différence entre les modèles à virgule flottante et quantifiés réside dans la façon dont ils sont convertis. La conversion quantifiée nécessite des informations sur la plage dynamique pour les Tensors. Cela nécessite une "fausse quantification" lors de l'entraînement du modèle, l'obtention d'informations sur la plage via un ensemble de données de calibration ou l'estimation de la plage "à la volée". Pour en savoir plus, consultez Quantification.
Conversions simples, pliage et fusion constants
LiteRT peut traiter un certain nombre d'opérations TensorFlow, même si elles n'ont pas d'équivalent direct. C'est le cas pour les opérations qui peuvent être simplement supprimées du graphique (tf.identity), remplacées par des Tensors (tf.placeholder) ou fusionnées dans des opérations plus complexes (tf.nn.bias_add). Même certaines opérations compatibles peuvent parfois être supprimées par l'un de ces processus.
Voici une liste non exhaustive des opérations TensorFlow qui sont généralement supprimées du graphique :
tf.addtf.debugging.check_numericstf.constanttf.divtf.dividetf.fake_quant_with_min_max_argstf.fake_quant_with_min_max_varstf.identitytf.maximumtf.minimumtf.multiplytf.no_optf.placeholdertf.placeholder_with_defaulttf.realdivtf.reduce_maxtf.reduce_mintf.reduce_sumtf.rsqrttf.shapetf.sqrttf.squaretf.subtracttf.tiletf.nn.batch_norm_with_global_normalizationtf.nn.bias_addtf.nn.fused_batch_normtf.nn.relutf.nn.relu6
Opérations expérimentales
Les opérations LiteRT suivantes sont présentes, mais ne sont pas prêtes pour les modèles personnalisés :
CALLCONCAT_EMBEDDINGSCUSTOMEMBEDDING_LOOKUP_SPARSEHASHTABLE_LOOKUPLSH_PROJECTIONSKIP_GRAMSVDF