The Gemini API provides a code execution tool that enables the model to generate and run Python code. The model can then learn iteratively from the code execution results until it arrives at a final output. You can use code execution to build applications that benefit from code-based reasoning. For example, you can use code execution to solve equations or process text. You can also use the libraries included in the code execution environment to perform more specialized tasks.
Gemini is only able to execute code in Python. You can still ask Gemini to generate code in another language, but the model can't use the code execution tool to run it.
Enable code execution
To enable code execution, configure the code execution tool on the model. This allows the model to generate and run code.
Python
from google import genai
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.5-flash",
input="What is the sum of the first 50 prime numbers? "
"Generate and run code for the calculation, and make sure you get all 50.",
tools=[{"type": "code_execution"}]
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif step.type == "code_execution_call":
print(step.arguments.code)
elif step.type == "code_execution_result":
print(step.result)
JavaScript
import { GoogleGenAI } from "@google/genai";
const client = new GoogleGenAI({});
const interaction = await client.interactions.create({
model: "gemini-3.5-flash",
input: "What is the sum of the first 50 prime numbers? " +
"Generate and run code for the calculation, and make sure you get all 50.",
tools: [{ type: "code_execution" }]
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
}
}
} else if (step.type === "code_execution_call") {
console.log(step.arguments.code);
} else if (step.type === "code_execution_result") {
console.log(step.result);
}
}
REST
curl -X POST "https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d '{
"model": "gemini-3.5-flash",
"input": "What is the sum of the first 50 prime numbers? Generate and run code for the calculation, and make sure you get all 50.",
"tools": [{"type": "code_execution"}]
}'
The output might look something like the following, which has been formatted for readability:
Okay, I need to calculate the sum of the first 50 prime numbers. Here's how I'll
approach this:
1. **Generate Prime Numbers:** I'll use an iterative method to find prime
numbers. I'll start with 2 and check if each subsequent number is divisible
by any number between 2 and its square root. If not, it's a prime.
2. **Store Primes:** I'll store the prime numbers in a list until I have 50 of
them.
3. **Calculate the Sum:** Finally, I'll sum the prime numbers in the list.
Here's the Python code to do this:
def is_prime(n):
"""Efficiently checks if a number is prime."""
if n <= 1:
return False
if n <= 3:
return True
if n % 2 == 0 or n % 3 == 0:
return False
i = 5
while i * i <= n:
if n % i == 0 or n % (i + 2) == 0:
return False
i += 6
return True
primes = []
num = 2
while len(primes) < 50:
if is_prime(num):
primes.append(num)
num += 1
sum_of_primes = sum(primes)
print(f'{primes=}')
print(f'{sum_of_primes=}')
primes=[2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59, 61, 67,
71, 73, 79, 83, 89, 97, 101, 103, 107, 109, 113, 127, 131, 137, 139, 149, 151,
157, 163, 167, 173, 179, 181, 191, 193, 197, 199, 211, 223, 227, 229]
sum_of_primes=5117
The sum of the first 50 prime numbers is 5117.
This output combines several content parts that the model returns when using code execution:
text: Inline text generated by the modelcode_execution_call: Code generated by the model that is meant to be executedcode_execution_result: Result of the executable code
Code Execution with images (Gemini 3)
The Gemini 3 Flash model can now write and execute Python code to actively manipulate and inspect images.
Use cases
- Zoom and inspect: The model implicitly detects when details are too small (e.g., reading a distant gauge) and writes code to crop and re-examine the area at higher resolution.
- Visual math: The model can run multi-step calculations using code (e.g., summing line items on a receipt).
- Image annotation: The model can annotate images to answer questions, such as drawing arrows to show relationships.
Enable Code Execution with images
Code Execution with images is officially supported in Gemini 3 Flash. You can activate this behavior by enabling both Code Execution as a tool and Thinking.
Python
from google import genai
import requests
import base64
from PIL import Image
import io
image_path = "https://goo.gle/instrument-img"
image_bytes = requests.get(image_path).content
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.5-flash",
input=[
{"type": "image", "data": base64.b64encode(image_bytes).decode('utf-8'), "mime_type": "image/jpeg"},
{"type": "text", "text": "Zoom into the expression pedals and tell me how many pedals are there?"}
],
tools=[{"type": "code_execution"}]
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
img = Image.open(io.BytesIO(base64.b64decode(content_block.data)))
img.show() # or: img.save("output_image.jpg")
elif step.type == "code_execution_call":
print(step.arguments.code)
elif step.type == "code_execution_result":
print(step.result)
JavaScript
import { GoogleGenAI } from "@google/genai";
async function main() {
const client = new GoogleGenAI({});
const imageUrl = "https://goo.gle/instrument-img";
const response = await fetch(imageUrl);
const imageArrayBuffer = await response.arrayBuffer();
const base64ImageData = Buffer.from(imageArrayBuffer).toString('base64');
const interaction = await client.interactions.create({
model: "gemini-3.5-flash",
input: [
{
type: "image",
data: base64ImageData,
mime_type: "image/jpeg"
},
{ type: "text", text: "Zoom into the expression pedals and tell me how many pedals are there?" }
],
tools: [{ type: "code_execution" }]
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log("Text:", contentBlock.text);
}
}
} else if (step.type === "code_execution_call") {
console.log(`\nGenerated Code:\n`, step.arguments.code);
} else if (step.type === "code_execution_result") {
console.log(`\nExecution Output:\n`, step.result);
}
}
}
main();
REST
IMG_URL="https://goo.gle/instrument-img"
MODEL="gemini-3.5-flash"
MIME_TYPE=$(curl -sIL "$IMG_URL" | grep -i '^content-type:' | awk -F ': ' '{print $2}' | sed 's/\r$//' | head -n 1)
if [[ -z "$MIME_TYPE" || ! "$MIME_TYPE" == image/* ]]; then
MIME_TYPE="image/jpeg"
fi
if [[ "$(uname)" == "Darwin" ]]; then
IMAGE_B64=$(curl -sL "$IMG_URL" | base64 -b 0)
elif [[ "$(base64 --version 2>&1)" = *"FreeBSD"* ]]; then
IMAGE_B64=$(curl -sL "$IMG_URL" | base64)
else
IMAGE_B64=$(curl -sL "$IMG_URL" | base64 -w0)
fi
# Use jq to create the JSON payload to avoid "Argument list too long" error with large base64 strings
echo -n "$IMAGE_B64" > image_b64.txt
jq -n \
--rawfile b64 image_b64.txt \
--arg mime "$MIME_TYPE" \
'{
model: "gemini-3.5-flash",
input: [
{type: "image", data: $b64, mime_type: $mime},
{type: "text", text: "Zoom into the expression pedals and tell me how many pedals are there?"}
],
tools: [{type: "code_execution"}]
}' > payload.json
curl -X POST "https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d @payload.json
Use code execution in multi-turn interactions
You can also use code execution as part of a multi-turn conversation using
previous_interaction_id.
Python
from google import genai
client = genai.Client()
interaction1 = client.interactions.create(
model="gemini-3.5-flash",
input="I have a math question for you.",
tools=[{"type": "code_execution"}]
)
print(interaction1.output_text)
interaction2 = client.interactions.create(
model="gemini-3.5-flash",
previous_interaction_id=interaction1.id,
input="What is the sum of the first 50 prime numbers? "
"Generate and run code for the calculation, and make sure you get all 50.",
tools=[{"type": "code_execution"}]
)
for step in interaction2.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif step.type == "code_execution_call":
print(step.arguments.code)
elif step.type == "code_execution_result":
print(step.result)
JavaScript
import { GoogleGenAI } from "@google/genai";
const client = new GoogleGenAI({});
const interaction1 = await client.interactions.create({
model: "gemini-3.5-flash",
input: "I have a math question for you.",
tools: [{ type: "code_execution" }]
});
console.log(interaction1.output_text);
const interaction2 = await client.interactions.create({
model: "gemini-3.5-flash",
previous_interaction_id: interaction1.id,
input: "What is the sum of the first 50 prime numbers? " +
"Generate and run code for the calculation, and make sure you get all 50.",
tools: [{ type: "code_execution" }]
});
for (const step of interaction2.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
}
}
} else if (step.type === "code_execution_call") {
console.log(step.arguments.code);
} else if (step.type === "code_execution_result") {
console.log(step.result);
}
}
REST
# First turn
RESPONSE1=$(curl -s -X POST "https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d '{
"model": "gemini-3.5-flash",
"input": "I have a math question for you.",
"tools": [{"type": "code_execution"}]
}')
INTERACTION_ID=$(echo $RESPONSE1 | jq -r '.id')
# Second turn with previous_interaction_id
curl -X POST "https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d '{
"model": "gemini-3.5-flash",
"previous_interaction_id": "'"$INTERACTION_ID"'",
"input": "What is the sum of the first 50 prime numbers? Generate and run code for the calculation, and make sure you get all 50.",
"tools": [{"type": "code_execution"}]
}'
Input/output (I/O)
In current Gemini models such as Gemini 3.5 Flash, code execution supports file input and graph output. Using these input and output capabilities, you can upload CSV and text files, ask questions about the files, and have Matplotlib graphs generated as part of the response. The output files are returned as inline images in the response.
I/O pricing
When using code execution I/O, you're charged for input tokens and output tokens:
Input tokens:
- User prompt
Output tokens:
- Code generated by the model
- Code execution output in the code environment
- Thinking tokens
- Summary generated by the model
I/O details
When you're working with code execution I/O, be aware of the following technical details:
- The maximum runtime of the code environment is 30 seconds.
- If the code environment generates an error, the model may decide to regenerate the code output. This can happen up to 5 times.
- The maximum file input size is limited by the model token window. If you upload a file that exceeds the model's maximum context window, the API will return an error.
- Code execution works best with text and CSV files.
- The input file can be passed as inline data or uploaded using the Files API, and the output file is always returned as inline data.
Billing
There's no additional charge for enabling code execution from the Gemini API. You'll be billed at the current rate of input and output tokens based on the Gemini model you're using.
Here are a few other things to know about billing for code execution:
- You're only billed once for the input tokens you pass to the model, and you're billed for the final output tokens returned to you by the model.
- Tokens representing generated code are counted as output tokens. Generated code can include text and multimodal output like images.
- Code execution results are also counted as output tokens.
The billing model is shown in the following diagram:
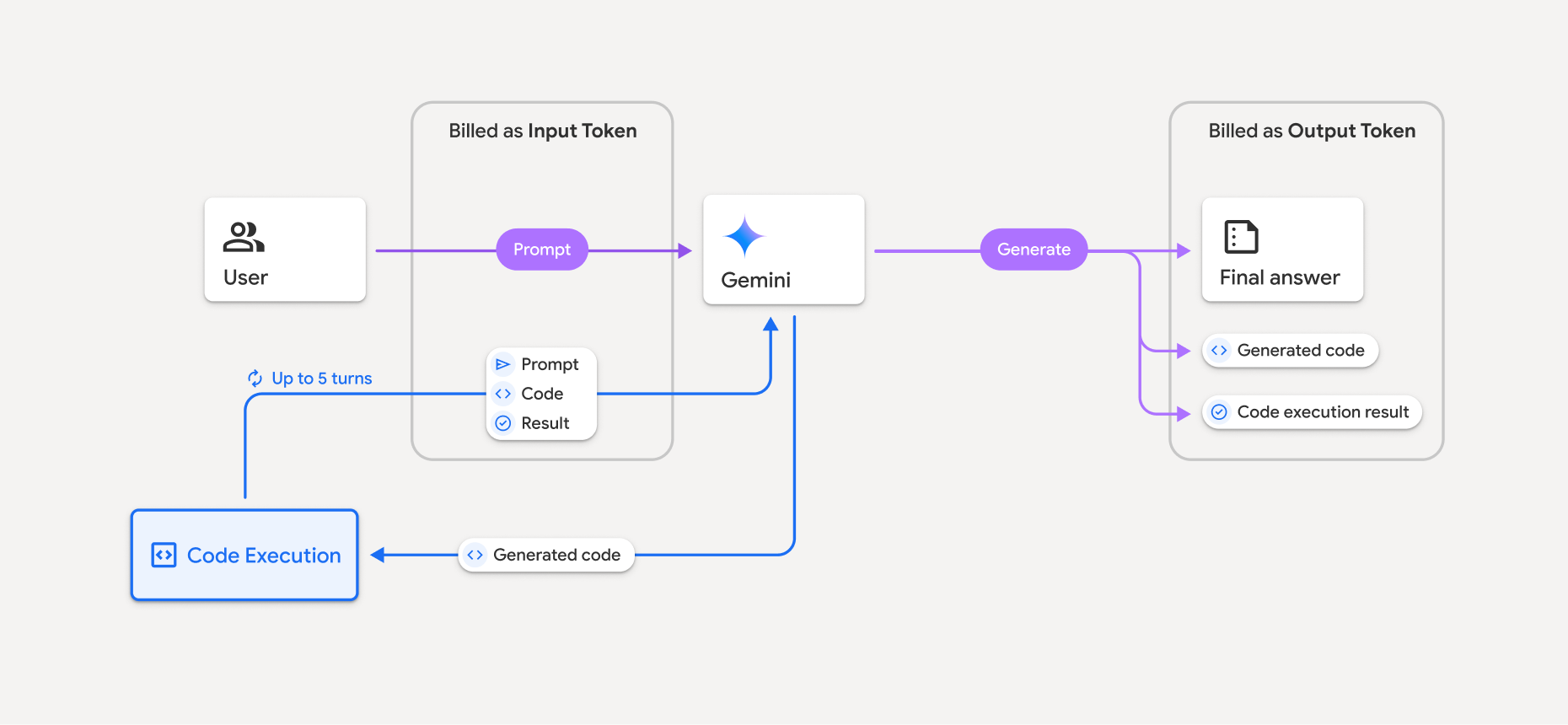
- You're billed at the current rate of input and output tokens based on the Gemini model you're using.
- If Gemini uses code execution when generating your response, the original prompt, the generated code, and the result of the executed code are labeled intermediate tokens and are billed as input tokens.
- Gemini then generates a summary and returns the generated code, the result of the executed code, and the final summary. These are billed as output tokens.
- The Gemini API includes an intermediate token count in the API response, so you know why you're getting additional input tokens beyond your initial prompt.
Limitations
- The model can only generate and execute code. It can't return other artifacts like media files.
- In some cases, enabling code execution can lead to regressions in other areas of model output (for example, writing a story).
- There is some variation in the ability of the different models to use code execution successfully.
Supported tools combinations
Code execution tool can be combined with Grounding with Google Search to power more complex use cases.
Gemini 3 models support combining built-in tools (like Code Execution) with custom tools (function calling).
Supported libraries
The code execution environment includes the following libraries:
- attrs
- chess
- contourpy
- fpdf
- geopandas
- imageio
- jinja2
- joblib
- jsonschema
- jsonschema-specifications
- lxml
- matplotlib
- mpmath
- numpy
- opencv-python
- openpyxl
- packaging
- pandas
- pillow
- protobuf
- pylatex
- pyparsing
- PyPDF2
- python-dateutil
- python-docx
- python-pptx
- reportlab
- scikit-learn
- scipy
- seaborn
- six
- striprtf
- sympy
- tabulate
- tensorflow
- toolz
- xlrd
You can't install your own libraries.
What's next
- Try the Interactions API Quickstart.
- Learn about other Gemini API tools: