
| | |  GitHub-এ উৎস দেখুন GitHub-এ উৎস দেখুন |
ওভারভিউ
এই টিউটোরিয়ালটি দেখায় কিভাবে জেমিনি এপিআই থেকে এমবেডিংয়ের সাথে ক্লাস্টারিংকে কল্পনা করতে এবং সঞ্চালন করতে হয়। আপনি T-SNE ব্যবহার করে 20টি নিউজগ্রুপ ডেটাসেটের একটি উপসেট কল্পনা করবেন এবং KMeans অ্যালগরিদম ব্যবহার করে উপসেট ক্লাস্টার।
Gemini API থেকে জেনারেট করা এম্বেডিংয়ের সাথে শুরু করার বিষয়ে আরও তথ্যের জন্য, Python quickstart দেখুন।
পূর্বশর্ত
আপনি Google Colab-এ এই কুইকস্টার্ট চালাতে পারেন।
আপনার নিজের বিকাশের পরিবেশে এই দ্রুত সূচনাটি সম্পূর্ণ করতে, নিশ্চিত করুন যে আপনার পরিবেশ নিম্নলিখিত প্রয়োজনীয়তাগুলি পূরণ করে:
- Python 3.9+
- নোটবুক চালানোর জন্য
jupyterএকটি ইনস্টলেশন।
সেটআপ
প্রথমে, জেমিনি API পাইথন লাইব্রেরি ডাউনলোড এবং ইনস্টল করুন।
pip install -U -q google.generativeai
import re
import tqdm
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import google.generativeai as genai
import google.ai.generativelanguage as glm
# Used to securely store your API key
from google.colab import userdata
from sklearn.datasets import fetch_20newsgroups
from sklearn.manifold import TSNE
from sklearn.cluster import KMeans
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
একটি API কী ধরুন
আপনি Gemini API ব্যবহার করার আগে, আপনাকে প্রথমে একটি API কী পেতে হবে। যদি আপনার কাছে ইতিমধ্যে একটি না থাকে তবে Google AI স্টুডিওতে এক ক্লিকে একটি কী তৈরি করুন৷
Colab-এ, বাঁদিকের প্যানেলে "🔑"-এর নিচে সিক্রেট ম্যানেজারের কী যোগ করুন। এটিকে API_KEY নাম দিন।
একবার আপনার কাছে API কী হয়ে গেলে, এটি SDK-এ পাস করুন। আপনি এটি দুটি উপায়ে করতে পারেন:
- কীটি
GOOGLE_API_KEYএনভায়রনমেন্ট ভেরিয়েবলে রাখুন (SDK স্বয়ংক্রিয়ভাবে সেখান থেকে তুলে নেবে)। -
genai.configure(api_key=...)এ কী পাস করুন
# Or use `os.getenv('API_KEY')` to fetch an environment variable.
API_KEY=userdata.get('API_KEY')
genai.configure(api_key=API_KEY)
for m in genai.list_models():
if 'embedContent' in m.supported_generation_methods:
print(m.name)
models/embedding-001 models/embedding-001
ডেটাসেট
20টি নিউজগ্রুপ টেক্সট ডেটাসেটে 20টি বিষয়ের উপর 18,000টি নিউজগ্রুপ পোস্ট রয়েছে যা প্রশিক্ষণ এবং পরীক্ষার সেটে বিভক্ত। প্রশিক্ষণ এবং পরীক্ষার ডেটাসেটের মধ্যে বিভাজন একটি নির্দিষ্ট তারিখের আগে এবং পরে পোস্ট করা বার্তাগুলির উপর ভিত্তি করে। এই টিউটোরিয়ালের জন্য, আপনি প্রশিক্ষণ উপসেট ব্যবহার করবেন।
newsgroups_train = fetch_20newsgroups(subset='train')
# View list of class names for dataset
newsgroups_train.target_names
['alt.atheism', 'comp.graphics', 'comp.os.ms-windows.misc', 'comp.sys.ibm.pc.hardware', 'comp.sys.mac.hardware', 'comp.windows.x', 'misc.forsale', 'rec.autos', 'rec.motorcycles', 'rec.sport.baseball', 'rec.sport.hockey', 'sci.crypt', 'sci.electronics', 'sci.med', 'sci.space', 'soc.religion.christian', 'talk.politics.guns', 'talk.politics.mideast', 'talk.politics.misc', 'talk.religion.misc']
এখানে প্রশিক্ষণ সেট প্রথম উদাহরণ.
idx = newsgroups_train.data[0].index('Lines')
print(newsgroups_train.data[0][idx:])
Lines: 15 I was wondering if anyone out there could enlighten me on this car I saw the other day. It was a 2-door sports car, looked to be from the late 60s/ early 70s. It was called a Bricklin. The doors were really small. In addition, the front bumper was separate from the rest of the body. This is all I know. If anyone can tellme a model name, engine specs, years of production, where this car is made, history, or whatever info you have on this funky looking car, please e-mail. Thanks, - IL ---- brought to you by your neighborhood Lerxst ----
# Apply functions to remove names, emails, and extraneous words from data points in newsgroups.data
newsgroups_train.data = [re.sub(r'[\w\.-]+@[\w\.-]+', '', d) for d in newsgroups_train.data] # Remove email
newsgroups_train.data = [re.sub(r"\([^()]*\)", "", d) for d in newsgroups_train.data] # Remove names
newsgroups_train.data = [d.replace("From: ", "") for d in newsgroups_train.data] # Remove "From: "
newsgroups_train.data = [d.replace("\nSubject: ", "") for d in newsgroups_train.data] # Remove "\nSubject: "
# Put training points into a dataframe
df_train = pd.DataFrame(newsgroups_train.data, columns=['Text'])
df_train['Label'] = newsgroups_train.target
# Match label to target name index
df_train['Class Name'] = df_train['Label'].map(newsgroups_train.target_names.__getitem__)
# Retain text samples that can be used in the gecko model.
df_train = df_train[df_train['Text'].str.len() < 10000]
df_train
এরপর, আপনি প্রশিক্ষণ ডেটাসেটে 100টি ডেটা পয়েন্ট নিয়ে এবং এই টিউটোরিয়ালটি চালানোর জন্য কয়েকটি বিভাগ বাদ দিয়ে কিছু ডেটার নমুনা নেবেন। তুলনা করার জন্য বিজ্ঞান বিভাগগুলি বেছে নিন।
# Take a sample of each label category from df_train
SAMPLE_SIZE = 150
df_train = (df_train.groupby('Label', as_index = False)
.apply(lambda x: x.sample(SAMPLE_SIZE))
.reset_index(drop=True))
# Choose categories about science
df_train = df_train[df_train['Class Name'].str.contains('sci')]
# Reset the index
df_train = df_train.reset_index()
df_train
df_train['Class Name'].value_counts()
sci.crypt 150 sci.electronics 150 sci.med 150 sci.space 150 Name: Class Name, dtype: int64
এমবেডিং তৈরি করুন
এই বিভাগে, আপনি জেমিনি API থেকে এমবেডিংগুলি ব্যবহার করে ডেটাফ্রেমের বিভিন্ন পাঠ্যের জন্য এমবেডিংগুলি কীভাবে তৈরি করবেন তা দেখতে পাবেন।
মডেল এমবেডিং-001 সহ এম্বেডিং-এ API পরিবর্তন হয়
নতুন এম্বেডিং মডেলের জন্য, এম্বেডিং-001, একটি নতুন টাস্ক টাইপ প্যারামিটার এবং ঐচ্ছিক শিরোনাম রয়েছে (শুধুমাত্র task_type= RETRIEVAL_DOCUMENT এর সাথে বৈধ)।
এই নতুন প্যারামিটারগুলি শুধুমাত্র নতুন এমবেডিং মডেলগুলিতে প্রযোজ্য৷ টাস্কের ধরনগুলি হল:
| টাস্ক টাইপ | বর্ণনা |
|---|---|
| RETRIEVAL_QUERY | প্রদত্ত টেক্সট একটি অনুসন্ধান/পুনরুদ্ধার সেটিং একটি ক্যোয়ারী নির্দিষ্ট করে. |
| RETRIEVAL_DOCUMENT | প্রদত্ত পাঠ্যটি একটি অনুসন্ধান/পুনরুদ্ধার সেটিং এর একটি নথি নির্দিষ্ট করে৷ |
| SEMANTIC_SIMILARITY | প্রদত্ত টেক্সট শব্দার্থিক টেক্সচুয়াল সাদৃশ্য (STS) এর জন্য ব্যবহার করা হবে তা নির্দিষ্ট করে। |
| শ্রেণীবিভাগ | নির্দিষ্ট করে যে এমবেডিংগুলি শ্রেণীবিভাগের জন্য ব্যবহার করা হবে৷ |
| ক্লাস্টারিং | নির্দিষ্ট করে যে এমবেডিংগুলি ক্লাস্টারিংয়ের জন্য ব্যবহার করা হবে৷ |
from tqdm.auto import tqdm
tqdm.pandas()
from google.api_core import retry
def make_embed_text_fn(model):
@retry.Retry(timeout=300.0)
def embed_fn(text: str) -> list[float]:
# Set the task_type to CLUSTERING.
embedding = genai.embed_content(model=model,
content=text,
task_type="clustering")
return embedding["embedding"]
return embed_fn
def create_embeddings(df):
model = 'models/embedding-001'
df['Embeddings'] = df['Text'].progress_apply(make_embed_text_fn(model))
return df
df_train = create_embeddings(df_train)
0%| | 0/600 [00:00<?, ?it/s]
মাত্রিকতা হ্রাস
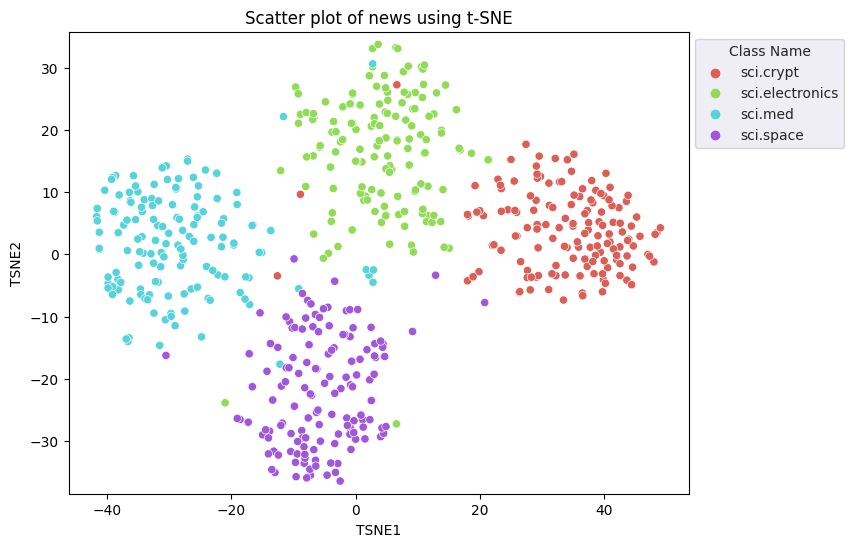
নথি এমবেডিং ভেক্টরের দৈর্ঘ্য হল 768৷ এমবেড করা নথিগুলিকে কীভাবে একত্রিত করা হয়েছে তা কল্পনা করার জন্য, আপনাকে মাত্রিকতা হ্রাস প্রয়োগ করতে হবে কারণ আপনি কেবলমাত্র 2D বা 3D স্পেসে এমবেডিংগুলিকে কল্পনা করতে পারেন৷ প্রাসঙ্গিকভাবে অনুরূপ নথিগুলি মহাকাশে একত্রে কাছাকাছি হওয়া উচিত নথিগুলির বিপরীতে যা অনুরূপ নয়।
len(df_train['Embeddings'][0])
768
# Convert df_train['Embeddings'] Pandas series to a np.array of float32
X = np.array(df_train['Embeddings'].to_list(), dtype=np.float32)
X.shape
(600, 768)
ডাইমেনশ্যালিটি রিডাকশন করার জন্য আপনি টি-ডিস্ট্রিবিউটেড স্টোকাস্টিক নেবার এম্বেডিং (t-SNE) পদ্ধতি প্রয়োগ করবেন। ক্লাস্টারগুলি সংরক্ষণ করার সময় এই কৌশলটি মাত্রার সংখ্যা হ্রাস করে (বিন্দু যেগুলি একত্রে কাছাকাছি থাকে তারা একসাথে থাকে)। আসল ডেটার জন্য, মডেলটি এমন একটি ডিস্ট্রিবিউশন তৈরি করার চেষ্টা করে যার উপর অন্যান্য ডেটা পয়েন্টগুলি "প্রতিবেশী" (যেমন, তারা একই অর্থ ভাগ করে)। এটি তারপর একটি উদ্দেশ্য ফাংশন অপ্টিমাইজ করে ভিজ্যুয়ালাইজেশনে একটি অনুরূপ বিতরণ রাখতে।
tsne = TSNE(random_state=0, n_iter=1000)
tsne_results = tsne.fit_transform(X)
df_tsne = pd.DataFrame(tsne_results, columns=['TSNE1', 'TSNE2'])
df_tsne['Class Name'] = df_train['Class Name'] # Add labels column from df_train to df_tsne
df_tsne
fig, ax = plt.subplots(figsize=(8,6)) # Set figsize
sns.set_style('darkgrid', {"grid.color": ".6", "grid.linestyle": ":"})
sns.scatterplot(data=df_tsne, x='TSNE1', y='TSNE2', hue='Class Name', palette='hls')
sns.move_legend(ax, "upper left", bbox_to_anchor=(1, 1))
plt.title('Scatter plot of news using t-SNE');
plt.xlabel('TSNE1');
plt.ylabel('TSNE2');
plt.axis('equal')
(-46.191162300109866, 53.521015357971194, -39.96646995544434, 37.282975387573245)
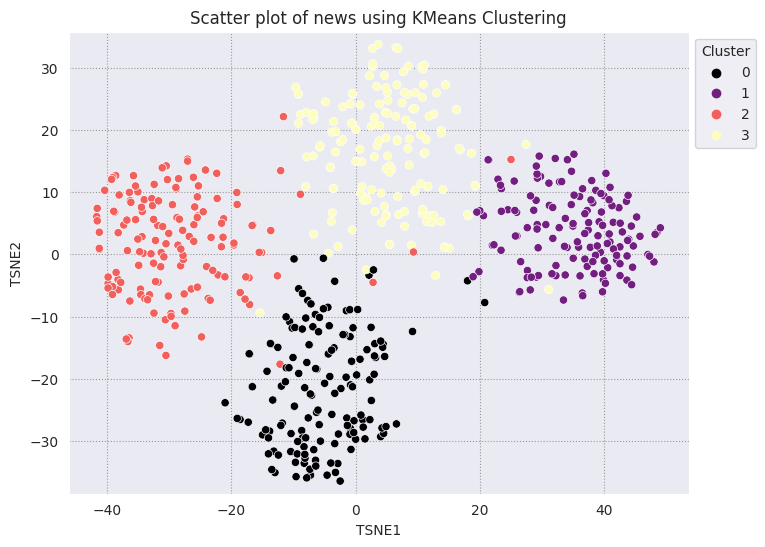
KMeans-এর সাথে ফলাফলের তুলনা করুন
KMeans ক্লাস্টারিং হল একটি জনপ্রিয় ক্লাস্টারিং অ্যালগরিদম এবং প্রায়ই তত্ত্বাবধানহীন শিক্ষার জন্য ব্যবহৃত হয়। এটি পুনরাবৃত্তভাবে সেরা কে কেন্দ্র বিন্দু নির্ধারণ করে এবং প্রতিটি উদাহরণকে নিকটতম কেন্দ্রে বরাদ্দ করে। একটি মেশিন লার্নিং অ্যালগরিদমের পারফরম্যান্সের সাথে এমবেডিংয়ের ভিজ্যুয়ালাইজেশন তুলনা করতে সরাসরি KMeans অ্যালগরিদমে এম্বেডিংগুলি ইনপুট করুন।
# Apply KMeans
kmeans_model = KMeans(n_clusters=4, random_state=1, n_init='auto').fit(X)
labels = kmeans_model.fit_predict(X)
df_tsne['Cluster'] = labels
df_tsne
fig, ax = plt.subplots(figsize=(8,6)) # Set figsize
sns.set_style('darkgrid', {"grid.color": ".6", "grid.linestyle": ":"})
sns.scatterplot(data=df_tsne, x='TSNE1', y='TSNE2', hue='Cluster', palette='magma')
sns.move_legend(ax, "upper left", bbox_to_anchor=(1, 1))
plt.title('Scatter plot of news using KMeans Clustering');
plt.xlabel('TSNE1');
plt.ylabel('TSNE2');
plt.axis('equal')
(-46.191162300109866, 53.521015357971194, -39.96646995544434, 37.282975387573245)
def get_majority_cluster_per_group(df_tsne_cluster, class_names):
class_clusters = dict()
for c in class_names:
# Get rows of dataframe that are equal to c
rows = df_tsne_cluster.loc[df_tsne_cluster['Class Name'] == c]
# Get majority value in Cluster column of the rows selected
cluster = rows.Cluster.mode().values[0]
# Populate mapping dictionary
class_clusters[c] = cluster
return class_clusters
classes = df_tsne['Class Name'].unique()
class_clusters = get_majority_cluster_per_group(df_tsne, classes)
class_clusters
{'sci.crypt': 1, 'sci.electronics': 3, 'sci.med': 2, 'sci.space': 0}
প্রতি গ্রুপের সংখ্যাগরিষ্ঠ ক্লাস্টার পান, এবং সেই ক্লাস্টারে সেই গোষ্ঠীর কতজন প্রকৃত সদস্য রয়েছে তা দেখুন।
# Convert the Cluster column to use the class name
class_by_id = {v: k for k, v in class_clusters.items()}
df_tsne['Predicted'] = df_tsne['Cluster'].map(class_by_id.__getitem__)
# Filter to the correctly matched rows
correct = df_tsne[df_tsne['Class Name'] == df_tsne['Predicted']]
# Summarise, as a percentage
acc = correct['Class Name'].value_counts() / SAMPLE_SIZE
acc
sci.space 0.966667 sci.med 0.960000 sci.electronics 0.953333 sci.crypt 0.926667 Name: Class Name, dtype: float64
# Get predicted values by name
df_tsne['Predicted'] = ''
for idx, rows in df_tsne.iterrows():
cluster = rows['Cluster']
# Get key from mapping based on cluster value
key = list(class_clusters.keys())[list(class_clusters.values()).index(cluster)]
df_tsne.at[idx, 'Predicted'] = key
df_tsne
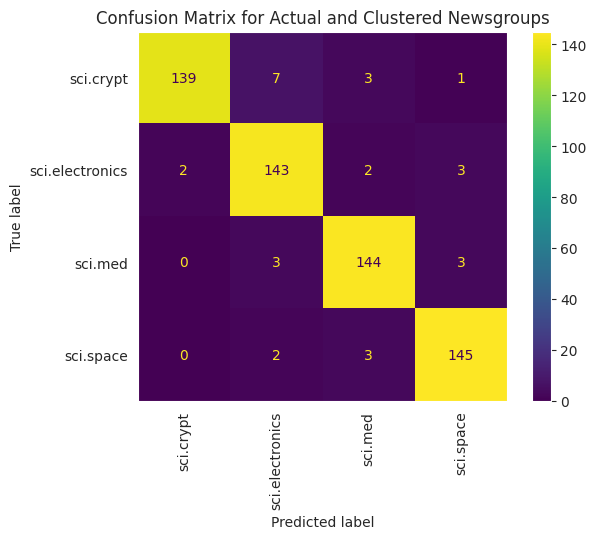
আপনার ডেটাতে প্রয়োগ করা KMeans-এর কর্মক্ষমতা আরও ভালভাবে কল্পনা করতে, আপনি একটি কনফিউশন ম্যাট্রিক্স ব্যবহার করতে পারেন। বিভ্রান্তি ম্যাট্রিক্স আপনাকে নির্ভুলতার বাইরে শ্রেণীবিভাগ মডেলের কার্যকারিতা মূল্যায়ন করতে দেয়। আপনি দেখতে পারেন কি ভুল শ্রেণীবদ্ধ পয়েন্ট হিসাবে শ্রেণীবদ্ধ করা হয়. আপনার প্রকৃত মান এবং পূর্বাভাসিত মানগুলির প্রয়োজন হবে, যা আপনি উপরের ডেটাফ্রেমে সংগ্রহ করেছেন।
cm = confusion_matrix(df_tsne['Class Name'].to_list(), df_tsne['Predicted'].to_list())
disp = ConfusionMatrixDisplay(confusion_matrix=cm,
display_labels=classes)
disp.plot(xticks_rotation='vertical')
plt.title('Confusion Matrix for Actual and Clustered Newsgroups');
plt.grid(False)
পরবর্তী পদক্ষেপ
আপনি এখন ক্লাস্টারিংয়ের সাথে এম্বেডিংয়ের নিজস্ব ভিজ্যুয়ালাইজেশন তৈরি করেছেন! এম্বেডিং হিসাবে তাদের কল্পনা করতে আপনার নিজস্ব পাঠ্য ডেটা ব্যবহার করার চেষ্টা করুন। ভিজ্যুয়ালাইজেশন ধাপ সম্পূর্ণ করার জন্য আপনি মাত্রিকতা হ্রাস করতে পারেন। নোট করুন যে TSNE ক্লাস্টারিং ইনপুটগুলিতে ভাল, তবে একত্রিত হতে বেশি সময় নিতে পারে বা স্থানীয় মিনিমাতে আটকে যেতে পারে। আপনি যদি এই সমস্যায় পড়েন, তাহলে আরেকটি কৌশল যা আপনি বিবেচনা করতে পারেন তা হল প্রধান উপাদান বিশ্লেষণ (PCA) ।
KMeans-এর বাইরেও অন্যান্য ক্লাস্টারিং অ্যালগরিদম রয়েছে, যেমন ঘনত্ব-ভিত্তিক স্থানিক ক্লাস্টারিং (DBSCAN) ।
Gemini API-এ অন্যান্য পরিষেবাগুলি কীভাবে ব্যবহার করবেন তা জানতে, Python quickstart-এ যান। আপনি কীভাবে এমবেডিং ব্যবহার করতে পারেন সে সম্পর্কে আরও জানতে, উপলব্ধ উদাহরণগুলি দেখুন। স্ক্র্যাচ থেকে কীভাবে সেগুলি তৈরি করবেন তা শিখতে, টেনসরফ্লো-এর ওয়ার্ড এমবেডিংস টিউটোরিয়াল দেখুন।