
Odpowiadanie na zapytania klientów, w tym na e-maile, jest niezbędne w przypadku wielu firm, ale może szybko stać się przytłaczające. Modele sztucznej inteligencji (AI), takie jak Gemma, mogą ułatwić tę pracę.
Każda firma obsługuje zapytania, takie jak e-maile, w nieco inny sposób, dlatego ważne jest, aby móc dostosowywać technologie, takie jak generatywna AI, do potrzeb swojej firmy. Ten projekt rozwiązuje konkretny problem polegający na wyodrębnianiu informacji o zamówieniach z e-maili do piekarni i przekształcaniu ich w dane strukturalne, aby można je było szybko dodać do systemu obsługi zamówień. Korzystając z 10–20 przykładów zapytań i oczekiwanego wyniku, możesz dostosować model Gemma do przetwarzania e-maili od klientów, szybkiego odpowiadania na nie i integrowania z dotychczasowymi systemami biznesowymi. Ten projekt jest wzorcem aplikacji AI, który możesz rozszerzać i dostosowywać, aby wykorzystywać modele Gemma w swojej firmie.
Aby obejrzeć film z omówieniem projektu i sposobów jego rozszerzenia, w tym z informacjami od osób, które go stworzyły, zobacz film Asystent AI do tworzenia e-maili biznesowych – Tworzenie z Google AI. Kod tego projektu możesz też sprawdzić w repozytorium kodu Gemma Cookbook. W przeciwnym razie możesz rozpocząć rozszerzanie projektu, korzystając z tych instrukcji.
Przegląd
W tym samouczku dowiesz się, jak skonfigurować, uruchomić i rozszerzyć aplikację asystenta poczty e-mail dla firm utworzoną za pomocą Gemmy, Pythona i Flaska. Projekt udostępnia podstawowy interfejs użytkownika, który możesz zmodyfikować zgodnie ze swoimi potrzebami. Aplikacja została stworzona do wyodrębniania danych z e-maili klientów i przekształcania ich w strukturę dla fikcyjnej piekarni. Ten wzorzec aplikacji możesz wykorzystać w przypadku dowolnego zadania biznesowego, które wymaga wprowadzania i wyprowadzania tekstu.
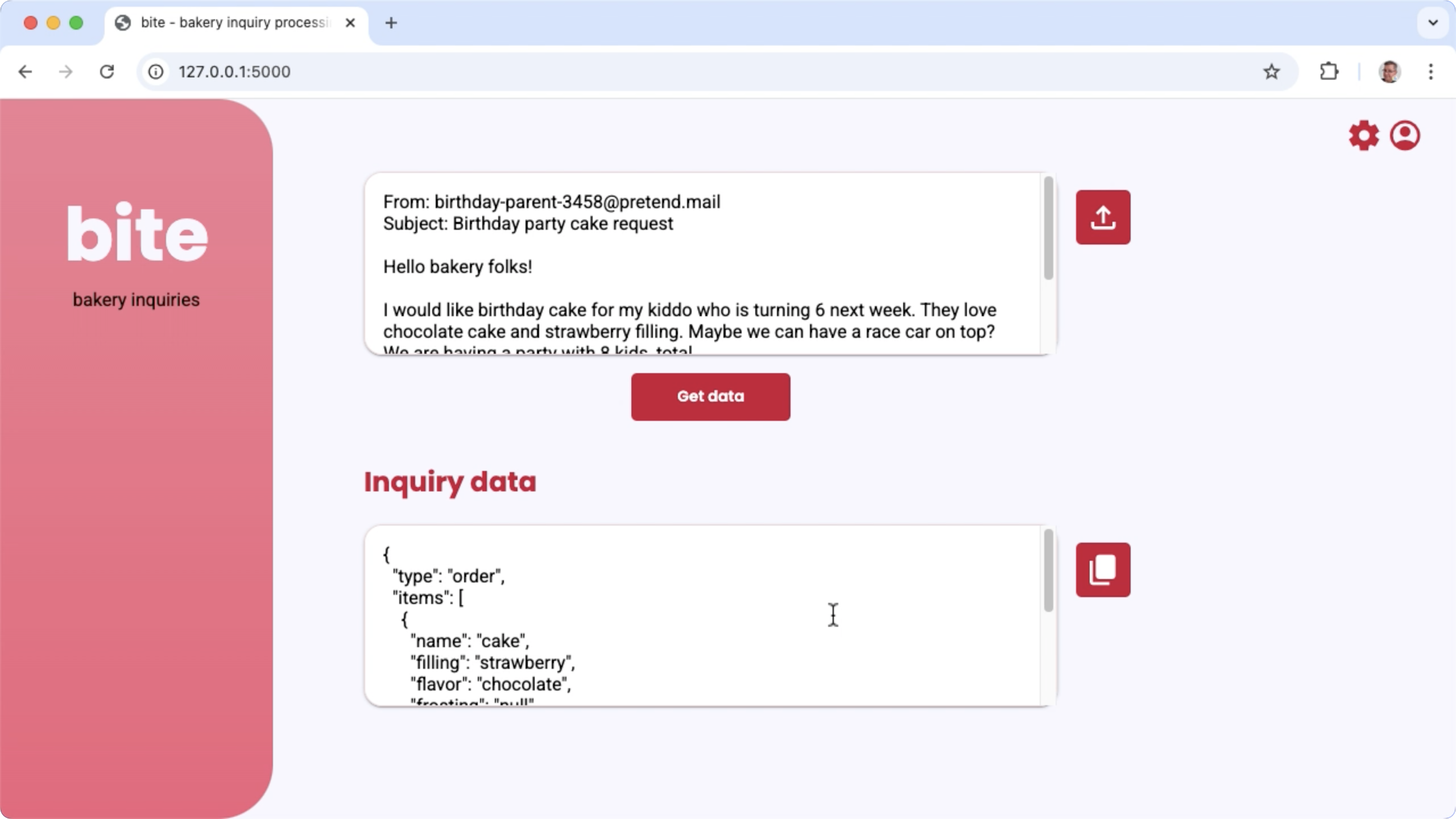
Rysunek 1. Interfejs projektu do przetwarzania zapytań e-mail dotyczących piekarni
Wymagania sprzętowe
Przeprowadź ten proces dostrajania na komputerze z procesorem graficznym (GPU) lub procesorem tensorowym (TPU) oraz wystarczającą ilością pamięci GPU lub TPU, aby pomieścić istniejący model i dane dostrajania. Aby uruchomić konfigurację dostrajania w tym projekcie, potrzebujesz około 16 GB pamięci GPU, mniej więcej tyle samo zwykłej pamięci RAM i co najmniej 50 GB miejsca na dysku.
Część tego samouczka dotyczącą dostrajania modelu Gemma możesz uruchomić w środowisku Colab z GPU T4. Jeśli tworzysz ten projekt na instancji maszyny wirtualnej w Google Cloud, skonfiguruj ją zgodnie z tymi wymaganiami:
- Sprzęt GPU: do uruchomienia tego projektu wymagany jest procesor NVIDIA T4 (zalecany jest NVIDIA L4 lub nowszy).
- System operacyjny: wybierz opcję Deep Learning on Linux, a konkretnie Deep Learning VM with CUDA 12.3 M124 z preinstalowanymi sterownikami oprogramowania GPU.
- Rozmiar dysku rozruchowego: udostępnij co najmniej 50 GB miejsca na dysku na dane, modele i oprogramowanie pomocnicze.
Konfigurowanie projektu
Te instrukcje przeprowadzą Cię przez proces przygotowania projektu do programowania i testowania. Ogólne kroki konfiguracji obejmują instalację wymaganego oprogramowania, sklonowanie projektu z repozytorium kodu, ustawienie kilku zmiennych środowiskowych, zainstalowanie bibliotek Pythona i przetestowanie aplikacji internetowej.
Instalowanie i konfigurowanie
Ten projekt korzysta z języka Python 3 i wirtualnych środowisk (venv) do zarządzania pakietami i uruchamiania aplikacji. Poniższe instrukcje instalacji są przeznaczone dla komputera hosta z systemem Linux.
Aby zainstalować wymagane oprogramowanie:
Zainstaluj Pythona 3 i
venvpakiet środowiska wirtualnego dla Pythona:sudo apt update sudo apt install git pip python3-venv
Klonowanie projektu
Pobierz kod projektu na komputer deweloperski. Aby pobrać kod źródłowy projektu, musisz mieć oprogramowanie do kontroli wersji git.
Aby pobrać kod projektu:
Sklonuj repozytorium Git za pomocą tego polecenia:
git clone https://github.com/google-gemini/gemma-cookbook.gitOpcjonalnie możesz skonfigurować lokalne repozytorium Git tak, aby korzystało z rzadkiego wyewidencjonowania, dzięki czemu będziesz mieć tylko pliki projektu:
cd gemma-cookbook/ git sparse-checkout set Demos/business-email-assistant/ git sparse-checkout init --cone
Instalowanie bibliotek Pythona
Zainstaluj biblioteki Pythona z aktywnym venvwirtualnym środowiskiem Pythonavenv, aby zarządzać pakietami i zależnościami Pythona. Przed zainstalowaniem bibliotek Pythona za pomocą instalatora pip aktywuj wirtualne środowisko Pythona. Więcej informacji o używaniu środowisk wirtualnych Pythona znajdziesz w dokumentacji Python venv.
Aby zainstalować biblioteki Pythona:
W oknie terminala przejdź do katalogu
business-email-assistant:cd Demos/business-email-assistant/Skonfiguruj i aktywuj środowisko wirtualne Pythona (venv) dla tego projektu:
python3 -m venv venv source venv/bin/activateZainstaluj wymagane biblioteki Pythona dla tego projektu za pomocą skryptu
setup_python:./setup_python.sh
Ustawianie zmiennych środowiskowych
Ten projekt wymaga do działania kilku zmiennych środowiskowych, w tym nazwy użytkownika Kaggle i tokena API Kaggle. Aby pobrać modele Gemma, musisz mieć konto Kaggle i poprosić o dostęp do nich. W tym projekcie dodasz nazwę użytkownika Kaggle i token interfejsu API Kaggle do 2 plików.env, które są odczytywane odpowiednio przez aplikację internetową i program dostrajania.
Aby ustawić zmienne środowiskowe:
- Uzyskaj nazwę użytkownika Kaggle i klucz tokena, postępując zgodnie z instrukcjami w dokumentacji Kaggle.
- Uzyskaj dostęp do modelu Gemma, postępując zgodnie z instrukcjami w sekcji Uzyskiwanie dostępu do Gemma na stronie Konfiguracja Gemma.
- Utwórz pliki zmiennych środowiskowych dla projektu, tworząc plik tekstowy
.envw każdej z tych lokalizacji w sklonowanej wersji projektu:email-processing-webapp/.env model-tuning/.env
Po utworzeniu plików tekstowych
.envdodaj do obu plików te ustawienia:KAGGLE_USERNAME=<YOUR_KAGGLE_USERNAME_HERE> KAGGLE_KEY=<YOUR_KAGGLE_KEY_HERE>
Uruchamianie i testowanie aplikacji
Po zakończeniu instalacji i konfiguracji projektu uruchom aplikację internetową, aby sprawdzić, czy została ona prawidłowo skonfigurowana. Zanim zaczniesz edytować projekt na własny użytek, przeprowadź ten test podstawowy.
Aby uruchomić i przetestować projekt:
W oknie terminala przejdź do katalogu
email-processing-webapp:cd business-email-assistant/email-processing-webapp/Uruchom aplikację za pomocą skryptu
run_app:./run_app.shPo uruchomieniu aplikacji internetowej kod programu wyświetla adres URL, pod którym możesz przeglądać i testować. Zwykle jest to:
http://127.0.0.1:5000/W interfejsie internetowym naciśnij przycisk Pobierz dane pod pierwszym polem wejściowym, aby wygenerować odpowiedź modelu.
Pierwsza odpowiedź modelu po uruchomieniu aplikacji zajmuje więcej czasu, ponieważ podczas pierwszego uruchomienia musi on wykonać kroki inicjowania. Kolejne żądania promptów i generowanie w przypadku już działającej aplikacji internetowej trwa krócej.
Rozszerzanie aplikacji
Po uruchomieniu aplikacji możesz ją rozbudować, modyfikując interfejs użytkownika i logikę biznesową, aby dostosować ją do zadań, które są istotne dla Ciebie lub Twojej firmy. Możesz też modyfikować działanie modelu Gemma za pomocą kodu aplikacji, zmieniając komponenty promptu, który aplikacja wysyła do modelu generatywnej AI.
Aplikacja przekazuje modelowi instrukcje wraz z danymi wejściowymi od użytkownika, tworząc pełny prompt dla modelu. Możesz zmodyfikować te instrukcje, aby zmienić zachowanie modelu, np. określić nazwy parametrów i strukturę generowanego kodu JSON. Prostszym sposobem na zmianę zachowania modelu jest podanie dodatkowych instrukcji lub wskazówek dotyczących odpowiedzi modelu, np. określenie, że wygenerowane odpowiedzi nie powinny zawierać formatowania Markdown.
Aby zmodyfikować instrukcje prompta:
- W projekcie deweloperskim otwórz plik z kodem
business-email-assistant/email-processing-webapp/app.py. W kodzie
app.pydodaj dodatkowe instrukcje do funkcjiget_prompt()::def get_prompt(): return """ Extract the relevant details of this request and return them in JSON code, with no additional markdown formatting:\n"""
W tym przykładzie do instrukcji dodano frazę „bez dodatkowego formatowania Markdown”.
Dodatkowe instrukcje w prompcie mogą mieć duży wpływ na wygenerowane dane wyjściowe i wymagają znacznie mniej wysiłku. Najpierw wypróbuj tę metodę, aby sprawdzić, czy model zachowuje się zgodnie z Twoimi oczekiwaniami. Jednak używanie instrukcji w prompcie do modyfikowania działania modelu Gemma ma swoje ograniczenia. W szczególności ogólny limit tokenów wejściowych modelu, który w przypadku Gemmy 2 wynosi 8192 tokeny, wymaga zachowania równowagi między szczegółowymi instrukcjami w prompcie a rozmiarem dostarczanych nowych danych, aby nie przekroczyć tego limitu.
Dostrój model
Dostrajanie modelu Gemma to zalecany sposób na zwiększenie jego niezawodności w przypadku konkretnych zadań. Jeśli chcesz, aby model generował kod JSON o określonej strukturze, w tym parametry o określonych nazwach, rozważ dostosowanie modelu do tego zachowania. W zależności od zadania, które ma wykonać model, możesz uzyskać podstawową funkcjonalność, używając od 10 do 20 przykładów. W tej części samouczka dowiesz się, jak skonfigurować i przeprowadzić dostrajanie modelu Gemma pod kątem konkretnego zadania.
Poniższe instrukcje wyjaśniają, jak przeprowadzić dostrajanie w środowisku maszyny wirtualnej. Możesz jednak wykonać tę operację dostrajania, korzystając z powiązanego notatnika Colab w tym projekcie.
Wymagania sprzętowe
Wymagania dotyczące mocy obliczeniowej w przypadku dostrajania są takie same jak wymagania sprzętowe w przypadku pozostałej części projektu. Operację dostrajania możesz przeprowadzić w środowisku Colab z GPU T4, jeśli ograniczysz liczbę tokenów wejściowych do 256, a rozmiar pakietu do 1.
Przygotuj dane
Zanim zaczniesz dostrajać model Gemma, musisz przygotować dane do dostrajania. Podczas dostrajania modelu do konkretnego zadania potrzebujesz zestawu przykładów żądań i odpowiedzi. Przykłady powinny zawierać tekst żądania bez żadnych instrukcji oraz oczekiwany tekst odpowiedzi. Na początek przygotuj zbiór danych zawierający około 10 przykładów. Przykłady powinny obejmować pełen zakres żądań i idealnych odpowiedzi. Upewnij się, że żądania i odpowiedzi nie są powtarzalne, ponieważ może to spowodować, że odpowiedzi modeli będą powtarzalne i nie będą się odpowiednio dostosowywać do zmian w żądaniach. Jeśli dostosowujesz model do generowania danych w formacie uporządkowanym, upewnij się, że wszystkie podane odpowiedzi są zgodne z formatem danych wyjściowych, którego oczekujesz. Poniższa tabela zawiera kilka przykładowych rekordów z zbioru danych użytego w tym przykładzie kodu:
| Żądanie | Odpowiedź |
|---|---|
| Hi Indian Bakery Central,\nDo you happen to have 10 pendas, and thirty bundi ladoos on hand? Czy sprzedajecie też lukier waniliowy i ciasta o smaku czekoladowym? Szukam rozmiaru 6 cali. | { "type": "inquiry", "items": [ { "name": "pendas", "quantity": 10 }, { "name": "bundi ladoos", "quantity": 30 }, { "name": "cake", "filling": null, "frosting": "vanilla", "flavor": "chocolate", "size": "6 in" } ] } |
| Widzę Twoją firmę w Mapach Google. Czy sprzedajecie jellabi i gulab jamun? | { "type": "inquiry", "items": [ { "name": "jellabi", "quantity": null }, { "name": "gulab jamun", "quantity": null } ] } |
Tabela 1. Częściowa lista zbioru danych dostrajania dla ekstraktora danych z e-maili piekarni.
Format danych i wczytywanie
Dane dostrajania możesz przechowywać w dowolnym wygodnym formacie, np. w rekordach bazy danych, plikach JSON, CSV lub zwykłych plikach tekstowych, o ile masz możliwość pobierania rekordów za pomocą kodu w Pythonie. Ten projekt odczytuje pliki JSON z katalogu data do tablicy obiektów słownikowych.
W tym przykładowym programie dostrajania zbiór danych do dostrajania jest wczytywany w module model-tuning/main.py za pomocą funkcji prepare_tuning_dataset():
def prepare_tuning_dataset():
# collect data from JSON files
prompt_data = read_json_files_to_dicts("./data")
...
Jak wspomnieliśmy wcześniej, możesz przechowywać zbiór danych w wygodnym formacie, o ile możesz pobrać żądania z powiązanymi odpowiedziami i złożyć je w ciąg tekstowy, który jest używany jako rekord dostrajania.
Tworzenie rekordów dostrajania
W procesie dostrajania program łączy każde żądanie i odpowiedź w jeden ciąg znaków z instrukcjami prompta i treścią odpowiedzi. Program dostrajania tokenizuje ciąg znaków, aby model mógł go przetworzyć. Kod do tworzenia rekordu dostrajania możesz zobaczyć w funkcji prepare_tuning_dataset() modułu model-tuning/main.py:
def prepare_tuning_dataset():
...
# prepare data for tuning
tuning_dataset = []
template = "{instruction}\n{response}"
for prompt in prompt_data:
tuning_dataset.append(template.format(instruction=prompt["prompt"],
response=prompt["response"]))
return tuning_dataset
Ta funkcja przyjmuje dane jako dane wejściowe i formatuje je, dodając znak podziału wiersza między instrukcją a odpowiedzią.
Generowanie wag modelu
Gdy dane dostrajania będą dostępne i wczytane, możesz uruchomić program dostrajania. Proces dostrajania tej przykładowej aplikacji wykorzystuje bibliotekę Keras NLP do dostrajania modelu za pomocą techniki adaptacji niskiego rzędu (LoRA) w celu wygenerowania nowych wag modelu. W porównaniu z pełnym dostrajaniem precyzyjnym LoRA jest znacznie bardziej oszczędna pod względem pamięci, ponieważ przybliża zmiany w wagach modelu. Możesz następnie nałożyć te przybliżone wagi na istniejące wagi modelu, aby zmienić jego działanie.
Aby przeprowadzić testowanie i obliczyć nowe wagi:
W oknie terminala przejdź do katalogu
model-tuning/.cd business-email-assistant/model-tuning/Uruchom proces dostrajania za pomocą skryptu
tune_model:./tune_model.sh
Proces dostrajania trwa kilka minut w zależności od dostępnych zasobów obliczeniowych. Po zakończeniu procesu dostrajania program zapisuje nowe pliki wagi w katalogu model-tuning/weights w tym formacie:*.h5
gemma2-2b_inquiry_tuned_4_epoch##.lora.h5
Rozwiązywanie problemów
Jeśli dostrajanie nie zostanie ukończone, prawdopodobne są 2 przyczyny:
- Brak pamięci lub wyczerpanie zasobów: te błędy występują, gdy proces dostrajania żąda pamięci przekraczającej dostępną pamięć GPU lub pamięć CPU. Upewnij się, że aplikacja internetowa nie jest uruchomiona podczas procesu dostrajania. Jeśli dostrajasz model na urządzeniu z 16 GB pamięci GPU, upewnij się, że parametr
token_limitma wartość 256, a parametrbatch_sizema wartość 1. - Sterowniki GPU nie są zainstalowane lub są niezgodne z JAX: proces dostrajania wymaga, aby na urządzeniu obliczeniowym były zainstalowane sterowniki sprzętowe zgodne z wersją bibliotek JAX. Więcej informacji znajdziesz w dokumentacji dotyczącej instalacji JAX.
Wdrażanie dostrojonego modelu
Proces dostrajania generuje wiele wag na podstawie danych dostrajania i całkowitej liczby epok ustawionej w aplikacji do dostrajania. Domyślnie program dostrajania generuje 3 pliki wag modelu, po jednym na każdą epokę dostrajania. Każda kolejna epoka dostrajania generuje wagi, które dokładniej odtwarzają wyniki danych dostrajania. W danych wyjściowych terminala procesu dostrajania możesz sprawdzić współczynniki dokładności dla każdej epoki:
...
8/8 ━━━━━━━━━━━━━━━━━━━━ 121s 195ms/step - loss: 0.5432 - sparse_categorical_accuracy: 0.5982
Epoch 2/3
8/8 ━━━━━━━━━━━━━━━━━━━━ 2s 194ms/step - loss: 0.3320 - sparse_categorical_accuracy: 0.6966
Epoch 3/3
8/8 ━━━━━━━━━━━━━━━━━━━━ 2s 192ms/step - loss: 0.2135 - sparse_categorical_accuracy: 0.7848
Chociaż chcesz, aby wskaźnik dokładności był stosunkowo wysoki, około 0,80, nie chcesz, aby był zbyt wysoki lub bardzo bliski 1,00, ponieważ oznacza to, że wagi są bliskie nadmiernemu dopasowaniu do danych dostrajania. W takim przypadku model nie będzie działać dobrze w przypadku żądań, które znacznie różnią się od przykładów dostrajania. Domyślnie skrypt wdrażania wybiera wagi epoki 3, które zwykle mają dokładność około 0, 80.
Aby wdrożyć wygenerowane wagi w aplikacji internetowej:
W oknie terminala przejdź do katalogu
model-tuning:cd business-email-assistant/model-tuning/Uruchom proces dostrajania za pomocą skryptu
deploy_weights:./deploy_weights.sh
Po uruchomieniu tego skryptu w katalogu email-processing-webapp/weights/ powinien pojawić się nowy plik *.h5.
Testowanie nowego modelu
Po wdrożeniu nowych wag w aplikacji możesz wypróbować nowo dostrojony model. Aby to zrobić, ponownie uruchom aplikację internetową i wygeneruj odpowiedź.
Aby uruchomić i przetestować projekt:
W oknie terminala przejdź do katalogu
email-processing-webapp:cd business-email-assistant/email-processing-webapp/Uruchom aplikację za pomocą skryptu
run_app:./run_app.shPo uruchomieniu aplikacji internetowej kod programu wyświetla adres URL, pod którym możesz przeglądać i testować aplikację. Zazwyczaj jest to adres:
http://127.0.0.1:5000/W interfejsie internetowym naciśnij przycisk Pobierz dane pod pierwszym polem wejściowym, aby wygenerować odpowiedź modelu.
Model Gemma został dostrojony i wdrożony w aplikacji. Eksperymentuj z aplikacją i spróbuj określić granice możliwości generowania dostosowanego modelu w przypadku Twojego zadania. Jeśli znajdziesz scenariusze, w których model nie działa dobrze, rozważ dodanie niektórych z tych próśb do listy przykładowych danych dostrajania. Wystarczy, że dodasz prośbę i podasz idealną odpowiedź. Następnie ponownie uruchom proces dostrajania, wdróż nowe wagi i przetestuj dane wyjściowe.
Dodatkowe materiały
Więcej informacji o tym projekcie znajdziesz w repozytorium kodu Gemma Cookbook. Jeśli potrzebujesz pomocy przy tworzeniu aplikacji lub chcesz współpracować z innymi deweloperami, odwiedź serwer Google Developers Community Discord. Więcej projektów z serii Build with Google AI znajdziesz na tej playliście.