
Strategie projektowania promptów, takie jak prompty „few-shot”, nie zawsze przynoszą oczekiwane rezultaty. Dostrajanie to proces, który może zwiększyć wydajność modelu w określonych zadaniach lub pomóc mu spełnić określone wymagania dotyczące danych wyjściowych, gdy instrukcje są niewystarczające i masz zbiór przykładów ilustrujących pożądane wyniki.
Ta strona zawiera wskazówki dotyczące dostrajania modelu tekstowego wykorzystywanego w usłudze tekstowej Gemini API.
Jak działa dostrajanie
Celem dostrajania jest zwiększenie wydajności modelu w odniesieniu do Twojego konkretnego zadania. Dostrajanie polega na udostępnieniu modelu zbioru danych treningowych zawierającego wiele przykładów zadania. W przypadku niszowych zadań można znacznie poprawić wydajność modelu, dostrajając go na niewielkiej liczbie przykładów.
Dane treningowe powinny być uporządkowane w formie przykładów z danymi wejściowymi promptów i oczekiwanymi wynikami odpowiedzi. Możesz też dostrajać modele na podstawie przykładowych danych bezpośrednio w Google AI Studio. Celem jest nauczenie modelu naśladowania pożądanego zachowania lub zadania przez podanie wielu przykładów ilustrujących to działanie.
Gdy uruchamiasz zadanie dostrajania, model uczy się dodatkowych parametrów, które pomagają zakodować informacje niezbędne do wykonania danego zadania lub uczenia się oczekiwanego zachowania. Tych parametrów można później używać podczas wnioskowania. Wynikiem zadania dostrajania jest nowy model, który jest kombinacją nowo wyuczonych parametrów i modelu oryginalnego.
Przygotowywanie zbioru danych
Zanim zaczniesz dostrajać, potrzebujesz zbioru danych, za pomocą którego dostrój model. Aby uzyskać najlepszą wydajność, przykłady w zbiorze danych powinny być wysokiej jakości, zróżnicowane oraz reprezentatywne dla rzeczywistych danych wejściowych i wyjściowych.
Format
Przykłady zawarte w zbiorze danych powinny być zgodne z oczekiwanym ruchem produkcyjnym. Jeśli zbiór danych zawiera konkretne formatowanie, słowa kluczowe, instrukcje lub informacje, dane produkcyjne powinny być sformatowane w ten sam sposób i zawierać te same instrukcje.
Jeśli np. przykłady w zbiorze danych obejmują atrybuty "question:" i "context:", ruch produkcyjny powinien też być sformatowany tak, aby obejmował zdarzenia "question:" i "context:" w tej samej kolejności, w jakiej występują w przykładowych zebiorach danych. Jeśli wykluczysz kontekst, model nie rozpozna wzorca, nawet jeśli dokładne pytanie znajduje się w przykładzie w zbiorze danych.
Dodanie promptu lub wprowadzenia do każdego przykładu w zbiorze danych może też poprawić wydajność dostrojonego modelu. Uwaga: jeśli zbiór danych zawiera prompt lub wprowadzenie, należy je również uwzględnić w prompcie skierowanym do dostrojonego modelu w czasie wnioskowania.
Rozmiar danych treningowych
Możesz dostroić model, używając nawet 20 przykładów. Dodatkowe dane zwykle poprawiają jakość odpowiedzi. W zależności od aplikacji musisz kierować reklamy na od 100 do 500 przykładów. W tabeli poniżej znajdziesz zalecane rozmiary zbiorów danych, które pozwalają dostrajać model tekstowy na potrzeby różnych typowych zadań:
| Działanie | Liczba przykładów w zbiorze danych |
|---|---|
| Klasyfikacja | 100+ |
| Podsumowywanie | 100-500+ |
| Wyszukiwanie dokumentów | 100+ |
Prześlij zbiór danych dostrajania
Dane są przekazywane w tekście za pomocą interfejsu API lub przez pliki przesłane do Google AI Studio.
Kliknij przycisk Importuj i postępuj zgodnie z instrukcjami wyświetlanymi w oknie, aby zaimportować dane z pliku lub wybrać uporządkowany prompt z przykładami do zaimportowania jako zbiór danych dostrajania.
Biblioteka klienta
Aby korzystać z biblioteki klienta, udostępnij plik danych w wywołaniu createTunedModel. Maksymalny rozmiar pliku to 4 MB. Aby rozpocząć, zapoznaj się z krótkim wprowadzeniem do dostrajania w Pythonie.
cURL
Aby wywołać interfejs API REST za pomocą cURL, podaj przykłady treningowe w formacie JSON do argumentu training_data. Na początek zapoznaj się z krótkim wprowadzeniem do dostrajania za pomocą cURL.
Zaawansowane ustawienia dostrajania
Podczas tworzenia zadania dostrajania możesz określić te ustawienia zaawansowane:
- Epoki: pełny bilet treningowy obejmujący cały zbiór treningowy, w którym każdy przykład został przetworzony raz.
- Wielkość wsadu: zbiór przykładów używanych w 1 powtarzaniu trenowania. Rozmiar wsadu określa liczbę przykładów we wsadzie.
- Tempo uczenia się: liczba zmiennoprzecinkowa, która informuje algorytm, jak mocno ma dostosowywać parametry modelu przy każdej iteracji. Na przykład tempo uczenia się na poziomie 0,3 dostosowałoby wagi i odchylenia 3 razy silniej niż tempo uczenia się na poziomie 0,1. Wysokie i niskie wskaźniki uczenia się wiążą się z własnymi kompromisami i należy je dostosować do konkretnego przypadku użycia.
- Mnożnik tempa uczenia się: mnożnik tempa zmienia pierwotne tempo uczenia się modelu. Wartość 1 wykorzystuje pierwotne tempo uczenia się modelu. Wartości większe niż 1 zwiększają tempo uczenia się, a wartości od 1 do 0 obniżają.
Zalecane konfiguracje
W tabeli poniżej znajdziesz zalecane konfiguracje do dostrajania modelu fundacji:
| Hiperparametr | Wartość domyślna | Zalecane dostosowania |
|---|---|---|
| Epoka | 5 |
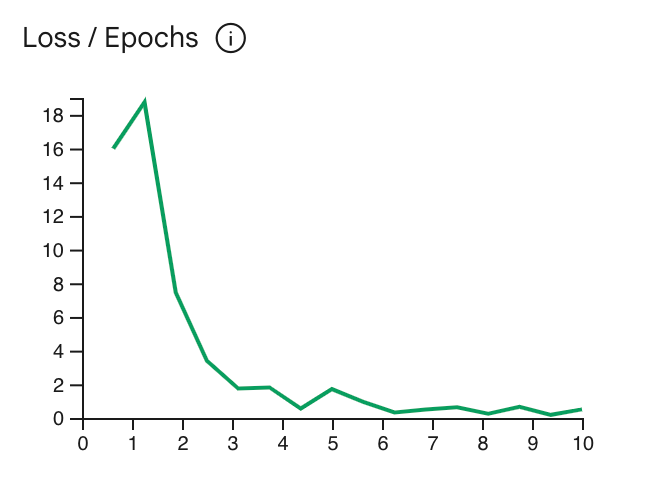
Jeśli straty zacznie spadać przed 5 epokami, użyj mniejszej wartości. Jeśli strata się zbiega i nie wydaje się być płaskowyżem, użyj większej wartości.
|
| Wielkość wsadu | 4 | |
| Tempo uczenia się | 0,001 | W przypadku mniejszych zbiorów danych używaj mniejszej wartości. |
Krzywa strat pokazuje, w jakim stopniu prognoza modelu odbiega od idealnych prognoz w przykładach treningowych po każdej epoce. Najlepiej zatrzymać trenowanie w najniższym punkcie krzywej tuż przed płaskowyżem. Na przykład wykres poniżej pokazuje płaskowyż krzywej straty w okresie 4–6 epoki. Oznacza to, że możesz ustawić parametr Epoch na 4 i zachować taką samą skuteczność.
Sprawdzanie stanu zadania dostrajania
Stan zadania dostrajania możesz sprawdzić w Google AI Studio na karcie Moja biblioteka lub za pomocą właściwości metadata dostrojonego modelu w Gemini API.
Rozwiązywanie problemów
Ta sekcja zawiera wskazówki dotyczące rozwiązywania błędów, które mogą wystąpić podczas tworzenia dostrojonego modelu.
Uwierzytelnianie
Dostrajanie przy użyciu interfejsu API i biblioteki klienta wymaga uwierzytelnienia użytkownika. Samo klucz interfejsu API nie wystarczy. Jeśli zobaczysz błąd 'PermissionDenied: 403 Request had
insufficient authentication scopes', musisz skonfigurować uwierzytelnianie użytkowników.
Aby dowiedzieć się, jak skonfigurować dane logowania OAuth na potrzeby Pythona, zapoznaj się z samouczkiem dotyczącym konfiguracji OAuth.
Anulowane modele
Zadanie dostrajania możesz anulować w dowolnym momencie przed jego zakończeniem. Wydajność wnioskowania anulowanego modelu jest jednak nieprzewidywalna, zwłaszcza jeśli zadanie dostrajania zostanie anulowane na wczesnym etapie trenowania. Jeśli chcesz przerwać trenowanie we wcześniejszej epoce, utwórz nowe zadanie dostrajania i ustaw niższą wartość epoki.
Co dalej
- Dowiedz się więcej o sprawdzonych metodach w zakresie odpowiedzialnej AI.
- Zapoznaj się z krótkim wprowadzeniem do dostrajania Pythona lub krótkim wprowadzeniem do dostrajania cURL.