
استراتژیهای طراحی سریع مانند درخواست چند شات ممکن است همیشه نتایج مورد نیاز شما را تولید نکنند. تنظیم دقیق فرآیندی است که میتواند عملکرد مدل شما را در کارهای خاص بهبود بخشد یا به مدل کمک کند تا زمانی که دستورالعملها کافی نیستند و شما مجموعهای از نمونهها را دارید که خروجیهای مورد نظرتان را نشان میدهند، به الزامات خروجی خاص پایبند باشد.
این صفحه راهنمایی در مورد تنظیم دقیق مدل متنی در پشت سرویس متنی Gemini API ارائه می دهد.
تنظیم دقیق چگونه کار می کند
هدف از تنظیم دقیق، بهبود بیشتر عملکرد مدل برای کار خاص شما است. تنظیم دقیق با ارائه یک مجموعه داده آموزشی به مدل کار می کند که شامل نمونه های زیادی از کار است. برای کارهای خاص، می توانید با تنظیم مدل بر روی تعداد کمی از نمونه ها، پیشرفت های قابل توجهی در عملکرد مدل داشته باشید.
داده های آموزشی شما باید به عنوان نمونه هایی با ورودی های سریع و خروجی های پاسخ مورد انتظار ساختار بندی شوند. همچنین میتوانید مدلها را با استفاده از دادههای نمونه مستقیماً در Google AI Studio تنظیم کنید. هدف این است که با ارائه مثالهای فراوانی که آن رفتار یا وظیفه را نشان میدهد، مدل را به تقلید از رفتار یا وظیفه مورد نظر آموزش دهیم.
هنگامی که یک کار تنظیم را اجرا می کنید، مدل پارامترهای اضافی را می آموزد که به آن کمک می کند اطلاعات لازم را برای انجام کار مورد نظر یا یادگیری رفتار مورد نظر رمزگذاری کند. سپس می توان از این پارامترها در زمان استنتاج استفاده کرد. خروجی کار تنظیم یک مدل جدید است که در واقع ترکیبی از پارامترهای تازه آموخته شده و مدل اصلی است.
مجموعه داده خود را آماده کنید
قبل از اینکه بتوانید تنظیم دقیق را شروع کنید، به یک مجموعه داده برای تنظیم مدل نیاز دارید. برای بهترین عملکرد، نمونه های موجود در مجموعه داده باید با کیفیت بالا، متنوع و معرف ورودی ها و خروجی های واقعی باشند.
قالب
نمونه های موجود در مجموعه داده شما باید با ترافیک تولید مورد انتظار شما مطابقت داشته باشد. اگر مجموعه داده شما حاوی قالببندی، کلمات کلیدی، دستورالعملها یا اطلاعات خاصی است، دادههای تولید باید به همان شیوه قالببندی شده و حاوی دستورالعملهای مشابه باشند.
به عنوان مثال، اگر نمونههای موجود در مجموعه داده شما شامل یک "question:" و یک "context:" ، ترافیک تولید نیز باید طوری قالببندی شود که شامل یک "question:" و یک "context:" به همان ترتیبی باشد که در زیر نشان داده میشود. نمونه های مجموعه داده اگر زمینه را حذف کنید، مدل نمیتواند الگو را تشخیص دهد، حتی اگر سؤال دقیق در یک مثال در مجموعه داده باشد.
افزودن یک اعلان یا مقدمه به هر نمونه در مجموعه داده شما نیز می تواند به بهبود عملکرد مدل تنظیم شده کمک کند. توجه داشته باشید، اگر یک اعلان یا مقدمه در مجموعه داده شما گنجانده شده است، باید در زمان استنتاج در اعلان مدل تنظیم شده نیز گنجانده شود.
اندازه داده های آموزشی
شما می توانید یک مدل را با حداقل 20 نمونه تنظیم کنید. داده های اضافی به طور کلی کیفیت پاسخ ها را بهبود می بخشد. بسته به کاربردتان باید بین 100 تا 500 نمونه را هدف بگیرید. جدول زیر اندازه های داده توصیه شده را برای تنظیم دقیق یک مدل متنی برای کارهای رایج مختلف نشان می دهد:
| وظیفه | تعداد نمونه در مجموعه داده |
|---|---|
| طبقه بندی | 100+ |
| خلاصه سازی | 100-500+ |
| جستجوی سند | 100+ |
مجموعه داده تنظیم خود را آپلود کنید
داده ها یا با استفاده از API یا از طریق فایل های آپلود شده در Google AI Studio منتقل می شوند.
روی دکمه واردات کلیک کنید و دستورالعملهای گفتگو را دنبال کنید تا دادهها را از یک فایل وارد کنید یا یک دستور ساختاریافته با مثالهایی را برای وارد کردن به عنوان مجموعه داده تنظیم انتخاب کنید.
کتابخانه مشتری
برای استفاده از کتابخانه مشتری، فایل داده را در فراخوانی createTunedModel ارائه دهید. محدودیت حجم فایل 4 مگابایت است. برای شروع ، شروع سریع تنظیم دقیق با پایتون را ببینید.
حلقه
برای فراخوانی REST API با استفاده از cURL، نمونههای آموزشی را با فرمت JSON به آرگومان training_data ارائه دهید. برای شروع ، شروع سریع تنظیم با cURL را ببینید.
تنظیمات تنظیم پیشرفته
هنگام ایجاد یک کار تنظیم، می توانید تنظیمات پیشرفته زیر را مشخص کنید:
- Epochs: یک پاس آموزشی کامل در کل مجموعه آموزشی به طوری که هر نمونه یک بار پردازش شده است.
- اندازه دسته ای: مجموعه ای از نمونه های مورد استفاده در یک تکرار آموزشی. اندازه دسته تعداد نمونه ها را در یک دسته تعیین می کند.
- نرخ یادگیری: یک عدد ممیز شناور که به الگوریتم میگوید با چه شدتی پارامترهای مدل را در هر تکرار تنظیم کند. به عنوان مثال، نرخ یادگیری 0.3 می تواند وزن ها و سوگیری ها را سه برابر قوی تر از نرخ یادگیری 0.1 تنظیم کند. نرخ یادگیری بالا و پایین دارای مبادلات منحصر به فرد خود هستند و باید بر اساس موارد استفاده شما تنظیم شوند.
- ضرب کننده نرخ یادگیری: ضرب کننده نرخ، نرخ یادگیری اصلی مدل را تغییر می دهد. مقدار 1 از نرخ یادگیری اصلی مدل استفاده می کند. مقادیر بیشتر از 1 میزان یادگیری را افزایش می دهد و مقادیر بین 1 تا 0 میزان یادگیری را کاهش می دهد.
تنظیمات توصیه شده
جدول زیر پیکربندی های توصیه شده برای تنظیم دقیق مدل فونداسیون را نشان می دهد:
| فرا پارامتر | مقدار پیش فرض | تنظیمات توصیه شده |
|---|---|---|
| دوران | 5 | اگر زیان قبل از 5 دوره شروع به افزایش کرد، از مقدار کمتری استفاده کنید. اگر از دست دادن همگرا است و به نظر نمی رسد فلات باشد، از یک مقدار بالاتر استفاده کنید. |
| اندازه دسته | 4 | |
| میزان یادگیری | 0.001 | برای مجموعه داده های کوچکتر از مقدار کمتری استفاده کنید. |
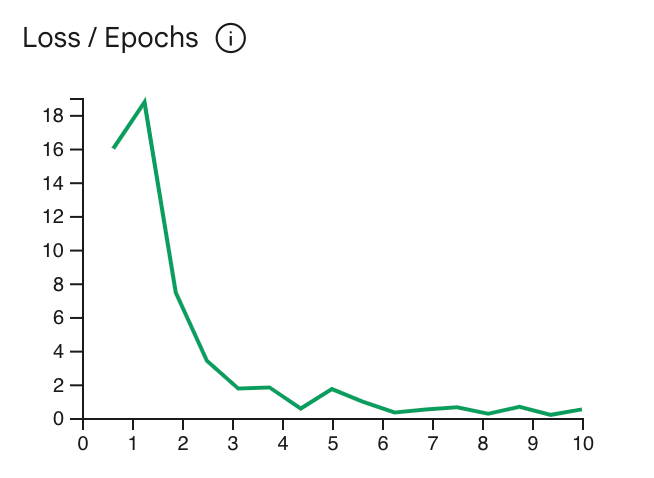
منحنی ضرر نشان می دهد که پیش بینی مدل پس از هر دوره چقدر از پیش بینی های ایده آل در مثال های آموزشی انحراف دارد. در حالت ایدهآل، میخواهید تمرین را در پایینترین نقطه منحنی، درست قبل از اینکه فلات کند، متوقف کنید. به عنوان مثال، نمودار زیر منحنی تلفات را در حدود دوره 4-6 نشان می دهد که به این معنی است که می توانید پارامتر Epoch را روی 4 تنظیم کنید و همچنان همان عملکرد را داشته باشید.
وضعیت کار تنظیم را بررسی کنید
می توانید وضعیت کار تنظیم خود را در استودیوی هوش مصنوعی Google در برگه My Library یا با استفاده از ویژگی metadata مدل تنظیم شده در Gemini API بررسی کنید.
عیب یابی خطاها
این بخش شامل نکاتی در مورد نحوه رفع خطاهایی است که ممکن است هنگام ایجاد مدل تنظیم شده خود با آن مواجه شوید.
احراز هویت
تنظیم با استفاده از API و کتابخانه مشتری نیاز به احراز هویت کاربر دارد. یک کلید API به تنهایی کافی نیست. اگر خطای 'PermissionDenied: 403 Request had insufficient authentication scopes' مشاهده کردید، باید احراز هویت کاربر را تنظیم کنید.
برای پیکربندی اعتبار OAuth برای Python به آموزش راه اندازی OAuth مراجعه کنید.
مدل های لغو شده
شما می توانید قبل از اتمام کار، هر زمان که بخواهید یک کار تنظیم دقیق را لغو کنید. با این حال، عملکرد استنتاج یک مدل لغو شده غیرقابل پیش بینی است، به خصوص اگر کار تنظیم در اوایل آموزش لغو شود. اگر به دلیل اینکه میخواهید آموزش را در دوره قبلی متوقف کنید لغو کردید، باید یک کار تنظیم جدید ایجاد کنید و دوره را روی مقدار کمتری تنظیم کنید.
بعدش چی
- درباره بهترین شیوه های هوش مصنوعی مسئول بیاموزید.
- با شروع سریع تنظیم با پایتون یا تنظیم سریع با cURL شروع کنید.