
|
|
|
 Xem nguồn trên GitHub Xem nguồn trên GitHub
|
Tổng quan
Hướng dẫn này minh hoạ cách trực quan hoá và thực hiện việc phân cụm bằng các nội dung nhúng từ API Gemini. Bạn sẽ trực quan hoá một tập hợp con của tập dữ liệu 20 Newsgroup bằng t-SNE và phân cụm tập hợp con đó bằng thuật toán KMeans.
Để biết thêm thông tin về cách bắt đầu với những tính năng nhúng được tạo từ API Gemini, hãy xem phần hướng dẫn bắt đầu nhanh về Python.
Điều kiện tiên quyết
Bạn có thể chạy quy trình hướng dẫn nhanh này trong Google Colab.
Để hoàn tất quá trình bắt đầu nhanh này trên môi trường phát triển của riêng bạn, hãy đảm bảo rằng môi trường của bạn đáp ứng các yêu cầu sau:
- Python 3.9 trở lên
- Cài đặt
jupyterđể chạy sổ tay.
Thiết lập
Trước tiên, hãy tải xuống và cài đặt thư viện Gemini API Python.
pip install -U -q google.generativeai
import re
import tqdm
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import google.generativeai as genai
import google.ai.generativelanguage as glm
# Used to securely store your API key
from google.colab import userdata
from sklearn.datasets import fetch_20newsgroups
from sklearn.manifold import TSNE
from sklearn.cluster import KMeans
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
Lấy khoá API
Để có thể sử dụng API Gemini, trước tiên, bạn phải có được khoá API. Nếu bạn chưa có khoá, hãy tạo khoá chỉ bằng một lần nhấp trong Google AI Studio.
Trong Colab, hãy thêm khoá vào trình quản lý khoá bí mật trong mục "🔑" trên bảng điều khiển bên trái. Đặt tên cho API_KEY.
Sau khi bạn có khoá API, hãy truyền khoá đó vào SDK. Bạn có thể làm điều này theo hai cách:
- Đặt khoá vào biến môi trường
GOOGLE_API_KEY(SDK sẽ tự động nhận khoá từ đó). - Truyền khoá đến
genai.configure(api_key=...)
# Or use `os.getenv('API_KEY')` to fetch an environment variable.
API_KEY=userdata.get('API_KEY')
genai.configure(api_key=API_KEY)
for m in genai.list_models():
if 'embedContent' in m.supported_generation_methods:
print(m.name)
models/embedding-001 models/embedding-001
Tập dữ liệu
20 Tập dữ liệu văn bản về nhóm tin chứa 18.000 bài đăng về nhóm tin tức về 20 chủ đề,được chia thành các bộ huấn luyện và kiểm thử. Sự phân chia giữa tập dữ liệu huấn luyện và tập dữ liệu kiểm tra dựa trên các thông báo đăng trước và sau một ngày cụ thể. Trong hướng dẫn này, bạn sẽ sử dụng tập hợp con huấn luyện.
newsgroups_train = fetch_20newsgroups(subset='train')
# View list of class names for dataset
newsgroups_train.target_names
['alt.atheism', 'comp.graphics', 'comp.os.ms-windows.misc', 'comp.sys.ibm.pc.hardware', 'comp.sys.mac.hardware', 'comp.windows.x', 'misc.forsale', 'rec.autos', 'rec.motorcycles', 'rec.sport.baseball', 'rec.sport.hockey', 'sci.crypt', 'sci.electronics', 'sci.med', 'sci.space', 'soc.religion.christian', 'talk.politics.guns', 'talk.politics.mideast', 'talk.politics.misc', 'talk.religion.misc']
Dưới đây là ví dụ đầu tiên trong bộ huấn luyện.
idx = newsgroups_train.data[0].index('Lines')
print(newsgroups_train.data[0][idx:])
Lines: 15 I was wondering if anyone out there could enlighten me on this car I saw the other day. It was a 2-door sports car, looked to be from the late 60s/ early 70s. It was called a Bricklin. The doors were really small. In addition, the front bumper was separate from the rest of the body. This is all I know. If anyone can tellme a model name, engine specs, years of production, where this car is made, history, or whatever info you have on this funky looking car, please e-mail. Thanks, - IL ---- brought to you by your neighborhood Lerxst ----
# Apply functions to remove names, emails, and extraneous words from data points in newsgroups.data
newsgroups_train.data = [re.sub(r'[\w\.-]+@[\w\.-]+', '', d) for d in newsgroups_train.data] # Remove email
newsgroups_train.data = [re.sub(r"\([^()]*\)", "", d) for d in newsgroups_train.data] # Remove names
newsgroups_train.data = [d.replace("From: ", "") for d in newsgroups_train.data] # Remove "From: "
newsgroups_train.data = [d.replace("\nSubject: ", "") for d in newsgroups_train.data] # Remove "\nSubject: "
# Put training points into a dataframe
df_train = pd.DataFrame(newsgroups_train.data, columns=['Text'])
df_train['Label'] = newsgroups_train.target
# Match label to target name index
df_train['Class Name'] = df_train['Label'].map(newsgroups_train.target_names.__getitem__)
# Retain text samples that can be used in the gecko model.
df_train = df_train[df_train['Text'].str.len() < 10000]
df_train
Tiếp theo, bạn sẽ lấy mẫu một số dữ liệu bằng cách lấy 100 điểm dữ liệu trong tập dữ liệu huấn luyện và loại bỏ một vài danh mục để chạy theo hướng dẫn này. Chọn danh mục khoa học để so sánh.
# Take a sample of each label category from df_train
SAMPLE_SIZE = 150
df_train = (df_train.groupby('Label', as_index = False)
.apply(lambda x: x.sample(SAMPLE_SIZE))
.reset_index(drop=True))
# Choose categories about science
df_train = df_train[df_train['Class Name'].str.contains('sci')]
# Reset the index
df_train = df_train.reset_index()
df_train
df_train['Class Name'].value_counts()
sci.crypt 150 sci.electronics 150 sci.med 150 sci.space 150 Name: Class Name, dtype: int64
Tạo các video nhúng
Trong phần này, bạn sẽ tìm hiểu cách tạo nhúng cho nhiều văn bản trong khung dữ liệu bằng cách sử dụng tính năng nhúng từ API Gemini.
Thay đổi API đối với chế độ Nhúng với mô hình nhúng-001
Đối với mô hình nhúng mới, nhúng-001, có một tham số loại tác vụ mới và tiêu đề không bắt buộc (chỉ hợp lệ với task_type=RETRIEVAL_DOCUMENT).
Các thông số mới này chỉ áp dụng cho các mô hình nhúng mới nhất.Các loại tác vụ là:
| Loại việc cần làm | Nội dung mô tả |
|---|---|
| RETRIEVAL_QUERY | Chỉ định văn bản đã cho là truy vấn trong cài đặt tìm kiếm/truy xuất. |
| RETRIEVAL_DOCUMENT | Chỉ định văn bản đã cho là một tài liệu trong cài đặt tìm kiếm/truy xuất. |
| SEMANTIC_SIMILARITY | Chỉ định văn bản đã cho sẽ được dùng cho tính tương đồng về mặt ngữ nghĩa (STS). |
| PHÂN LOẠI | Chỉ định việc các nội dung nhúng sẽ được dùng để phân loại. |
| CỤM | Chỉ định việc các nội dung nhúng sẽ được dùng để phân cụm. |
from tqdm.auto import tqdm
tqdm.pandas()
from google.api_core import retry
def make_embed_text_fn(model):
@retry.Retry(timeout=300.0)
def embed_fn(text: str) -> list[float]:
# Set the task_type to CLUSTERING.
embedding = genai.embed_content(model=model,
content=text,
task_type="clustering")
return embedding["embedding"]
return embed_fn
def create_embeddings(df):
model = 'models/embedding-001'
df['Embeddings'] = df['Text'].progress_apply(make_embed_text_fn(model))
return df
df_train = create_embeddings(df_train)
0%| | 0/600 [00:00<?, ?it/s]
Giảm kích thước
Độ dài của vectơ nhúng tài liệu là 768. Để trình bày trực quan cách các tài liệu nhúng được nhóm lại với nhau, bạn cần giảm kích thước vì bạn chỉ có thể trình bày trực quan các nội dung nhúng trong không gian 2D hoặc 3D. Các tài liệu tương tự về mặt ngữ cảnh phải gần nhau hơn trong không gian, chứ không phải các tài liệu không tương tự nhau.
len(df_train['Embeddings'][0])
768
# Convert df_train['Embeddings'] Pandas series to a np.array of float32
X = np.array(df_train['Embeddings'].to_list(), dtype=np.float32)
X.shape
(600, 768)
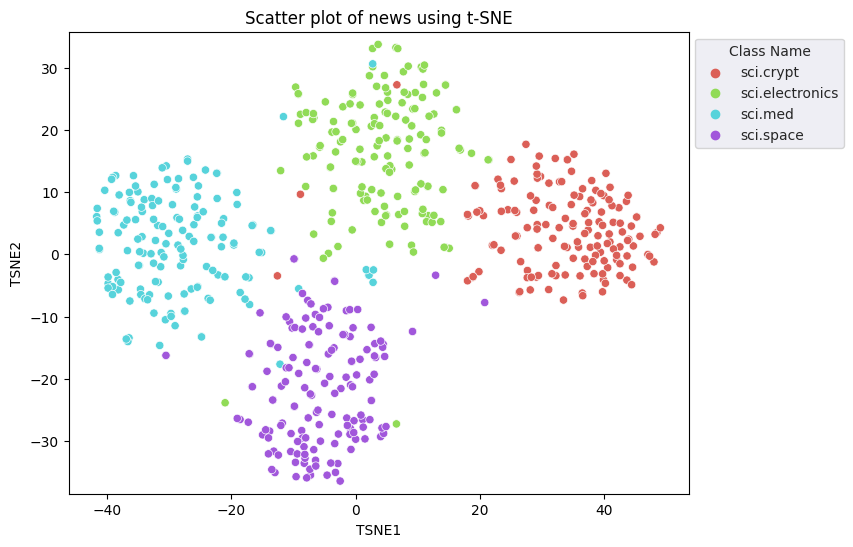
Bạn sẽ áp dụng phương pháp Nhúng vùng lân cận ngẫu nhiên phân phối t (t-SNE) để giảm kích thước. Kỹ thuật này làm giảm số lượng phương diện, trong khi vẫn duy trì các cụm (các điểm gần nhau sẽ luôn gần nhau). Đối với dữ liệu gốc, mô hình cố gắng xây dựng sự phân phối mà trên đó các điểm dữ liệu khác là "lân cận" (ví dụ: chúng có cùng ý nghĩa). Sau đó, tính năng này tối ưu hoá một hàm mục tiêu để giữ nguyên sự phân phối trong hình ảnh trực quan.
tsne = TSNE(random_state=0, n_iter=1000)
tsne_results = tsne.fit_transform(X)
df_tsne = pd.DataFrame(tsne_results, columns=['TSNE1', 'TSNE2'])
df_tsne['Class Name'] = df_train['Class Name'] # Add labels column from df_train to df_tsne
df_tsne
fig, ax = plt.subplots(figsize=(8,6)) # Set figsize
sns.set_style('darkgrid', {"grid.color": ".6", "grid.linestyle": ":"})
sns.scatterplot(data=df_tsne, x='TSNE1', y='TSNE2', hue='Class Name', palette='hls')
sns.move_legend(ax, "upper left", bbox_to_anchor=(1, 1))
plt.title('Scatter plot of news using t-SNE');
plt.xlabel('TSNE1');
plt.ylabel('TSNE2');
plt.axis('equal')
(-46.191162300109866, 53.521015357971194, -39.96646995544434, 37.282975387573245)
So sánh kết quả với KMeans
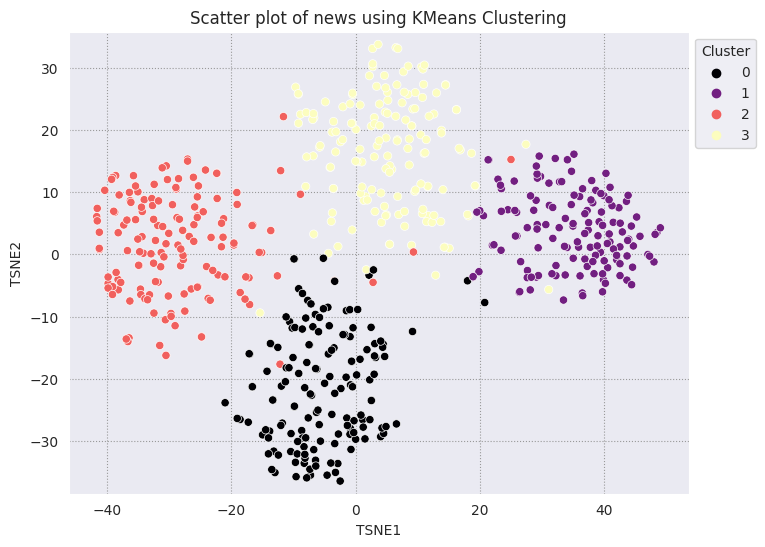
Phân cụm KMeans là một thuật toán phân cụm phổ biến và thường được dùng trong quá trình học tập không có người giám sát. Hàm này lặp lại xác định k điểm tâm tốt nhất và gán từng ví dụ cho trọng tâm gần nhất. Nhập trực tiếp các video nhúng vào thuật toán KMeans để so sánh việc trực quan hoá các video nhúng với hiệu suất của một thuật toán học máy.
# Apply KMeans
kmeans_model = KMeans(n_clusters=4, random_state=1, n_init='auto').fit(X)
labels = kmeans_model.fit_predict(X)
df_tsne['Cluster'] = labels
df_tsne
fig, ax = plt.subplots(figsize=(8,6)) # Set figsize
sns.set_style('darkgrid', {"grid.color": ".6", "grid.linestyle": ":"})
sns.scatterplot(data=df_tsne, x='TSNE1', y='TSNE2', hue='Cluster', palette='magma')
sns.move_legend(ax, "upper left", bbox_to_anchor=(1, 1))
plt.title('Scatter plot of news using KMeans Clustering');
plt.xlabel('TSNE1');
plt.ylabel('TSNE2');
plt.axis('equal')
(-46.191162300109866, 53.521015357971194, -39.96646995544434, 37.282975387573245)
def get_majority_cluster_per_group(df_tsne_cluster, class_names):
class_clusters = dict()
for c in class_names:
# Get rows of dataframe that are equal to c
rows = df_tsne_cluster.loc[df_tsne_cluster['Class Name'] == c]
# Get majority value in Cluster column of the rows selected
cluster = rows.Cluster.mode().values[0]
# Populate mapping dictionary
class_clusters[c] = cluster
return class_clusters
classes = df_tsne['Class Name'].unique()
class_clusters = get_majority_cluster_per_group(df_tsne, classes)
class_clusters
{'sci.crypt': 1, 'sci.electronics': 3, 'sci.med': 2, 'sci.space': 0}
Nhận phần lớn các cụm cho mỗi nhóm và xem có bao nhiêu thành viên thực sự của nhóm có trong cụm đó.
# Convert the Cluster column to use the class name
class_by_id = {v: k for k, v in class_clusters.items()}
df_tsne['Predicted'] = df_tsne['Cluster'].map(class_by_id.__getitem__)
# Filter to the correctly matched rows
correct = df_tsne[df_tsne['Class Name'] == df_tsne['Predicted']]
# Summarise, as a percentage
acc = correct['Class Name'].value_counts() / SAMPLE_SIZE
acc
sci.space 0.966667 sci.med 0.960000 sci.electronics 0.953333 sci.crypt 0.926667 Name: Class Name, dtype: float64
# Get predicted values by name
df_tsne['Predicted'] = ''
for idx, rows in df_tsne.iterrows():
cluster = rows['Cluster']
# Get key from mapping based on cluster value
key = list(class_clusters.keys())[list(class_clusters.values()).index(cluster)]
df_tsne.at[idx, 'Predicted'] = key
df_tsne
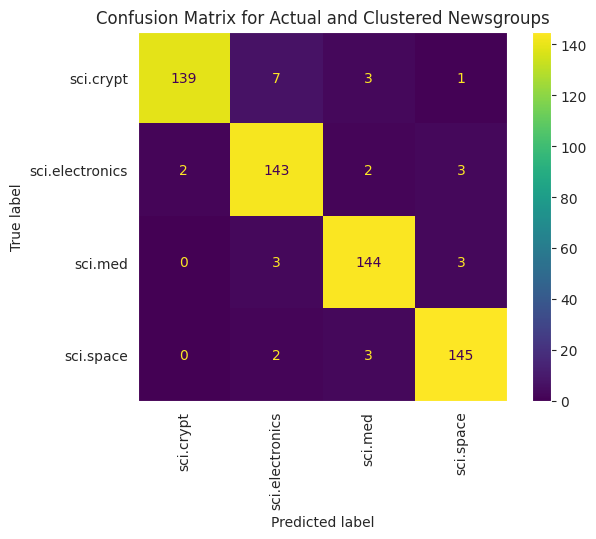
Để trực quan hoá rõ hơn hiệu suất của KMeans được áp dụng cho dữ liệu của mình, bạn có thể sử dụng ma trận nhầm lẫn. Ma trận nhầm lẫn cho phép bạn đánh giá hiệu suất của mô hình phân loại ngoài độ chính xác. Bạn có thể xem điểm bị phân loại sai là như thế nào. Bạn sẽ cần các giá trị thực tế và giá trị dự đoán mà bạn đã thu thập trong khung dữ liệu ở trên.
cm = confusion_matrix(df_tsne['Class Name'].to_list(), df_tsne['Predicted'].to_list())
disp = ConfusionMatrixDisplay(confusion_matrix=cm,
display_labels=classes)
disp.plot(xticks_rotation='vertical')
plt.title('Confusion Matrix for Actual and Clustered Newsgroups');
plt.grid(False)
Các bước tiếp theo
Bây giờ, bạn đã tạo được hình ảnh trực quan hoá của riêng mình về việc nhúng bằng tính năng phân cụm! Hãy thử sử dụng dữ liệu văn bản của riêng bạn để trực quan hoá chúng dưới dạng nội dung nhúng. Bạn có thể giảm kích thước để hoàn tất bước hình ảnh trực quan. Xin lưu ý rằng TSNE rất hiệu quả trong việc phân cụm dữ liệu đầu vào, nhưng có thể mất nhiều thời gian hơn để hội tụ hoặc có thể bị kẹt ở mức tối thiểu cục bộ. Nếu gặp vấn đề này, bạn có thể cân nhắc sử dụng một kỹ thuật khác, đó là phân tích các thành phần chính (PCA).
Ngoài ra còn có các thuật toán phân cụm khác ngoài KMeans, chẳng hạn như phân cụm không gian dựa trên mật độ (DBSCAN).
Để tìm hiểu cách sử dụng các dịch vụ khác trong API Gemini, hãy truy cập vào phần hướng dẫn bắt đầu nhanh về Python. Để tìm hiểu thêm về cách sử dụng tính năng nhúng, hãy xem các ví dụ có sẵn. Để tìm hiểu cách tạo quảng cáo Mua sắm từ đầu, hãy xem hướng dẫn Nhúng từ của TensorFlow.