
טיפול בפניות של לקוחות, כולל אימיילים, הוא חלק הכרחי בניהול של עסקים רבים, אבל הוא יכול להפוך במהירות למשימה מורכבת מדי. בעזרת מודלים של בינה מלאכותית (AI) כמו Gemma, אפשר להקל על העבודה הזו.
כל עסק מטפל בפניות כמו אימיילים בצורה קצת שונה, ולכן חשוב להתאים טכנולוגיות כמו AI גנרטיבי לצרכים של העסק. הפרויקט הזה מתמקד בבעיה הספציפית של חילוץ פרטי הזמנה מאימיילים שנשלחים למאפייה והפיכתם לנתונים מובְנים, כדי שאפשר יהיה להוסיף אותם במהירות למערכת לטיפול בהזמנות. בעזרת 10 עד 20 דוגמאות של פניות והפלט הרצוי, אפשר לכוונן מודל Gemma כדי לעבד אימיילים מהלקוחות, לעזור לכם להשיב במהירות ולהשתלב עם המערכות העסקיות הקיימות. הפרויקט הזה בנוי כדפוס של אפליקציית AI שאפשר להרחיב ולהתאים כדי להפיק ערך ממודלים של Gemma לעסק שלכם.
כדי לצפות בסרטון שמספק סקירה כללית של הפרויקט ומסביר איך להרחיב אותו, כולל תובנות של האנשים שבנו אותו, כדאי לצפות בסרטון Business Email AI Assistant Build with Google AI. אפשר גם לעיין בקוד של הפרויקט הזה במאגר הקוד של Gemma Cookbook. אם לא, אפשר להתחיל להרחיב את הפרויקט באמצעות ההוראות הבאות.
סקירה כללית
במדריך הזה נסביר איך להגדיר, להפעיל ולהרחיב אפליקציית עוזר אימייל לעסקים שנבנתה באמצעות Gemma, Python ו-Flask. הפרויקט מספק ממשק משתמש בסיסי באינטרנט שאפשר לשנות אותו בהתאם לצרכים שלכם. האפליקציה נועדה לחלץ נתונים מאימיילים של לקוחות למבנה של מאפייה פיקטיבית. אפשר להשתמש בדפוס האפליקציה הזה לכל משימה עסקית שמשתמשת בקלט טקסט ופלט טקסט.
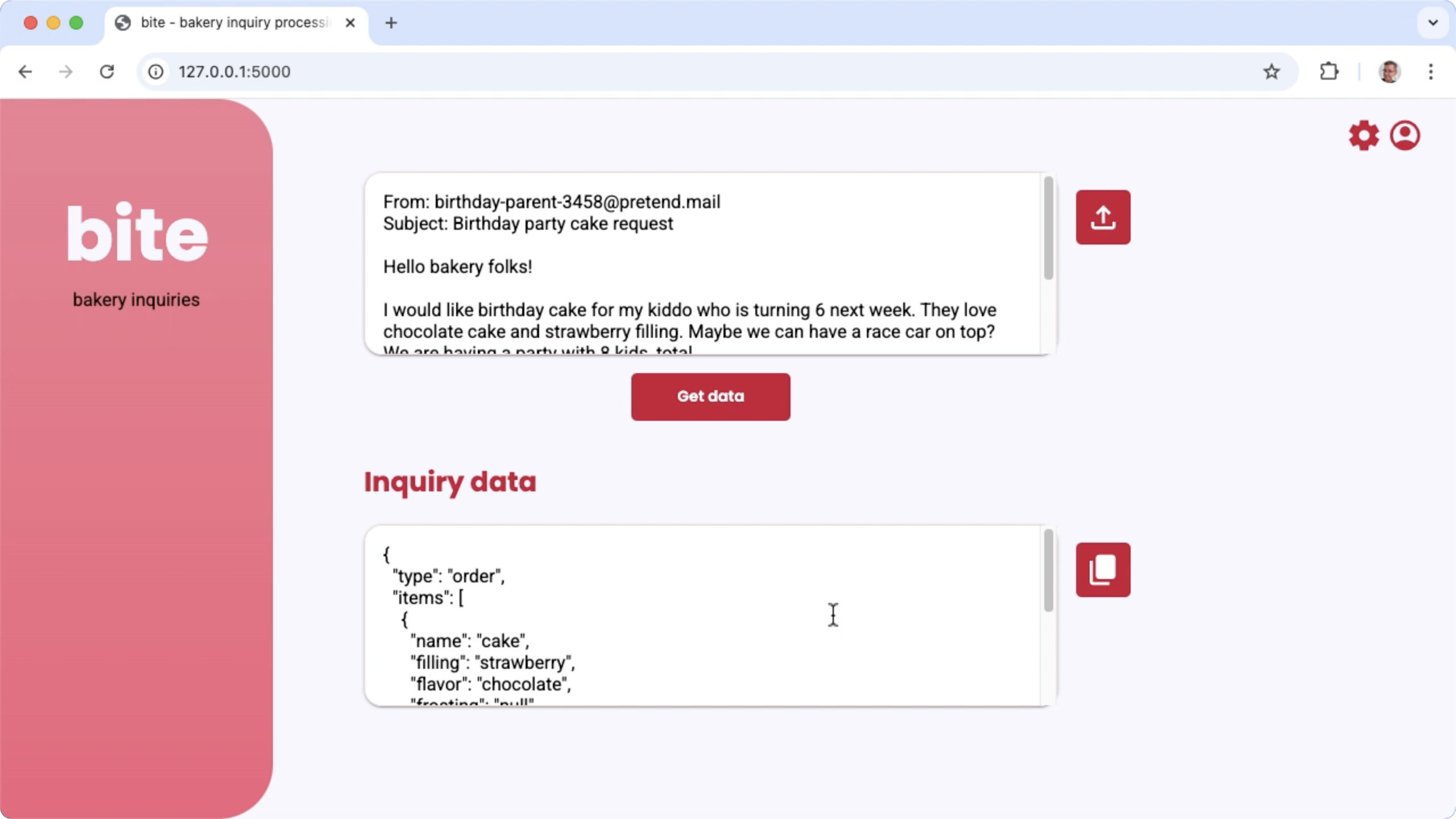
איור 1. ממשק המשתמש של Project לעיבוד פניות אימייל של מאפייה
דרישות חומרה
מריצים את תהליך ההתאמה במחשב עם יחידת עיבוד גרפי (GPU) או יחידת עיבוד טנסור (TPU), ועם מספיק זיכרון GPU או TPU כדי להכיל את המודל הקיים, בנוסף לנתוני ההתאמה. כדי להריץ את הגדרת האופטימיזציה בפרויקט הזה, צריך זיכרון GPU בנפח של כ-16GB, זיכרון RAM רגיל בנפח דומה ושטח דיסק בנפח של 50GB לפחות.
אפשר להריץ את החלק במדריך הזה שמתייחס לכוונון של מודל Gemma באמצעות סביבת Colab עם זמן ריצה של T4 GPU. אם אתם מפתחים את הפרויקט הזה במכונה וירטואלית ב-Google Cloud, אתם צריכים להגדיר את המכונה בהתאם לדרישות הבאות:
- חומרת GPU: נדרש NVIDIA T4 כדי להריץ את הפרויקט הזה (מומלץ NVIDIA L4 ומעלה)
- מערכת הפעלה: בוחרים באפשרות Deep Learning on Linux, ובאופן ספציפי באפשרות Deep Learning VM with CUDA 12.3 M124 עם מנהלי התקנים של תוכנת GPU שהותקנו מראש.
- גודל דיסק האתחול: הקצאת נפח דיסק של 50GB לפחות לנתונים, למודלים ולתוכנה התומכת.
הגדרת הפרויקט
ההוראות האלה מפרטות איך להכין את הפרויקט לפיתוח ולבדיקה. שלבי ההגדרה הכלליים כוללים התקנה של תוכנה נדרשת, שיבוט של הפרויקט ממאגר הקוד, הגדרה של כמה משתני סביבה, התקנה של ספריות Python ובדיקה של אפליקציית האינטרנט.
התקנה והגדרה
בפרויקט הזה נעשה שימוש ב-Python 3 ובסביבות וירטואליות (venv) כדי לנהל חבילות ולהריץ את האפליקציה. ההוראות הבאות להתקנה מיועדות למחשב מארח עם Linux.
כדי להתקין את התוכנה הנדרשת:
מתקינים את Python 3 ואת חבילת הסביבה הווירטואלית
venvל-Python:sudo apt update sudo apt install git pip python3-venv
שכפול הפרויקט
מורידים את קוד הפרויקט למחשב הפיתוח. כדי לאחזר את קוד המקור של הפרויקט, צריך תוכנת בקרת גרסאות של git.
כדי להוריד את קוד הפרויקט:
משכפלים את מאגר ה-Git באמצעות הפקודה הבאה:
git clone https://github.com/google-gemini/gemma-cookbook.gitאפשר גם להגדיר את מאגר ה-Git המקומי לשימוש ב-sparse checkout, כדי שיהיו לכם רק הקבצים של הפרויקט:
cd gemma-cookbook/ git sparse-checkout set Demos/business-email-assistant/ git sparse-checkout init --cone
התקנת ספריות Python
כדי לנהל חבילות ויחסי תלות של Python, מתקינים את ספריות Python עם venv סביבה וירטואלית של Python
מופעלת. חשוב להפעיל את הסביבה הווירטואלית של Python לפני שמתקינים ספריות Python באמצעות תוכנת ההתקנה pip. מידע נוסף על שימוש בסביבות וירטואליות של Python זמין במאמר בנושא Python venv.
כדי להתקין את ספריות Python:
בחלון המסוף, נכנסים לספרייה
business-email-assistant:cd Demos/business-email-assistant/מגדירים ומפעילים סביבה וירטואלית (venv) של Python בפרויקט הזה:
python3 -m venv venv source venv/bin/activateמתקינים את ספריות Python הנדרשות לפרויקט הזה באמצעות הסקריפט
setup_python:./setup_python.sh
הגדרה של משתני סביבה
כדי להריץ את הפרויקט הזה, צריך כמה משתני סביבה, כולל שם משתמש ב-Kaggle ואסימון Kaggle API. כדי להוריד את מודלי Gemma, צריך להיות לכם חשבון Kaggle ולבקש גישה למודלים. בפרויקט הזה, מוסיפים את שם המשתמש ב-Kaggle ואת טוקן ה-API של Kaggle לשני קבצים .env, שאפליקציית האינטרנט ותוכנת ההתאמה קוראות אותם בהתאמה.
כדי להגדיר את משתני הסביבה:
- פועלים לפי ההוראות בתיעוד של Kaggle כדי לקבל את שם המשתמש שלכם ב-Kaggle ואת מפתח הטוקן.
- כדי לקבל גישה למודל Gemma, פועלים לפי ההוראות שבקטע קבלת גישה ל-Gemma בדף הגדרת Gemma.
- יוצרים קובצי משתני סביבה לפרויקט על ידי יצירת קובץ טקסט
.envבכל אחד מהמיקומים הבאים בעותק של הפרויקט:email-processing-webapp/.env model-tuning/.env
אחרי שיוצרים את קובצי הטקסט
.env, מוסיפים את ההגדרות הבאות לשני הקבצים:KAGGLE_USERNAME=<YOUR_KAGGLE_USERNAME_HERE> KAGGLE_KEY=<YOUR_KAGGLE_KEY_HERE>
הפעלה ובדיקה של האפליקציה
אחרי שמשלימים את ההתקנה וההגדרה של הפרויקט, מריצים את אפליקציית האינטרנט כדי לוודא שההגדרה בוצעה בצורה נכונה. מומלץ לבצע את הבדיקה הזו כבדיקת בסיס לפני עריכת הפרויקט לשימוש אישי.
כדי להריץ ולבדוק את הפרויקט:
בחלון המסוף, נכנסים לספרייה
email-processing-webapp:cd business-email-assistant/email-processing-webapp/מריצים את האפליקציה באמצעות הסקריפט
run_app:./run_app.shאחרי שמפעילים את אפליקציית האינטרנט, קוד התוכנית מציג כתובת URL שאפשר לגלוש בה ולבדוק אותה. בדרך כלל הכתובת הזו היא:
http://127.0.0.1:5000/בממשק האינטרנט, לוחצים על הלחצן קבלת נתונים מתחת לשדה הקלט הראשון כדי ליצור תשובה מהמודל.
התגובה הראשונה מהמודל אחרי שמריצים את האפליקציה לוקחת יותר זמן, כי המודל צריך להשלים שלבי אתחול בהרצה הראשונה. בקשות הנחיות ופעולות יצירה חוזרות באפליקציית אינטרנט שכבר פועלת מסתיימות מהר יותר.
הרחבת האפליקציה
אחרי שהאפליקציה פועלת, אפשר להרחיב אותה על ידי שינוי ממשק המשתמש והלוגיקה העסקית שלה, כדי שהיא תתאים למשימות שרלוונטיות לכם או לעסק שלכם. אפשר גם לשנות את ההתנהגות של מודל Gemma באמצעות קוד האפליקציה, על ידי שינוי הרכיבים של ההנחיה שהאפליקציה שולחת למודל ה-AI הגנרטיבי.
האפליקציה מספקת למודל הוראות יחד עם נתוני הקלט מהמשתמש, כדי ליצור הנחיה מלאה למודל. אפשר לשנות את ההוראות האלה כדי לשנות את ההתנהגות של המודל, למשל לציין את שמות הפרמטרים ואת המבנה של ה-JSON שיווצר. דרך פשוטה יותר לשנות את ההתנהגות של המודל היא לספק לו הוראות או הנחיות נוספות לגבי התגובה שלו, למשל לציין שהתשובות שייווצרו לא יכללו עיצוב Markdown.
כדי לשנות את ההוראות בהנחיה:
- בפרויקט הפיתוח, פותחים את קובץ הקוד
business-email-assistant/email-processing-webapp/app.py. בקוד
app.py, מוסיפים הוראות נוספות לפונקציהget_prompt()::def get_prompt(): return """ Extract the relevant details of this request and return them in JSON code, with no additional markdown formatting:\n"""
בדוגמה הזו, הביטוי "with no additional markdown formatting" (בלי עיצוב נוסף של Markdown) מתווסף להוראות.
מתן הוראות נוספות בהנחיה יכול להשפיע מאוד על הפלט שנוצר, ודורש הרבה פחות מאמץ ליישום. כדאי לנסות את השיטה הזו קודם כדי לראות אם אפשר לקבל מהמודל את ההתנהגות הרצויה. עם זאת, יש מגבלות לשימוש בהוראות הנחיה כדי לשנות את ההתנהגות של מודל Gemma. בפרט, מגבלת האסימונים הכוללת של הקלט במודל, שהיא 8,192 אסימונים ב-Gemma 2, מחייבת אתכם לאזן בין הוראות מפורטות בהנחיה לבין גודל הנתונים החדשים שאתם מספקים, כדי שלא תחרגו מהמגבלה הזו.
שיפור המודל
הדרך המומלצת לגרום למודל Gemma להגיב בצורה אמינה יותר למשימות ספציפיות היא לבצע כוונון עדין של המודל. בפרט, אם רוצים שהמודל ייצור JSON עם מבנה ספציפי, כולל פרמטרים עם שמות ספציפיים, כדאי לשקול לכוון את המודל להתנהגות הזו. בהתאם למשימה שרוצים שהמודל יבצע, אפשר להשיג פונקציונליות בסיסית עם 10 עד 20 דוגמאות. בקטע הזה של המדריך מוסבר איך להגדיר ולהפעיל כוונון עדין של מודל Gemma למשימה ספציפית.
ההוראות הבאות מסבירות איך לבצע את פעולת הכוונון העדין בסביבת מכונה וירטואלית, אבל אפשר לבצע את פעולת הכוונון הזו גם באמצעות מחברת Colab שמשויכת לפרויקט הזה.
דרישות חומרה
דרישות המחשוב לצורך כוונון עדין זהות לדרישות החומרה של שאר הפרויקט. אפשר להריץ את פעולת ההתאמה בסביבת זמן ריצה של T4 GPU ב-Colab אם מגבילים את מספר הטוקנים של הקלט ל-256 ואת גודל האצווה ל-1.
הכנת הנתונים
לפני שמתחילים לכוונן מודל Gemma, צריך להכין נתונים לכווננון. כשמכווננים מודל למשימה ספציפית, צריך קבוצה של דוגמאות לבקשות ולתשובות. בדוגמאות האלה צריך להופיע טקסט הבקשה, בלי הוראות, וטקסט התשובה הצפוי. כדי להתחיל, כדאי להכין קבוצת נתונים עם כ-10 דוגמאות. הדוגמאות האלה צריכות לייצג מגוון רחב של בקשות ואת התגובות האידיאליות. חשוב לוודא שהבקשות והתשובות לא חוזרות על עצמן, כי זה עלול לגרום לתשובות של המודלים לחזור על עצמן ולא להתאים את עצמן בצורה הולמת לשינויים בבקשות. אם אתם מכווננים את המודל כדי ליצור פורמט של נתונים מובְנים, הקפידו שכל התשובות שאתם מספקים יהיו בדיוק בפורמט של פלט הנתונים שאתם רוצים. בטבלה הבאה מוצגות כמה רשומות לדוגמה ממערך הנתונים של דוגמת הקוד הזו:
| בקשה | תשובה |
|---|---|
| שלום Indian Bakery Central,\nרציתי לדעת אם יש לך במלאי 10 פנדות ו-30 בונדי לאדו?\n בנוסף, האם אתם מוכרים ציפוי וניל ועוגות בטעם שוקולד. אני מחפש גודל של 6 אינץ' | { "type": "inquiry", "items": [ { "name": "pendas", "quantity": 10 }, { "name": "bundi ladoos", "quantity": 30 }, { "name": "cake", "filling": null, "frosting": "vanilla", "flavor": "chocolate", "size": "6 in" } ] } |
| ראיתי את העסק שלך במפות Google. האם אתם מוכרים ג'לאבי וגולאב ג'אמון? | { "type": "inquiry", "items": [ { "name": "jellabi", "quantity": null }, { "name": "gulab jamun", "quantity": null } ] } |
טבלה 1. רשימה חלקית של מערך הנתונים של הכוונון עבור הכלי לחילוץ נתוני אימייל של המאפייה.
פורמט וטעינה של נתונים
אפשר לאחסן את נתוני ההתאמה בכל פורמט שנוח לכם, כולל רשומות במסד נתונים, קובצי JSON, קובצי CSV או קובצי טקסט פשוט, כל עוד יש לכם אפשרות לאחזר את הרשומות באמצעות קוד Python. הפרויקט הזה קורא קובצי JSON מהספרייה data למערך של אובייקטים מסוג מילון.
בדוגמה הזו של תוכנית להתאמת מודל, מערך הנתונים להתאמה נטען במודול model-tuning/main.py באמצעות הפונקציה prepare_tuning_dataset():
def prepare_tuning_dataset():
# collect data from JSON files
prompt_data = read_json_files_to_dicts("./data")
...
כמו שציינו קודם, אתם יכולים לאחסן את מערך הנתונים בפורמט שנוח לכם, כל עוד אתם יכולים לאחזר את הבקשות עם התשובות המשויכות ולחבר אותן למחרוזת טקסט שמשמשת כרשומה להתאמה.
הרכבת רשומות של שינוי הגדרות
במהלך תהליך הכוונון, התוכנית מרכיבה כל בקשה ותגובה למחרוזת אחת עם הוראות ההנחיה ותוכן התגובה. לאחר מכן, תוכנית ההתאמה יוצרת טוקניזציה של המחרוזת לצריכה על ידי המודל. אפשר לראות את הקוד להרכבת רשומה של התאמה אישית בפונקציה model-tuning/main.py של מודול prepare_tuning_dataset(), באופן הבא:
def prepare_tuning_dataset():
...
# prepare data for tuning
tuning_dataset = []
template = "{instruction}\n{response}"
for prompt in prompt_data:
tuning_dataset.append(template.format(instruction=prompt["prompt"],
response=prompt["response"]))
return tuning_dataset
הפונקציה מקבלת את הנתונים כקלט ומעצבת אותם על ידי הוספת מעבר שורה בין ההוראה לתשובה.
יצירת משקלים של מודלים
אחרי שנתוני ההתאמה מוכנים ונטענים, אפשר להריץ את תוכנית ההתאמה. תהליך ההתאמה של אפליקציית הדוגמה הזו משתמש בספריית Keras NLP כדי להתאים את המודל באמצעות Low Rank Adaptation, או טכניקת LoRA, כדי ליצור משקלים חדשים למודל. בהשוואה לכוונון מדויק מלא, השימוש ב-LoRA חוסך הרבה יותר זיכרון כי הוא מבצע קירוב של השינויים במשקלים של המודל. לאחר מכן תוכלו להוסיף את המשקלים המשוערים האלה למשקלים הקיימים של המודל כדי לשנות את ההתנהגות של המודל.
כדי להריץ את תהליך ההתאמה ולחשב משקלים חדשים:
בחלון המסוף, נכנסים לספרייה
model-tuning/.cd business-email-assistant/model-tuning/מריצים את תהליך ההתאמה באמצעות הסקריפט
tune_model:./tune_model.sh
תהליך ההתאמה נמשך כמה דקות, בהתאם למשאבי המחשוב הזמינים. כשהתוכנית מסיימת לפעול בהצלחה, היא כותבת קובצי משקל חדשים בפורמט הבא בספרייה model-tuning/weights:*.h5
gemma2-2b_inquiry_tuned_4_epoch##.lora.h5
פתרון בעיות
אם הכוונון לא הושלם, יש שתי סיבות אפשריות לכך:
- אין מספיק זיכרון או שהמשאבים מוצו: השגיאות האלה מתרחשות כשתהליך ההתאמה מבקש זיכרון שגדול מזיכרון ה-GPU או זיכרון ה-CPU הזמינים. חשוב לוודא שלא מפעילים את אפליקציית האינטרנט בזמן תהליך ההתאמה. אם אתם מבצעים אופטימיזציה במכשיר עם 16GB של זיכרון GPU, ודאו שהערך של
token_limitמוגדר ל-256 והערך שלbatch_sizeמוגדר ל-1. - מנהלי התקנים של GPU לא מותקנים או לא תואמים ל-JAX: תהליך הכוונון דורש שבמכשיר החישוב יהיו מותקנים מנהלי התקנים של חומרה שתואמים לגרסה של ספריות JAX. פרטים נוספים זמינים במאמר בנושא התקנת JAX.
פריסת מודל שעבר התאמה
תהליך ההתאמה יוצר משקלים מרובים על סמך נתוני ההתאמה ומספר האפוקים הכולל שהוגדר באפליקציית ההתאמה. כברירת מחדל, תוכנית הכוונון יוצרת 3 קובצי משקולות של המודל, אחד לכל תקופת כוונון. כל אפוקת כוונון עוקבת יוצרת משקלים שמשחזרים בצורה מדויקת יותר את התוצאות של נתוני הכוונון. אפשר לראות את שיעורי הדיוק של כל תקופה בתוצאות של תהליך הכוונון במסוף, באופן הבא:
...
8/8 ━━━━━━━━━━━━━━━━━━━━ 121s 195ms/step - loss: 0.5432 - sparse_categorical_accuracy: 0.5982
Epoch 2/3
8/8 ━━━━━━━━━━━━━━━━━━━━ 2s 194ms/step - loss: 0.3320 - sparse_categorical_accuracy: 0.6966
Epoch 3/3
8/8 ━━━━━━━━━━━━━━━━━━━━ 2s 192ms/step - loss: 0.2135 - sparse_categorical_accuracy: 0.7848
רצוי שאחוז הדיוק יהיה גבוה יחסית, בסביבות 0.80, אבל לא גבוה מדי או קרוב מאוד ל-1.00, כי זה אומר שהמשקלים קרובים מדי להתאמת יתר של נתוני ההתאמה. במצב כזה, המודל לא יפעל בצורה טובה בבקשות ששונות באופן משמעותי מדוגמאות ההתאמה. כברירת מחדל, סקריפט הפריסה בוחר את המשקלים של תקופת הלימוד 3, שבדרך כלל יש להם שיעור דיוק של כ-0.80.
כדי לפרוס את המשקלים שנוצרו באפליקציית האינטרנט:
בחלון המסוף, נכנסים לספרייה
model-tuning:cd business-email-assistant/model-tuning/מריצים את תהליך ההתאמה באמצעות הסקריפט
deploy_weights:./deploy_weights.sh
אחרי שמריצים את הסקריפט הזה, אמור להופיע קובץ *.h5 חדש בספרייה email-processing-webapp/weights/.
בדיקת המודל החדש
אחרי שפורסים את המשקלים החדשים באפליקציה, הגיע הזמן לנסות את המודל החדש. כדי לעשות את זה, מריצים מחדש את אפליקציית האינטרנט ומייצרים תשובה.
כדי להריץ ולבדוק את הפרויקט:
בחלון המסוף, נכנסים לספרייה
email-processing-webapp:cd business-email-assistant/email-processing-webapp/מריצים את האפליקציה באמצעות הסקריפט
run_app:./run_app.shאחרי שמפעילים את אפליקציית האינטרנט, קוד התוכנית מציג כתובת URL שאפשר לגשת אליה ולבדוק אותה. בדרך כלל זו הכתובת:
http://127.0.0.1:5000/בממשק האינטרנט, לוחצים על הלחצן קבלת נתונים מתחת לשדה הקלט הראשון כדי ליצור תשובה מהמודל.
התאמתם ופרסתם מודל Gemma באפליקציה. מתנסים עם האפליקציה ומנסים לקבוע את מגבלות יכולת היצירה של המודל שעבר כוונון למשימה שלכם. אם אתם נתקלים בתרחישים שבהם המודל לא פועל בצורה טובה, כדאי להוסיף חלק מהבקשות האלה לרשימת נתוני הדוגמאות להתאמה, על ידי הוספת הבקשה ומתן תגובה אידיאלית. אחר כך מריצים מחדש את תהליך הכוונון, פורסים מחדש את המשקלים החדשים ובודקים את הפלט.
מקורות מידע נוספים
מידע נוסף על הפרויקט הזה זמין במאגר הקוד של Gemma Cookbook. אם אתם צריכים עזרה בפיתוח האפליקציה או שאתם רוצים לשתף פעולה עם מפתחים אחרים, אתם יכולים להיכנס לשרת Google Developers Community Discord. בפלייליסט הסרטונים יש עוד פרויקטים של Build with Google AI.