
Las estrategias de diseño de instrucciones, como las instrucciones con ejemplos limitados, no siempre generan los resultados que necesitas. El ajuste es un proceso que puede mejorar el rendimiento de tu modelo en tareas específicas o ayudar al modelo a cumplir con los requisitos de salida específicos cuando las instrucciones no son suficientes y tienes un conjunto de ejemplos que demuestran los resultados que deseas.
En esta página, se proporciona orientación para ajustar el modelo de texto detrás del servicio de texto de la API de Gemini.
Cómo funciona el ajuste
El objetivo del ajuste es mejorar aún más el rendimiento del modelo para una tarea específica. El ajuste consiste en proporcionarle al modelo un conjunto de datos de entrenamiento que contiene muchos ejemplos de la tarea. Para tareas de nicho, puedes obtener mejoras significativas en el rendimiento del modelo si ajustas el modelo con una cantidad moderada de ejemplos.
Tus datos de entrenamiento deben estructurarse como ejemplos con entradas de instrucciones y resultados de respuesta esperada. También puedes ajustar modelos con datos de ejemplo directamente en Google AI Studio. El objetivo es enseñarle al modelo a imitar el comportamiento o la tarea que se desean proporcionándole muchos ejemplos que ilustran ese comportamiento o tarea.
Cuando ejecutas un trabajo de ajuste, el modelo aprende parámetros adicionales que lo ayudan a codificar la información necesaria para realizar la tarea deseada o aprender el comportamiento deseado. Estos parámetros se pueden usar en el momento de la inferencia. El resultado del trabajo de ajuste es un modelo nuevo, que es, en la práctica, una combinación de los parámetros recién aprendidos y el modelo original.
Prepara tu conjunto de datos
Antes de que puedas comenzar con el ajuste, necesitas un conjunto de datos para ajustar el modelo. Para obtener el mejor rendimiento, los ejemplos del conjunto de datos deben ser de alta calidad, ser variados y representar las entradas y los resultados reales.
Formato
Los ejemplos que se incluyen en tu conjunto de datos deben coincidir con tu tráfico de producción esperado. Si tu conjunto de datos contiene formato, palabras clave, instrucciones o información específicas, los datos de producción deben tener el mismo formato y contener las mismas instrucciones.
Por ejemplo, si los ejemplos de tu conjunto de datos incluyen una "question:" y un "context:", el tráfico de producción también debe tener el formato de modo que incluya una "question:" y un "context:" en el mismo orden en que aparecen en ejemplos de conjuntos de datos. Si excluyes el contexto, el modelo no puede reconocer el patrón, incluso si la pregunta exacta estaba en un ejemplo del conjunto de datos.
Agregar una instrucción o un preámbulo a cada ejemplo en tu conjunto de datos también puede ayudar a mejorar el rendimiento del modelo ajustado. Ten en cuenta que, si se incluye una instrucción o un preámbulo en el conjunto de datos, también debe incluirse en la instrucción del modelo ajustado en el momento de la inferencia.
Tamaño de los datos de entrenamiento
Puedes ajustar un modelo con tan solo 20 ejemplos. Por lo general, los datos adicionales mejoran la calidad de las respuestas. Debes seleccionar entre 100 y 500 ejemplos, según tu aplicación. En la siguiente tabla, se muestran los tamaños de conjuntos de datos recomendados a fin de ajustar un modelo de texto para varias tareas comunes:
| Tarea | Cantidad de ejemplos en el conjunto de datos |
|---|---|
| Clasificación | Más de 100 |
| Resúmenes | 100-500 |
| Búsqueda de documentos | Más de 100 |
Sube tu conjunto de datos de ajuste
Los datos se pasan de forma intercalada con la API o a través de archivos subidos en Google AI Studio.
Haz clic en el botón Import y sigue las instrucciones del diálogo para importar datos de un archivo o elige una instrucción estructurada con ejemplos para importar como tu conjunto de datos de ajuste.
Biblioteca cliente
Para usar la biblioteca cliente, proporciona el archivo de datos en la llamada createTunedModel. El tamaño del archivo no puede superar los 4 MB. Para comenzar, consulta la guía de inicio rápido de ajuste con Python.
cURL
Para llamar a la API de REST mediante cURL, proporciona ejemplos de entrenamiento en formato JSON al argumento training_data. Consulta la guía de inicio rápido sobre el ajuste con cURL para comenzar.
Configuración avanzada de ajuste
Cuando creas un trabajo de ajuste, puedes especificar la siguiente configuración avanzada:
- Ciclos de entrenamiento: Un entrenamiento completo sobre todo el conjunto de entrenamiento de modo que cada ejemplo se procese una vez.
- Tamaño del lote: Es el conjunto de ejemplos que se usa en una iteración de entrenamiento. El tamaño del lote determina la cantidad de ejemplos en un lote.
- Tasa de aprendizaje: Es un número de punto flotante que le indica al algoritmo la precisión con la que debe ajustar los parámetros del modelo en cada iteración. Por ejemplo, una tasa de aprendizaje de 0.3 ajustaría los pesos y los sesgos tres veces más que una tasa de aprendizaje de 0.1. Las tasas de aprendizaje altas y bajas tienen sus propias compensaciones únicas y deben ajustarse según tu caso de uso.
- Multiplicador de la tasa de aprendizaje: El multiplicador de tasa modifica la tasa de aprendizaje original del modelo. Un valor de 1 usa la tasa de aprendizaje original del modelo. Los valores mayores que 1 aumentan la tasa de aprendizaje, y los valores entre 1 y 0 disminuyen la tasa de aprendizaje.
Parámetros de configuración recomendados
En la siguiente tabla, se muestran las opciones de configuración recomendadas para ajustar un modelo de base:
| Hiperparámetro | Valor predeterminado | Ajustes recomendados |
|---|---|---|
| Ciclo de entrenamiento | 5 |
Si la pérdida comienza a estancarse antes de 5 ciclos de entrenamiento, usa un valor menor. Si la pérdida converge y no parece estancarse, usa un valor más alto.
|
| Tamaño del lote | 4 | |
| Tasa de aprendizaje | 0.001 | Usa un valor menor para conjuntos de datos más pequeños. |
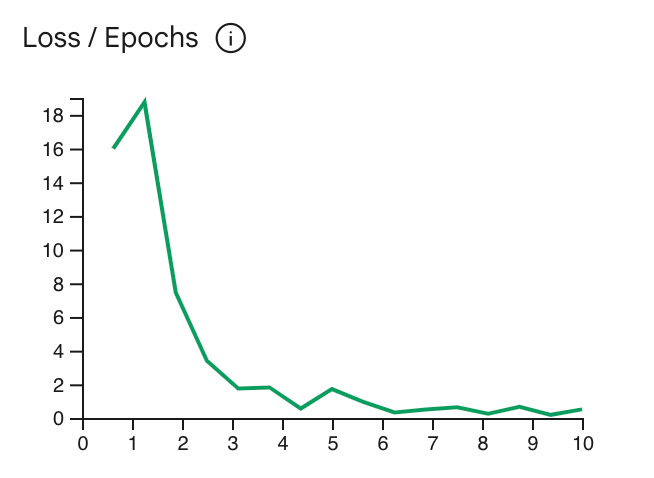
La curva de pérdida muestra cuánto se desvía la predicción del modelo de las predicciones ideales en los ejemplos de entrenamiento después de cada ciclo de entrenamiento. Lo ideal sería detener el entrenamiento en el punto más bajo de la curva, justo antes de que se estanca. Por ejemplo, en el siguiente gráfico, se muestra la estabilización de la curva de pérdida cerca de la época 4-6, lo que significa que puedes establecer el parámetro Epoch en 4 y, aun así, obtener el mismo rendimiento.
Verifica el estado del trabajo de ajuste
Puedes verificar el estado de tu trabajo de ajuste en Google AI Studio en la pestaña Mi biblioteca o con la propiedad metadata del modelo ajustado en la API de Gemini.
Solucionar errores
En esta sección, se incluyen sugerencias para resolver errores que pueden surgir durante la creación de tu modelo ajustado.
Autenticación
El ajuste con la API y la biblioteca cliente requiere la autenticación del usuario. Una clave de API por sí sola no es suficiente. Si ves un error 'PermissionDenied: 403 Request had
insufficient authentication scopes', debes configurar la autenticación
de usuarios.
Para configurar las credenciales de OAuth para Python, consulta el instructivo de configuración de OAuth.
Modelos cancelados
Puedes cancelar un trabajo de ajuste en cualquier momento antes de que finalice. Sin embargo, el rendimiento de la inferencia de un modelo cancelado es impredecible, en especial si el trabajo de ajuste se cancela al comienzo del entrenamiento. Si cancelaste el entrenamiento porque quieres detenerlo en un ciclo de entrenamiento anterior, debes crear un nuevo trabajo de ajuste y establecer el ciclo de entrenamiento en un valor más bajo.
¿Qué sigue?
- Obtén más información sobre las prácticas recomendadas de la IA responsable.
- Comienza con la guía de inicio rápido de ajuste con Python o la guía de inicio rápido con cURL.