
Gemma 개방형 모델
Gemini 모델을 만드는 데 사용된 것과 동일한 연구 및 기술로 빌드된 최첨단 경량 개방형 모델군
책임감 있는 설계
포괄적인 안전 조치가 적용된 이 모델들은 선별된 데이터 세트 및 엄격한 조정을 통해 책임감 있고 신뢰할 수 있는 AI 솔루션을 보장하도록 도와줍니다.
크기 대비 독보적인 성능
Gemma 모델은 2B, 7B, 9B, 27B 크기에서 탁월한 벤치마크 결과를 달성하며, 더 큰 일부 오픈 모델보다도 뛰어난 성능을 보입니다.
유연한 배포
Keras, JAX, MediaPipe, PyTorch, Hugging Face 등을 사용하여 모바일, 웹, 클라우드에 원활하게 배포합니다.
Gemma 2 사용해 보기
뛰어난 성능과 탁월한 효율성을 위해 설계된 Gemma 2는 다양한 하드웨어에서 초고속 추론을 위해 최적화되어 있습니다.
5샷
MMLU
MMLU 벤치마크는 사전 학습 중에 대규모 언어 모델이 습득한 지식의 폭과 문제 해결 능력을 측정하는 테스트입니다.
25장
ARC-C
ARC-c 벤치마크는 ARC-e 데이터 세트의 보다 구체적인 하위 집합으로, 일반적인 (검색 기반 및 단어 공동발생) 알고리즘에 의해 잘못 답변된 질문만 포함되어 있습니다.
5샷
GSM8K
GSM8K 벤치마크는 여러 단계의 추론이 자주 필요한 초등학교 수준의 수학 문제를 해결하는 언어 모델의 능력을 테스트합니다.
3-5-샷
AGIEval
AGIEval 벤치마크는 인간의 지적 능력을 평가하기 위해 설계된 실제 시험에서 파생된 질문을 사용하여 언어 모델의 일반 지능을 테스트합니다.
3샷, CoT
BBH
BBH (BIG-Bench Hard) 벤치마크는 현재 언어 모델의 능력을 벗어난 것으로 간주되는 작업에 중점을 두고 다양한 추론 및 이해 도메인에서 한계를 테스트합니다.
3샷, F1
버리기
DROP은 단락에 대한 개별적인 추론이 필요한 독해력 벤치마크입니다.
5샷
Winogrande
Winogrande 벤치마크는 일반화된 상식적 추론이 필요한 이진 옵션으로 모호한 '빈칸 채우기' 작업을 해결하는 언어 모델의 능력을 테스트합니다.
10샷
HellaSwag
HellaSwag 벤치마크는 스토리의 가장 논리적인 결말을 선택하여 상식적인 추론을 이해하고 적용하는 언어 모델의 능력을 테스트합니다.
4샷
MATH
MATH는 추론, 여러 단계의 문제 해결, 수학 개념 이해가 필요한 복잡한 수학 단어 문제를 해결하는 언어 모델의 능력을 평가합니다.
제로샷
ARC-e
ARC-e 벤치마크는 실제 초등학교 수준의 객관식 과학 질문으로 언어 모델의 고급 질문 답변 기술을 테스트합니다.
제로샷
PIQA
PIQA 벤치마크는 일상적인 물리적 상호작용에 관한 질문에 답변하여 물리적 상식 지식을 이해하고 적용하는 언어 모델의 능력을 테스트합니다.
제로샷
SIQA
SIQA 벤치마크는 사람의 행동과 사회적 함의에 관한 질문을 통해 언어 모델의 사회적 상호작용 및 사회적 상식에 대한 이해를 평가합니다.
제로샷
Boolq
BoolQ 벤치마크는 자연스럽게 발생하는 예/아니요 질문에 답하는 언어 모델의 능력을 테스트하여 모델이 실제 자연어 추론 작업을 실행하는 능력을 테스트합니다.
5샷
TriviaQA
TriviaQA 벤치마크는 질문-답변-증거 삼중항을 사용하여 읽기 이해력을 테스트합니다.
5샷
NQ
NQ (자연어 질문) 벤치마크는 전체 Wikipedia 기사 내에서 답변을 찾고 이해하는 언어 모델의 능력을 테스트하여 실제 질의응답 시나리오를 시뮬레이션합니다.
pass@1
HumanEval
HumanEval 벤치마크는 솔루션이 프로그래밍 문제의 기능 단위 테스트를 통과하는지 평가하여 언어 모델의 코드 생성 능력을 테스트합니다.
3샷
MBPP
MBPP 벤치마크는 기본 프로그래밍 개념과 표준 라이브러리 사용에 중점을 두고 언어 모델이 기본 Python 프로그래밍 문제를 해결하는 능력을 테스트합니다.
100%
75%
50%
25%
0%
100%
75%
50%
25%
0%
Gemma 1
25억
Gemma 2
26억
Mistral
7B
LLAMA 3
8B
Gemma 1
7B
Gemma 2
90억
Gemma 2
270억
Gemma 1
25억
Gemma 2
26억
Mistral
7B
LLAMA 3
8B
Gemma 1
7B
Gemma 2
90억
Gemma 2
270억
Gemma 1
25억
Gemma 2
26억
Mistral
7B
LLAMA 3
8B
Gemma 1
7B
Gemma 2
90억
Gemma 2
270억
Gemma 1
25억
Gemma 2
26억
Mistral
7B
LLAMA 3
8B
Gemma 1
7B
Gemma 2
90억
Gemma 2
270억
Gemma 1
25억
Gemma 2
26억
Mistral
7B
LLAMA 3
8B
Gemma 1
7B
Gemma 2
90억
Gemma 2
270억
Gemma 1
25억
Gemma 2
26억
Mistral
7B
LLAMA 3
8B
Gemma 1
7B
Gemma 2
90억
Gemma 2
270억
Gemma 1
25억
Gemma 2
26억
Mistral
7B
LLAMA 3
8B
Gemma 1
7B
Gemma 2
90억
Gemma 2
270억
Gemma 1
25억
Gemma 2
26억
Mistral
7B
LLAMA 3
8B
Gemma 1
7B
Gemma 2
90억
Gemma 2
270억
Gemma 1
25억
Gemma 2
26억
Mistral
7B
Gemma 1
7B
Gemma 2
90억
Gemma 2
270억
Gemma 1
25억
Gemma 2
26억
Mistral
7B
Gemma 1
7B
Gemma 2
90억
Gemma 2
270억
Gemma 1
25억
Gemma 2
26억
Mistral
7B
Gemma 1
7B
Gemma 2
90억
Gemma 2
270억
Gemma 1
25억
Gemma 2
26억
Mistral
7B
Gemma 1
7B
Gemma 2
90억
Gemma 2
270억
Gemma 1
25억
Gemma 2
26억
Mistral
7B
Gemma 1
7B
Gemma 2
90억
Gemma 2
270억
Gemma 1
25억
Gemma 2
26억
Mistral
7B
Gemma 1
7B
Gemma 2
90억
Gemma 2
270억
Gemma 1
25억
Gemma 2
26억
Mistral
7B
Gemma 1
7B
Gemma 2
90억
Gemma 2
270억
Gemma 1
25억
Gemma 2
26억
Mistral
7B
Gemma 1
7B
Gemma 2
90억
Gemma 2
270억
Gemma 1
25억
Gemma 2
26억
Mistral
7B
Gemma 1
7B
Gemma 2
90억
Gemma 2
270억
*이는 사전 학습된 모델의 벤치마크입니다. 다른 방법의 성능에 관한 자세한 내용은 기술 보고서를 참고하세요.
연구 모델
확장된 Gemma 모델 제품군 살펴보기
PaliGemma 2 신규
DataGemma
Gemma 범위

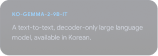

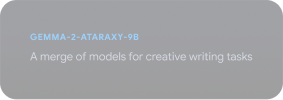
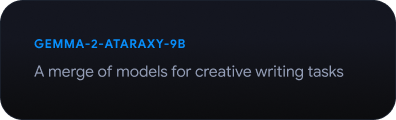

Gemmaverse 살펴보기
커뮤니티에서 만든 Gemma 모델과 도구의 광범위한 생태계로, 혁신을 지원하고 아이디어를 얻을 수 있습니다.
빌드
Gemma로 빌드 시작




모델 배포
배포 타겟 선택
![]() 모바일
모바일
Google AI Edge로 기기 내 배포
지연 시간이 짧은 오프라인 기능을 위해 기기에 직접 배포합니다. 모바일 앱, IoT 기기, 삽입 시스템과 같이 실시간 응답성과 개인 정보 보호가 필요한 애플리케이션에 적합합니다.


글로벌 커뮤니케이션의 잠금 해제
글로벌 Kaggle 대회에 참여하세요. 특정 언어 또는 고유한 문화적 측면을 위한 Gemma 모델 변형 만들기